项目实施背景及可行性分析:
随着网络信息化技术的迅猛发展,身份验证的数字化、隐性化、便捷化显得越来越重要。语言作为人类的自然属性之一,说话人语言具有各自的生物特征,这使得通过语音分析进行说话人识别(Speaker Recognition, RS)成为可能。人的语音可以非常自然的产生,训练和识别时并不需要特别的输入设备,诸如个人电脑普遍配置的和到处都有的电话都可以作为输入设备,因此采用说话人语音进行说话人识别和其他传统的生物识别技术相比,具有更为简便、准确、经济及可扩展性良好等众多优势。
说话人识别的研究始于20世纪60年代,如今在特征提取、模型匹配、环境适应性等方面的研究已臻于成熟,各种算法也趋于稳定,说话人识别技术也正逐步进入到实用化阶段。因此,我们根据已有的特征提取算法基于工具搭建说话人识别系统是可行的。
项目目前进度:
系统具体方案及模型已搭建成功,并采用最小距离算法对系统进行说话人确认和说话人辨认的matlab仿真。 仿真结果显示,识别成功。
项目实施方案:
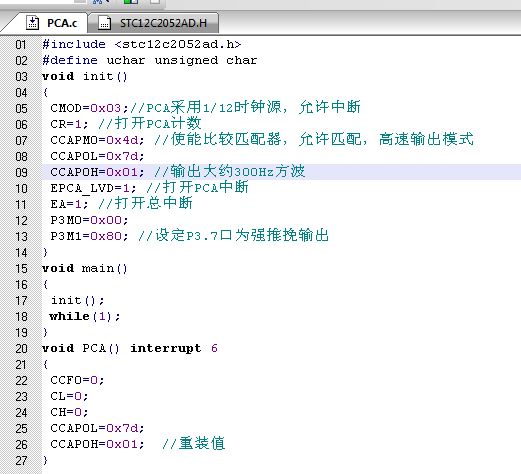
1 项目基本框图:

图1 说话人识别基本框图
图1是一个典型的说话人识别框图,包括训练和识别两个部分,训练又分为训练语音预处理、特征提取、训练建模、获取模型参数库四个过程,识别部分分为测试语音预处理、特征提取、模式匹配、判决输出四个过程。识别部分的模式匹配模块是将测试语音的特征矢量同模型库里的特征矢量进行距离匹配。
2 具体步骤
2.1 预处理
无论是训练语音信号还是测试语音信号在进行特征提取之前都要进行预处理。预处理包括预加重、分帧加窗、端点检测等。
(1)预加重:正常人的语音频率范围一般为40Hz~4000Hz,在求语音信号频谱时,频率越高相应的频谱成分越小,高频部分的频谱比低频部分的难求,预加重的目的是对语音信号的高频部分(大约800Hz以上)加以提升,是信号的频谱变得平坦,以便于频谱分析。预加重在语音信号数字化之后进行,用一阶数字来实现,公式为:
![]() (1)
(1)
其中,![]() 为预加重系数,它的值接近1,本项目取0.9375。
为预加重系数,它的值接近1,本项目取0.9375。
(2)分帧加窗:语音信号在很短的一个时间内可以认为是平稳的,所以我们在对其处理时,先对语音信号分帧,对每帧信号处理就相当于对固定特性的持续语音进行处理。一帧语音信号时长约10~30ms,本系统采样频率![]() 为22050Hz,所以,帧长N取256,帧移为128。.分帧后,对每帧信号采取加窗处理,为避免吉布斯效应,本系统采用长度为256的汉明窗,其表达式为:
为22050Hz,所以,帧长N取256,帧移为128。.分帧后,对每帧信号采取加窗处理,为避免吉布斯效应,本系统采用长度为256的汉明窗,其表达式为:
 (2)
(2)
其中![]() 表示该窗的中心坐标。
表示该窗的中心坐标。
(3)端点检测:端点检测的目的是从包含语音的一段信号中消除无声段的噪音和减少处理语音段的时间,确定出语音的起点以及终点。本系统通过短时能量的大小来区分清音段和浊音段。设第n帧语音信号![]() 的短时能量为
的短时能量为![]() ,其计算公式如下:
,其计算公式如下:
 (3)
(3)
清音的能量较小,浊音的能量较大。
在进行说话人语音端点检测时,首先根据背景噪声确定一个短时能量的门限阈值,由于我们获取说话人语音信息时是在安静环境下进行的的,所以仅根据此门限来确定语音的起点和终点也是可行的。但为了避免突发性的瞬时噪声(其短时能量有时比较大)的干扰,我们在此基础上,进行了进一步的限定,即,一旦检测到某帧的短时能量超过了门限,我们再继续检测接下来的32(经验值)帧,如果在这32帧里有3/4(经验值)的帧其短时能量都超过了门限,我们才确定最初检测的帧为语音起点,否则继续下一帧的检测。实验仿真证明,这种方法相比于单纯通过门限值判断能更好地确定语音的起始点和终点。