大白话用Transformer做BEV 3D object detection
时间:2022-08-25 02:30:00
秋名山车神作者@知乎(已授权)
来源丨https://zhuanlan.zhihu.com/p/517579299
极市平台编辑
如何利用车载环视相机收集的多个图像实现准确的3D目标检测是自动驾驶感知领域的重要课题之一。针对这个问题,传统的检测方案可以概括为:先用一个2D模型从各自的相机视角获取3D检测结果,然后通过后处理算法将每个视角的3D检测框投影到 ego frame 再组合在一起。这种做法简单有效,但除了模型学习之外,很难检测到相邻环视相机重叠部分被切断的物体,也很难实现与3的结合D点云传感器 (LiDAR) 数据级/特征级融合。
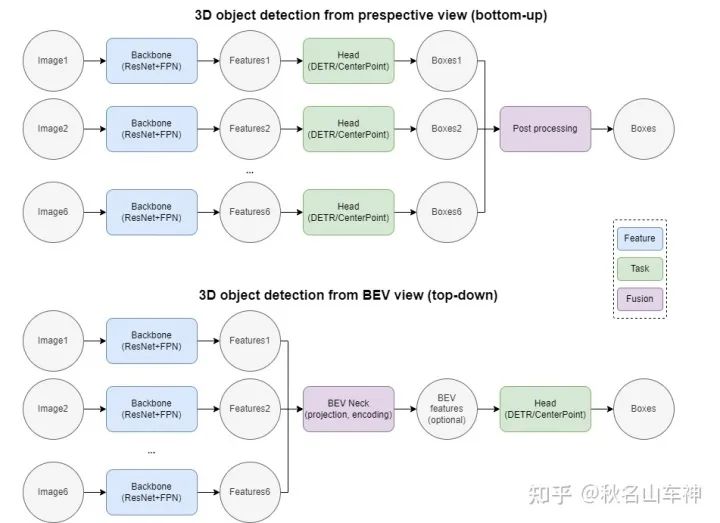
随着 Attention 机制在 Vision 在该领域的成功应用中,我们开始关注如何将多个应用于多个领域 Perspective view 的图片表征 (image representation) 转化为统一BEV view (Bird's Eye View, 鸟瞰图) 的场景表征 (scene representation),从而实现统一的3D目标检测。具体来说,传统的2D网络包含 Backbone 和 Head 特征提取和目标检测分别使用两个模块。具体来说,传统的2D网络包含 Backbone 和 Head 特征提取和目标检测分别使用两个模块。BEV 网络在两者之间增加了一个 BEV Neck,用于2D到3D的 BEV 特征投影和 BEV 从视角提取特征。本文试图盘点市场上几种主流 Transformer-based BEV 3D object detection 该方法侧重于如何从环视相机的角度有效提取BEV特征。
(PS:以下文章或多或少都是借鉴的 DETR [1] 对于不懂的学生,建议复习前两篇文章的解释 ——大白话用Transformer做object detection,实现无缝连接)
Feature point sampling
DETR3D [2] 将原本的DETR模型拓展到3D空间。具体来说:在 2D Image feature extraction 部分使用共享权重 ResNet FPN (output stride = 1/8, 1/16, 1/32, 1/64) 提取环视相机收集的6张图片的特点;3D Transformer decoder 部分,每个 object query 首先,通过一个子网络预测在现实世界中查询的物体3D坐标 (reference point),再利用相机内外参构成的坐标转换矩阵 (camera transformation matrices, 3x4) 将真实世界的3D坐标投影到环视相机2D像素坐标,并应用双线性插值采样各相机视角 PFN 同一级别的特征点(图像外投影的特征点用0填充),最后使用采样的特征点 6x4=24 特征点的平均值作为物体特征的更新object query。
Feature point sampling有很多优点:1。计算量小(毕竟只有24个特征);2.兼容性;FPN(有助于检测不同距离的物体);3.避免dense depth prediction(只需要预测 sparse object query 的3D坐标,不需要预测每张图片和像素的深度信息)。
Global cross-attention
无法直接用 3D object query 在 2D spatial features 查询匹配的原因之一是两者之间的不一致性:2D图中两点之间的坐标距离很难表达3D这两点在世界上的实际距离。为了将2D图像特征扩展到3D检测空间(方便 3D object query 查询匹配),PETR [3] 选择在 Positional embedding 改进:为2D特征图上的每个像素生成一个对应现实世界的3D坐标列表(2D图片上的一个点对应3D在现实世界中,以相机镜头为起点的射线 (camera ray),在这条射线上采样的N点列表是3D坐标集合),再通过MLP将坐标列表转化为坐标列表 3D Positional embedding。下图显示了前视相机的左、中、右三点和所有其他相机视角 3D Positional embedding 对比相似度,可以发现与这三点对应的现实世界三个射线夹角较小的区域相似度较高,证明了这两点D到3D转换是有效的。
有了 3D Positional embedding 原来的2D图像特征可升级为3D直接与空间特征 3D object query 查询匹配。PETR [3] 最大限度地保留Anchor DETR [4] 在 Transformer decoder 使用原始阶段 Global cross-attention,即每个 3D object query 要和6张环视图片的所有特征点做一遍相似度匹配。值得注意的是:1、可能是出于计算考虑,PETR [3] 不采用多尺度 FPN,相反,它只使用固定的大小 (stride =16) 根据作者的实验,BEV query(3D anchor points)需要高度(z轴)细分,现在有很多 pillar-based 检测方法不同。
Deformable cross-attention
BEVFormer [5] 继承自 Deformable DETR [6]与上述两项工作的主要区别在于:1.显式结构 BEV features(200x200分辨率,以车为中心的边长102.正方形面积4米);2.使用 Deformable cross-attention 从 image space aggregate spatial information 到 BEV query 中;3入多帧时序信息。
具体做法是:为 BEV space 的每个 feature point 定义一组 anchor heights (pillar-like query, four 3D reference points from -5 meters to 3 meters),投影回这四点 2D image space 采样特征点 (sampling 4 points around this reference point),采样获得的特征点和 BEV query 做 deformable attention。与前两种方法相比,Deformable cross-attention更灵活:它不仅采样一个点,而且不匹配六张图片的所有位置,而且查询reference point周边感兴趣区域 (RoI, region of interest)。仔细算一下,一个 pillar-like BEV query 对应4个不同的高度 reference points,每个 reference point 采样四个特点,deformable attention 还涉及8个heads,再加上3层 FPN (output stride = 1/16, 1/32, 1/64) 特征输出,最后一个 BEV query 实际上考察了4x4x8x3=384个特征点。
