Nginx Log And Analysis Project
时间:2023-12-27 12:37:02
nginx日志收集分析项目
- 1.搭建nginx web服务器
-
- 1.1 专有名词
-
- 1.1.1 集群
-
- 集群类型及介绍
- 集群的优点
- 1.1.2 负载均衡
-
- 负载均衡的概念
- 负载平衡的原理
- 1.1.3 高可用
- 1.1.4 异地多活 Multi-Site High Availability
- 1.1.5 DNS解析服务
- 1.1.6 问题
- 1.2 配置环境
-
- nginx配置
- 2. 搭建kafka 集群
-
- 2.1 kafka优势
- 2.2 kafka组件分析
- 2.3 数据的一致性
-
- 2.3.1 生产者数据的一致性
- 2.3.2 消费者数据的一致性
- 2.4 配置kafka
- 3.配置filebeat,测试consumer,producer
-
- 3.1 filebeat简介
- 3.2 filebeat布署
- 4.搭建zookeeper集群
-
- 4.1 配置zookeeper
- 4.2 创造生产者和消费者
- 5.python编写consumer,并写入MySQL
- 6. 编写监控脚本
- 7. 编制前端监控平台
- 未完待续...
1.搭建nginx web服务器
1.1 专有名词
1.1.1 集群
本质是为外界提供技术支持的程序集合。
简单地说,集群是指由高速通信网络组成的大型计算机服务系统。每个集群节点(即集群中的每台计算机)都是运行自己服务的独立服务器。这些服务器可以相互通信,协同为用户提供应用程序、系统资源和数据,并以单一的系统模式进行管理。当用户要求集群系统时,集群给用户一种单一独立的服务器的感觉,但实际上用户要求集群服务器。
举个例子:
打开谷歌和百度的页面看起来很简单。也许你认为你可以在几分钟内制作类似的网页,但事实上,这个页面的背后是成千上万的服务器集群协作的结果。
如果你想用一句话来描述集群,也就是说,一堆服务器合作做同样的事情,这些机器可能需要统一的协调和管理,可以分布在一个机房或世界各地的多个机房。
集群类型及介绍
负载均衡集群,简称LBC或者LB
高可用性集群,简称HAC
高性能计算集群,简称HPC
网格计算集群
(1)负载均衡集群
负载均衡集群为企业提供了更实用、更划算的系统架构解决方案。负载平衡集群可以在计算机集群中平均分配许多客户集中访问请求的负载压力。客户访问请求负载通常包括应用程序处理负载和网络流量负载。该系统非常适合使用同一组应用程序为大量用户提供服务的模式。每个节点可以承受一定的访问请求负载压力,并在每个节点之间动态分配访问请求,以实现负载平衡。
当负载平衡集群运行时,客户访问请求通常通过一个或多个前端负载平衡器分发给后端的一组服务器,以实现整个系统的高性能和高可用性。一般来说,高可用性集群和负载平衡集群使用类似的技术,或具有高可用性和负载平衡的特点。
负载均衡集群的作用如下:
共享用户访问请求和数据流量(负载均衡)
保持业务连续性,即7*24小时服务(高可用性)。
应用于Web以及数据库等服务器的业务
典型的负载均衡集群开源软件包括LVS,Nginx,Haproxy等等。如下图所示:
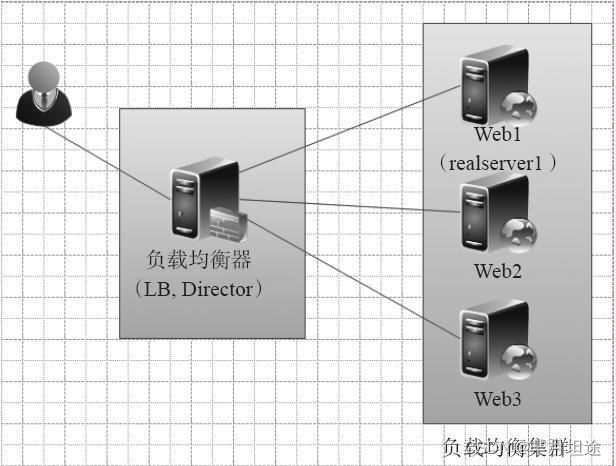
提示:
不同的业务会有几秒钟的切换时间,DB业务明显长于Web业务切换时间。
(2)高可用性集群
一般来说,当集群中的任何节点失效时,节点上的所有任务都会自动转移到其他正常节点。该过程不影响整个集群的运行。
