作者:何律衡,编纂:李墨天
2024GTC大会上,黄仁勋右手B200,左手H100,理所当然地有了新人忘旧人:“咱们需求更大的GPU,假如不克不及更大,就把更多GPU组合在一起,酿成更大的虚构GPU。”
英伟达颁布的Blackwell架构的B200 GPU,亲手把网红显卡H100拍在了沙滩上。
根据黄仁勋的先容,B200理论上的功能可达20PFLOPS,是H100的五倍。相比H100的800亿范围,B200的晶体管范围高达2080亿。
普通来讲,晋升的最经常使用要领是接纳,用更高的密度在芯片里塞进更多晶体管。如所说:
上能够包容的晶体管数量,约莫每经由18个月到24个月便会增添一倍。
比方接纳7nm工艺的A100 GPU,芯片(Die)面积为826mm² ,内有542亿晶体管;接纳5nm(N4)工艺的H100,芯片面积减少为814mm² ,晶体管数目反而暴跌至800亿。
然而,B200在晶体管数目进步近三倍的同时,并没实用更进步前辈的3nm工艺,而是采用了和H100同样的5nm工艺。黄仁勋所说的“大”和“组合”,是字面意义上的:
从手艺道理看,B200实际上是把两块芯片“拼”成为了一个大芯片。
在英伟达的PPT演示里,两颗GPU从边缘“无缝粘合”在一起,面积X2的同时,算力翻倍。
1+1=2的要领看似简略粗犷,暗地里倒是一场在物理学边缘的冲锋与冒险。
1+1有时候不等于2
工场进步生产力有两种设施:一是扩建厂房,装进更多的生产线;二是进级生产线,在厂房面积稳定的情况下,增添生产线数目。
芯片公司始终以来都在接纳第二种方法:经由过程生产线立异(工艺制程),在无限的芯片面积里塞进更多晶体管,防止扩建厂房带来的房租本钱下跌。
但这类体式格局的局限性在于,生产线立异(工艺制程)对应的研发本钱越来越高,甚至有高过房租的趋向。H100接纳的5nm工艺,极可能便是GPU量产的极限制程,连续下探到3nm,极可能本钱上吃亏。
扩建厂房的确是一个设施,但放在芯片生产上,会遇到一个中国人很熟悉的题目:地皮提供无限。
每一颗芯片都是从12寸的硅(地皮)上“切”上去的,那末芯片(厂房)面积越大,每块晶圆能“切”进去的芯片就越少。
再考虑到和大面积芯片的散热题目(施工变乱),单个芯片本钱会成倍进步。
由此衍生出了第三种思绪:建一个一模同样的厂房,让两个厂房同时出产,既避开了本钱题目,又提高了出产服从。
这类要领听下来简略,但实际起来难于登天。
芯片在施行计较使命时需求履历两个阶段:和计较,数据传输破费时候过量,计较“空载”,就会造成算力的浪掷。就像两间厂房需求一个领班传播指导,领班在A厂房揭晓讲话时,B厂房的工人都在摸鱼。
这就致使在一块主板上10颗芯片,功能不但不会进步10倍,反而极可能连两倍都不到。
2011年,英伟达宣布了GTX590显卡,最大特点是在一个上装了两颗GPU芯片。
但在详细的游戏中,想同时挪用两颗GPU的算力,不但需求特地的支撑,功能也惟独单颗芯片的130%摆布。
缘故原由就在于,少量的算力被低效的数据传输浪费了。
为了解决产线工人趁着领班不在悲观怠工的题目,英伟达团队在2017年揭晓论文,提出了名为“可组合封装GPU”的架构,焦点在于将多颗GPU集成在同一个内。
传统的芯片封装是“先封再拼”,即两颗芯片封装终了,再用导线连贯。英伟达的计划是“先拼再封”,先把两颗芯片拼成一个大芯片,再封装到一路。
把芯片(厂房)之间的物理间隔缩减到0,领班通报指导,双方的工人同时进修贯彻,下降数据传输时候,完成1+1=2。