Lift-Splat
严格来说 Lift-Splat [7] 并不是基于 Attention 根据(预测)深度信息加权实现特征 perspective view 到 BEV 转换(值得注意的是,每张图片的每个特征点都需要预测其深度信息)。
具体来说,在 Lift 步骤:与 PETR [3] 类似,考虑2D图片上的一个点对应3D世界上有一条射线,所以N点可以在这条直线上采样(例图10个,实际41个);之后,网络需要预测这个特征点的深度信息 (distribution over depth,参考直线上的直方图),加权使用深度信息 (scale) 图像特征在同一位置 C(参考示例右侧,因为网络预测的深度在第三个 bin 因此,当深度较高时 D=3 时间特征最接近图片特征C,而其他深度特征较弱)。每2张图片D做同样的操作,可以生成类似平头金字塔的形状 (frustum) 的点云。在 Splat 第一步:先建一个 pillar-based BEV 视角特征图(200x200分辨率,覆盖以汽车为中心边长100米的方形区域),然后匹配上一步获得的6个平头金字塔点云中的每个点 (assign) 给最近的 pillar,最终 BEV space 上每个 pillar 特征是所有匹配的特征的和 (sum pooling)。基于此方法的后续改进包括:1。通过添加显式深度预测和监督 (explicit depth estimation supervision) 实现更准确 camera to BEV 特征转换 [8] (precomputation) 与GPU多线程并行池化 (specialized GPU kernel that parallelizes directly over BEV grids) 实现更快 camera to BEV 特征转换 因为 Splat 步骤采用 sum pooling 会粗暴地压缩一个BEV grid 的高度(Z轴)信息,故可以先将Lift步骤获得的点云渲染成立体特征 (pseudo voxel, feature shape = XYZC),再 reshape 成 XY(ZC),最后通过3x3卷积减少特征通道数 C [10]。
Future directions
仿照 Sparse RCNN [11] 的思路,在 BEV space 通过 RoIAlign 抽取环视相机的方式 perspective view 的2D特征(每个视角一个RoI,在图片外投影 proposal 用0填充否可行?类似的工作尚未阅读,需要进一步检查。
上面介绍的方法都是基于 query-based detection,出于计算量考虑 query 的数量一般比较少(大约500-1500左右),复杂场景下模型的recall表现还有待调研。
Transformer-based BEV 3D object detection模型是否必须依赖 perspective view 的预训练模型 (e.g., FCOS3D [12])?能否设计一种时间+空间、2D到3D、单任务到多任务、单传感器到多传感器的大规模自监督预训练?能否利用大规模仿真产生的数据?
参考链接:
[1] End-to-End Object Detection with Transformers https://arxiv.org/abs/2005.12872
[2] DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries https://arxiv.org/abs/2110.06922
[3] PETR: Position Embedding Transformation for Multi-View 3D Object Detection https://arxiv.org/abs/2203.05625
[4] Anchor DETR: Query Design for Transformer-Based Object Detection https://arxiv.org/abs/2109.07107
[5] BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers https://arxiv.org/abs/2203.17270
[6] Deformable DETR: Deformable Transformers for End-to-End Object Detection https://arxiv.org/abs/2010.04159
[7] Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D https://arxiv.org/abs/2008.05711
[8] Categorical Depth Distribution Network for Monocular 3D Object Detection https://arxiv.org/abs/2103.01100
[9] BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation https://bevfusion.mit.edu/assets/paper.pdf
[10] BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework https://arxiv.org/abs/2205.13790
[11] Sparse R-CNN: End-to-End Object Detection with Learnable Proposals https://arxiv.org/abs/2011.12450
[12] FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection [https://arxiv.org/abs/2104.10956]
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。
▲长按加微信群或投稿
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款
圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~