当集群中的节点系统出现故障时,运行的集群服务将迅速响应,并将该系统的服务分配给集群中其他正在工作的系统。考虑到计算机硬件和软件的容错性,高可用性集群的主要目的是使集群的整体服务尽可能可用。若高可用性集群中的主节点出现故障,则在此期间将被备节点取代。备用节点通常是主节点的镜像。当它取代主节点时,它可以完全接管主节点(包括IP因此,集群系统环境对用户来说是一致的,即不会影响用户的访问。
高可用性集群使服务器系统的运行速度和响应速度尽可能快。它们经常使用多台机器上运行的冗余节点和服务来相互跟踪。如果某个节点失败,其替代品将在几秒钟或更短的时间内接管其职责。因此,对于用户来说,集群中的任何机器都不会受到影响(理论上)。
高可用性集群的作用如下:
当一台机器停机时,另一台机器接管停机机器IP提供服务的资源和服务资源。
常用于负载均衡不易实现的应用,如负载均衡器、主数据库、主存储对之间。
高可用性集群常用的开源软件包括Keepalived,Heartbeat等,其架构图如下图所示:
(3)高性能计算集群
高性能计算集群又称并行计算。通常,为了解决复杂的科学问题(天气预报、石油勘探、核反应模拟等),高性能计算集群涉及集群开发的并行应用。高性能计算集群就像一台超级计算机,由数十到数万台独立服务器组成,并在公共信息传输层上进行通信,并行运行应用程序。在生产环境中,任务实际上是切成蛋糕,然后发送到集群节点计算,计算后返回结果,然后继续计算新的任务。
(4)网格计算集群
因为很少用,在这里稍微用一点
特别提示:
在互联网网站中,负载均衡集群和高可用性集群更为常用
集群的优点
(1)高性能
一些重要的计算密集型应用(如天气预报、核试验模拟等),要求计算机具有较强的计算处理能力。以世界上现有的技术,即使是大型机器,其计算能力也有限,很难单独完成任务。因为计算时间可能相当长,也许几天,甚至几年或更长。因此,对于这类复杂的计算业务,便使用了计算机集群技术,集中几十上百台,甚至成千上万台计算机进行计算。
假如你配一个LNMP在环境中,每次只需服务10个并发请求,单个服务器肯定会比多个服务器集群更快。只有当并发或总请求数量超过单个服务器的承载能力时,服务器集群才会显示出优势。
(2)价格有效性
一般来说,一套系统集群架构只需要几台或几十台服务器主机。它比价值数百万元的特殊超级计算机便宜得多。在满足相同性能需求的情况下,使用计算机集群架构比具有相同计算能力的大型计算机具有更高的性价比。
早期的淘宝,支付宝的数据库等核心系统就是使用上百万元的小型机服务器。后来,由于使用维护成本过高,设备扩展成本翻倍,甚至成为扩展瓶颈,人员维护也非常困难,最终使用PC以服务器集群替换为例,将数据库系统从小机器结合起来Oracle数据库迁移MySQL结合开源数据库PC服务器上来。不仅降低了成本,而且更容易扩展和维护。
(3)可伸缩性
当服务负荷和压力增加时,简单地扩展集群系统以满足需求,而不会降低服务质量。
通常,如果硬件设备想要扩展性能,就必须增加新的CPU如果存储设备不能添加,我们必须购买更高性能的服务器。以我们目前的服务器为例,可以添加的设备总是有限的。如果采用集群技术,只需将新的单个服务器添加到现有的集群架构中。从访问客户的角度来看,系统服务在连续性和性能上几乎没有变化。系统在不知不觉中升级,增加了访问能力,轻松扩展。集群系统中的节点数量可以增加到数千甚至数万个,其可伸缩性远远超过单台超级计算机。
(4)高可用性
单一的计算机系统总是面临设备损坏等问题CPU,内存、主板、电源、硬盘等。板、电源、硬盘等,计算机系统就可能停机,无法正常提供服务。在集群系统中,虽然一些硬件和软件仍然会出现故障,但整个系统的服务可以是7*24小时可用。集群架构技术可以使系统在几个硬件设备出现故障时继续工作,从而最大限度地减少系统的停机时间。在提高系统可靠性的同时,集群系统也大大降低了系统故障带的业务损失,目前几乎100%的互联网网站都要求7*24小时提供服务。