几个月后,老敌手AMD暗示论文谁不会写,刊发论文展示了4颗GPU集成在统一封装内的设想,声称其性能比其时的最强GPU还要高45.5%,而且coming soon。
但无论是英伟达仍是AMD,都没能把这个计划真正“soon”进去。
第一个让1+1=2的,是苹果。
苹果的超能力便是有钱
2022年,苹果宣布了M1 Ultra芯片,其最大特点是间接将两颗M1 Max芯片“粘合”在一起,酿成一张大芯片,业内戏称“胶水大法”。
1+1=2的意思正如苹果在新闻稿中所说:
M1 Ultra 在事情时依旧表现出一枚芯片的整体性,也会被所有软件识别为一枚残缺芯片,开发者无需重写代码就可以间接运用它的壮大功能。这在史上从无先例。
苹果以前,简直所有的“缝合”计划,都无奈解决芯片在连贯过程当中发生的消耗,使得功能每每“1+1<2”。M1 Ultra的暗地里,是一个名为UltraFusion的“缝合手艺”。
根据苹果民间的说法,Ultra Fusion由苹果与台积电配合研发。但从经验看,苹果发扬的最大感化,因此“手艺冠名费”的体式格局,报销了台积电的研发开销。
两颗芯片的缝合,焦点是要解决芯片间的数据传输题目。
为了完成“无缝粘合”,苹果用上了台积电最低廉、最进步前辈的封装手艺——第五代CoWoS-S。[2]
传统的传输体式格局是将两颗芯片封装在一块上,芯片之间的传输由引线解决。CoWoS计划在基板和芯片之间加了一层硅中介层,经由过程在硅中介层里布线,直接将两颗小芯片连贯起来,连贯密度是现有手艺的两倍。
这个手艺的关头就在于硅中介层,也是烧钱的本源。
硅中阶级本质上是一片硅晶圆,也便是“切”芯片的原材料。仅仅为了做连贯,就要另加一层硅晶圆的用度,这手笔生怕惟独苹果做得进去。
起初,英伟达在H100上采用了更成熟的CoWoS,本钱仍跨越4000美圆。苹果作为最后的试错者,本钱只会更高。
除了CoWoS,苹果的钱还烧在了“缝合”技术上[2]。
芯片创造的本色,是在硅晶圆上刻划庞杂电路。但在实践创造过程当中,电路不是间接刻在硅晶圆上的,而是先刻在一个掩膜版上,再经由过程光刻和刻蚀把电路“转移”到硅晶圆上。
英伟达昔时遇到的问题是,GPU芯片自身面积就大,一旦两颗GPU拼接,就会跨越失常掩膜版的巨细(H100的面积曾经靠近台积电5nm掩模版的极限),电路就无奈被完整地刻划。
苹果提出的解决计划是,1个掩膜版不敷,咱直接上四个吧。
经由过程四个掩膜版“缝合”,将电路刻划的面积增加到2500mm² ,是英伟达同期GPU的3倍多(815mm² )。
在芯片创造中,很大一部分红本就来自掩膜版制造。
掩膜版出产需求Mask Writer(掩膜版写入机),周详水平堪比。并且Mask Writer只在掩膜版制造时应用,每种芯片只做一次,难以摊薄本钱。
除此以外,因为Ultra Fusion用到了少量新技术比方连贯芯片的高纵横比硅通孔(TSV手艺,用于散热的新型非凝胶型热界面资料(TIM)等[2],台积电都是拿着发票找苹果报销的。
M1 Ultra宣布时,业界都没有正确本钱推算。不是研究员程度不到位,实在是手艺过于进步前辈,算不出来。
高科技家当关头题目不是手艺若何完成,而是谁来掏钱把论文试验室里的数据酿成能够量产产物。不知道看着M1 Ultra的拼接示意图,会不会长远影象袭击黄仁勋。
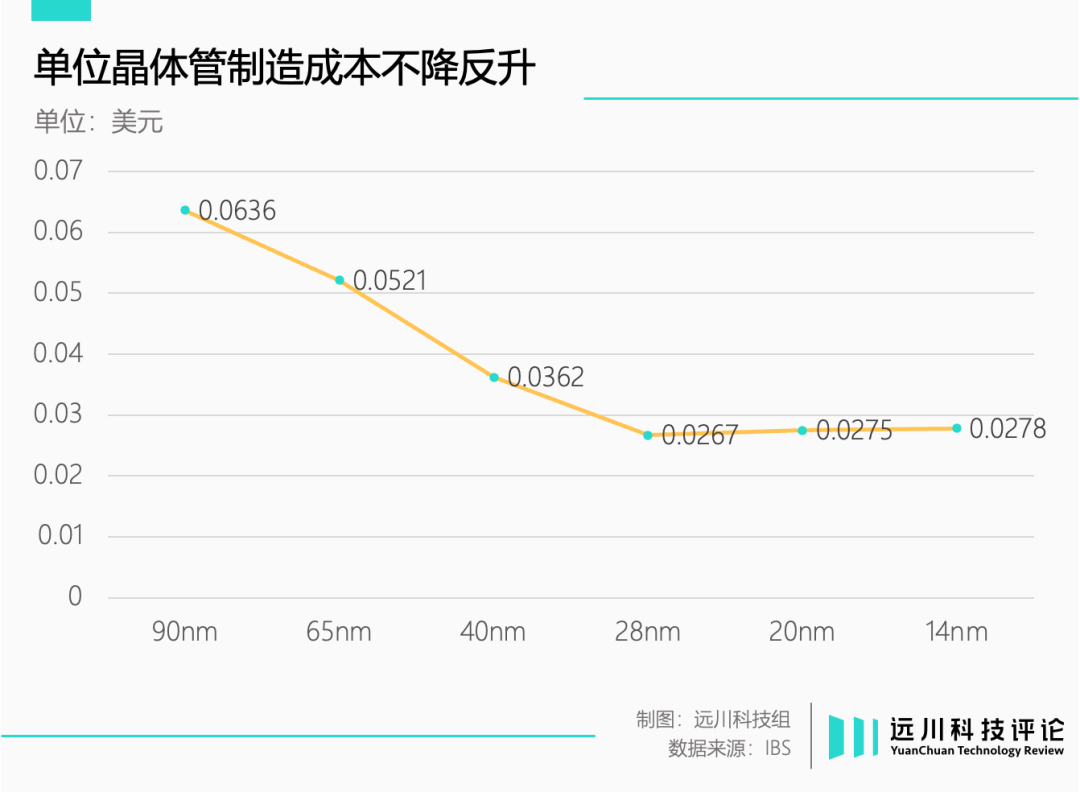