(5)透明性
多个独立计算机组成的松耦合集群系统构成一个虚拟服务器。用户或客户端程序访问集群系统时,就像访问一台高性能,高可用的服务器一样,集群中一部分服务器的上线,下线不会中断整个系统服务,这对用户也是透明的。
(6)可管理性
整个系统可能在物理上很大,但其实容易管理,就像管理一个单一映像系统一样。在理想状况下,软硬件模块的插入能做到即插即用。
(7)可编程性
易于扩展,在集群系统上,容易开发及修改各类应用程序。
1.1.2 负载均衡
负载均衡的概念
负载均衡是高可用网络基础架构的关键组件,通常用于将工作负载分布到多个服务器来提高网站、应用、数据库、或其他服务的性能和可靠性。
一个没有负载均衡的web架构:
在这里用户是直连到 web 服务器,如果这个服务器宕机了,那么用户自然也就没办法访问了。另外,如果同时有很多用户试图访问服务器,超过了其能处理的极限,就会出现加载速度缓慢或根本无法连接的情况。
而通过在后端引入一个负载均衡器和至少一个额外的 web 服务器,可以缓解这个故障。通常情况下,所有的后端服务器会保证提供相同的内容,以便用户无论哪个服务器响应,都能收到一致的内容。
从图里可以看到,用户访问负载均衡器,再由负载均衡器将请求转发给后端服务器。在这种情况下,单点故障现在转移到负载均衡器上了。这里又可以通过引入第二个负载均衡器来缓解,但在讨论之前,我们先探讨下负载均衡器的工作方式。
负载均衡的原理
负载均衡器可以处理什么样的请求?
负载均衡器的管理员能主要为下面四种主要类型的请求设置转发规则:
HTTP
HTTPS
TCP
UDP
负载均衡器如何选择要转发的后端服务器?
负载均衡器一般根据两个因素来决定要将请求转发到哪个服务器。首先,确保所选择的服务器能够对请求做出响应,然后根据预先配置的规则从健康服务器池(healthy pool)中进行选择。
因为,负载均衡器应当只选择能正常做出响应的后端服务器,因此就需要有一种判断后端服务器是否「健康」的方法。为了监视后台服务器的运行状况,运行状态检查服务会定期尝试使用转发规则定义的协议和端口去连接后端服务器。如果,服务器无法通过健康检查,就会从池中剔除,保证流量不会被转发到该服务器,直到其再次通过健康检查为止。
负载均衡算法
负载均衡算法决定了后端的哪些健康服务器会被选中。几个常用的算法:
Round Robin(轮询):为第一个请求选择列表中的第一个服务器,然后按顺序向下移动列表直到结尾,然后循环。
Least Connections(最小连接):优先选择连接数最少的服务器,在普遍会话较长的情况下推荐使用。
Source:根据请求源的 IP 的散列(hash)来选择要转发的服务器。这种方式可以一定程度上保证特定用户能连接到相同的服务器。
如果你的应用需要处理状态而要求用户能连接到和之前相同的服务器。可以通过 Source 算法基于客户端的 IP 信息创建关联,或者使用粘性会话(sticky sessions)。
最后,想要解决负载均衡器的单点故障问题,可以将第二个负载均衡器连接到第一个上,从而形成一个集群。
当主负载均衡器发生了故障,就需要将用户请求转到第二个负载均衡器。因为 DNS 更改通常会较长的时间才能生效,因此需要能灵活解决 IP 地址重新映射的方法,比如浮动 IP(floating IP)。这样域名可以保持和相同的 IP 相关联,而 IP 本身则能在服务器之间移动。
一个使用浮动 IP 的负载均衡架构示意图:
原文: What is Load Balancing?
1.1.3 高可用
一、什么是高可用
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
假设系统一直能够提供服务,我们说系统的可用性是100%。
如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。
很多公司的高可用目标是4个9,也就是99.99%,这就意味着,系统的年停机时间为8.76个小时。
百度的搜索首页,是业内公认高可用保障非常出色的系统,甚至人们会通过http://www.baidu.com 能不能访问来判断“网络的连通性”,百度高可用的服务让人留下啦“网络通畅,百度就能访问”,“百度打不开,应该是网络连不上”的印象,这其实是对百度HA最高的褒奖。
二、如何保障系统的高可用
我们都知道,单点是系统高可用的大敌,单点往往是系统高可用最大的风险和敌人,应该尽量在系统设计的过程中避免单点。方法论上,高可用保证的原则是“集群化”,或者叫“冗余”:只有一个单点,挂了服务会受影响;如果有冗余备份,挂了还有其他backup能够顶上。
保证系统高可用,架构设计的核心准则是:冗余。
有了冗余之后,还不够,每次出现故障需要人工介入恢复势必会增加系统的不可服务实践。所以,又往往是通过“自动故障转移”来实现系统的高可用。
接下来我们看下典型互联网架构中,如何通过冗余+自动故障转移来保证系统的高可用特性。
参考链接–高可用
1.1.4 异地多活 Multi-Site High Availability
参考链接1–异地多活
参考链接2–异地多活
1.1.5 DNS解析服务
参考链接–DNS
1、浏览器的缓存
2、没有的话去本地hosts文件
--linux /etc/hosts文件 建立ip地址和域名的映射关系
[root@nginx-kafka01 system]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.2.192 nginx-kafka01
192.168.2.113 nginx-kafka02
192.168.2.73 nginx-kafka03
[root@nginx-kafka01 system]#
3、找本地域名服务器 --linux(/etc/resolv.conf)
[root@nginx-kafka01 system]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 114.114.114.114
[root@nginx-kafka01 system]#
1.1.6 问题
客户端如何访问服务端?
1.访问ip地址和端口来访问
2.通过域名解析到ip地址进行访问
www.sc.com DNS可以解析成多个ip地址 一般来说会轮询方式解析成各个ip。但是如果其中一台服务器挂掉了 DNS不会立马将这个ip地址去掉 还是会解析成挂掉的ip可能会造成访问失败 虽然客户端有重试 但是还是会影响用户体验。
如何进行测试的?
测试时 可以直接访问nginx web ,也可以访问代理服务器nginx然后转接至服务器
反向代理的优势
在应用web前面加反向代理 代理服务器。安全性也会高一点
负载均衡控制也会容易很多
正向代理:代理客户机
如:VPN virtual personal network
反向代理机之间交流
keepalived:基于vrrp协议
反向代理机,使用keeplived双vip互为主备机做高可用,提高资源利用率 但是高可用没有变化;代理服务机会根据自己的healthy pool,周期的向服务器发起健康检测,只有通过检测才会留在healthy pool中。
www.sc.com 解析成两个虚拟ip 1.5 1.6 一个nginx1代理机挂掉,则其vip 1.5飘向代理机nginx2 即其有1.5 1.6两个虚拟ip地址 提高了资源利用率。
git、github、gitlab区别?
git:https://git-scm.com/
Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
github:https://github.com/
gitlab:https://about.gitlab.com/
增加几个kafka集群、filebeat集群会出现什么问题?
可以通过考虑:CPU 、MEMORY、 网路带宽、 磁盘io等方面来监控集群,一旦出现问题立马解决。
top --查看内存、cpu使用其概况
dstat -am --查看磁盘IO读写情况
[root@mahaoliang ~]# dstat -am
----total-cpu-usage---- -dsk/total- -net/total- —paging-- —system-- ------memory-usage-----
usr sys idl wai hiq siq| read writ| recv send| in out | int csw | used buff cach free
0 0 99 0 0 0|7219B 3923B| 0 0 | 0 0 | 85 178 | 228M 2104k 543M 1047M
什么是消息中间件?
面向消息的系统(消息中间件)是在分布式系统中完成消息的发送和接收的基础软件。消息中间件也可以称消息队列,是指用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信
消息中间件有那些?
当前业界比较流行的开源消息中间件包括:ActiveMQ、RabbitMQ、RocketMQ、Kafka、ZeroMQ等,其中应用最为广泛的要数RabbitMQ、RocketMQ、Kafka 这三款。Redis在某种程度上也可以是实现类似 “Queue” 和“ Pub/Sub” 的机制,严格意义上不算消息中间件。
MQ:message queue 消息队列
链接–消息中间件
什么是ELK?
elasticsearch相当于kafka、logstash相当于filebeat、kibana主要用于可视化
filebeat–日志收集软件
链接–ELK
消费者如何从kafka集群获取数据?