2009年,回归台积电的张忠谋请回曾经退休的蒋尚义。在后者领导下,台积电以“后闸手艺门路胜利逾越三星领先量产28nm工艺。但在研发过程当中,蒋尚义发明晶体管单位制造成本不降反升,制程进级晋升功能的性价比开端下降。
拿着张忠谋批的1亿美圆估算和400多人的团队,蒋尚义带队开端逾越摩尔规划”。
传统互联手艺下,传输速度曾经涉及天花板。蒋尚义开端测验考试一种新思路:
把两颗芯片放到一路封装,物理间隔缩短了,传输速率天然进步。为了差别于传统封装,蒋尚义将其命名为“”。
2011年失掉大厂定单凭仗CoWoS以及配合开辟的硅通孔(TSV手艺胜利将4个28nm FPGA芯片拼接在一起,推出了史上最大的FPGA芯片。
然而,大部分客户对CoWoS兴趣寥寥定单杯水车薪。
不是手艺不够好,实在是进步前辈封装太贵了。
老客户的高管在与蒋尚义共进午饭时直白暗示,CoWoS手艺很好,但“我只愿意为破费1美分/平方毫米其时的售价是7美分/平方毫米听说英伟达也是台积电CoWoS的第一批目的客户之一由于数据传输的瓶颈一直是搅扰GPU计较焦点题目。但听到台积电的报价后,英伟就地暗示手艺还能将就几年另外一方面进步前辈制程还在稳步推动进步前辈封装的理念显得过于超前究竟向导还在开卡罗拉,你就别急着换宝马是以进步前辈封装团队在台外部的一度边缘化以至当成老干部疗养院起初跳槽三星的梁孟觉得本人被调往进步前辈封装营业属于“下放”。
随后开端给CoWoS做减法,掏出了替换计划“InFO
紧接着,台积电遇到了能够靠一己之力转变供应商运气超等甲方:苹果。
2013年先后因为与三星在手机市场合作,苹果开端将芯片代工交由凭仗InFO计划,台积电在16nm工艺的基础上创造出了比三星14nm功能更强的A10,贡献了历代iPhone中第二轻浮的iPhone 7[5]。
有了苹果进步前辈封装营业敏捷盘活,并在2022年拿出了震惊业界的M1 Ultra芯片。2024年开年,这个攻坚十多年的“胶水大法”,又被用在了英伟达的新核弹B200上。英伟趁势拿下冠名权,将这项手艺命名为“NV-HBI
除了CoWoS,另一个天生式AI手艺HBM索求异样能够追溯到十年前。
CoWoS拿到赛灵思的第一笔定单时,蒋尚义大喜过望念头却让他有些哭笑不得:把四个老芯片拼在一路间接当做新产品加价不消本人开辟新产品了[3]。
在美国汗青博物馆的采访中,蒋尚义回想开辟手艺初志是解决功能瓶颈题目,在我看来立异并无被用在处所”。
科技反动很难推进手艺立异,反而是手艺立异让科技反动成为大概制造汗青的人永久无奈预见本人汗青历程中的坐标咱们未曾踏足的物理学边疆另有有数巨大立异尚在不为人知的角落。
参考文章:[1] NVIDIA Blackwell Architecture and B200/B100 Accelerators Announced: Going Bigger With Smaller Data,Anandtech[2] 苹果UltraFusion手艺,厦门云天[3] 蒋尚义万字自述,披露台积电的登顶之路,新芽进步前辈封装如许炼成世界杂志[5] 苹果iPhone 7 A10处理器的新封装在手艺贸易上都产生了伟大的影响,Yole Development[6] 苹果M1 Ultra解密:业内首个GPU裸片集成若何完成,集微网[7] Apple Will Help TSMC to Be in the Leading Position in the Next Era,utmel
视觉设想:疏睿,
2009年,回归台积电的张忠谋请回曾经退休的蒋尚义。在后者领导下,台积电以“后闸手艺门路胜利逾越三星领先量产28nm工艺。但在研发过程当中,蒋尚义发明晶体管单位制造成本不降反升,制程进级晋升功能的性价比开端下降。
拿着张忠谋批的1亿美圆估算和400多人的团队,蒋尚义带队开端逾越摩尔规划”。
传统互联手艺下,传输速度曾经涉及天花板。蒋尚义开端测验考试一种新思路:
把两颗芯片放到一路封装,物理间隔缩短了,传输速率天然进步。为了差别于传统封装,蒋尚义将其命名为“”。
2011年失掉大厂定单凭仗CoWoS以及配合开辟的硅通孔(TSV手艺胜利将4个28nm FPGA芯片拼接在一起,推出了史上最大的FPGA芯片。
然而,大部分客户对CoWoS兴趣寥寥定单杯水车薪。
不是手艺不够好,实在是进步前辈封装太贵了。
老客户的高管在与蒋尚义共进午饭时直白暗示,CoWoS手艺很好,但“我只愿意为破费1美分/平方毫米其时的售价是7美分/平方毫米听说英伟达也是台积电CoWoS的第一批目的客户之一由于数据传输的瓶颈一直是搅扰GPU计较焦点题目。但听到台积电的报价后,英伟就地暗示手艺还能将就几年另外一方面进步前辈制程还在稳步推动进步前辈封装的理念显得过于超前究竟向导还在开卡罗拉,你就别急着换宝马是以进步前辈封装团队在台外部的一度边缘化以至当成老干部疗养院起初跳槽三星的梁孟觉得本人被调往进步前辈封装营业属于“下放”。
随后开端给CoWoS做减法,掏出了替换计划“InFO
紧接着,台积电遇到了能够靠一己之力转变供应商运气超等甲方:苹果。
2013年先后因为与三星在手机市场合作,苹果开端将芯片代工交由凭仗InFO计划,台积电在16nm工艺的基础上创造出了比三星14nm功能更强的A10,贡献了历代iPhone中第二轻浮的iPhone 7[5]。
有了苹果进步前辈封装营业敏捷盘活,并在2022年拿出了震惊业界的M1 Ultra芯片。2024年开年,这个攻坚十多年的“胶水大法”,又被用在了英伟达的新核弹B200上。英伟趁势拿下冠名权,将这项手艺命名为“NV-HBI
除了CoWoS,另一个天生式AI手艺HBM索求异样能够追溯到十年前。
CoWoS拿到赛灵思的第一笔定单时,蒋尚义大喜过望念头却让他有些哭笑不得:把四个老芯片拼在一路间接当做新产品加价不消本人开辟新产品了[3]。
在美国汗青博物馆的采访中,蒋尚义回想开辟手艺初志是解决功能瓶颈题目,在我看来立异并无被用在处所”。
科技反动很难推进手艺立异,反而是手艺立异让科技反动成为大概制造汗青的人永久无奈预见本人汗青历程中的坐标咱们未曾踏足的物理学边疆另有有数巨大立异尚在不为人知的角落。
参考文章:[1] NVIDIA Blackwell Architecture and B200/B100 Accelerators Announced: Going Bigger With Smaller Data,Anandtech[2] 苹果UltraFusion手艺,厦门云天[3] 蒋尚义万字自述,披露台积电的登顶之路,新芽进步前辈封装如许炼成世界杂志[5] 苹果iPhone 7 A10处理器的新封装在手艺贸易上都产生了伟大的影响,Yole Development[6] 苹果M1 Ultra解密:业内首个GPU裸片集成若何完成,集微网[7] Apple Will Help TSMC to Be in the Leading Position in the Next Era,utmel