消费者如何从kafka中消费数据?
什么是flume?日志收集的软件?
链接–flume
flume和kafka的区别?
flume和kafka的区别?
ELK和你的项目的区别?
链接–ELK和kafka的区别?
1.2 配置环境
配置静态ip地址
1、# 配置ifcfg-ens33文件
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
[root@localhost ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=none # 启动协议
NAME=ens33 # 网卡名字
DEVICE=ens33 # 设备名字
ONBOOT=yes # 自启
IPADDR=192.168.2.192 # ip地址
NETMASK=255.255.255.0 # 子网掩码
GATEWAY=192.168.2.1 # 网关 gateway:默认路由
DNS1=114.114.114.114 # 域名解析
# 配置本地域名解析服务文件
[root@localhost ~]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 114.114.114.114
[root@localhost ~]#
2、# 查看ip地址
[root@localhost ~]# ip a
1: lo: ,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: ,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:96:3e:44 brd ff:ff:ff:ff:ff:ff
inet 192.168.2.192/24 brd 192.168.2.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe96:3e44/64 scope link
valid_lft forever preferred_lft forever
[root@localhost ~]#
3、# 查看网关
[root@localhost ~]# ip r
default via 192.168.2.1 dev ens33 proto static metric 100
192.168.2.0/24 dev ens33 proto kernel scope link src 192.168.2.192 metric 100
[root@localhost ~]#
4、刷新启动服务 关闭启动ens33网卡
service network restart
ifdown ens33
ifup ens33
修改主机名
5、三台主机都修改
配置/etc/hostname文件
或者
[root@#localhost ~]# hostnamectl set-hostname nginx-kafka01
配置域名解析服务
6、三台主机都配置
[root@nginx-kafka01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.2.192 nginx-kafka01
192.168.2.113 nginx-kafka02
192.168.2.73 nginx-kafka03
[root@nginx-kafka01 ~]#
其他配置
7、安装基本软件
yum install wget lsof vim -y
8、安装时间同步服务
yum -y install chrony
systemctl enable chronyd 设置开机自启 disable 关闭开机自启
systemctl start chronyd
设置时区:
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
9、关闭防火墙
关闭防火墙:
[root@nginx-kafka01 ~]# systemctl stop firewalld
[root@nginx-kafka01 ~]# systemctl disable firewalld
关闭selinux:
vim /etc/selinux/config
SELINUX=disabled
或
[root@nginx-kafka01 system]# sed -i '/^SELINUX=/ s/permissive/disabled/' /etc/selinux/config
selinux是linux系统内核里一个跟安全相关的子系统
规则很繁琐 一般日常工作里都是关闭的
selinux关闭 需要重启机器
查看是否生效:
[root@nginx-kafka01 system]# getenforce
Disabled # 已关闭selinux
[root@nginx-kafka01 system]#
nginx配置
1、# 下载eple源
[root@nginx-kafka01 system]# yum install epel-release -y
2、# 下载nginx
[root@nginx-kafka01 system]# yum install nginx -y
3、# 设置开机自启
[root@nginx-kafka01 system]# systemctl enable nginx
4、修改nginx配置文件
# nginx服务的配置文件 使用yum安装的nginx主配置文件nginx.conf
[root@nginx-kafka01 multi-user.target.wants]# cd /etc/nginx
[root@nginx-kafka01 nginx]# ls
conf.d koi-utf scgi_params
default.d koi-win scgi_params.default
fastcgi.conf mime.types uwsgi_params
fastcgi.conf.default mime.types.default uwsgi_params.default
fastcgi_params nginx.conf win-utf
fastcgi_params.default nginx.conf.default
[root@nginx-kafka01 nginx]#
# 虚拟主机配置文件
cd /etc/nginx/conf.d
vim sc.conf
server {
listen 80 default_server;
server_name www.sc.com;
root /usr/share/nginx/html;
access_log /var/log/nginx/sc/access.log main;
location / {
}
}
#################
server {
listen 8080;
server_name www.sc2.com;
root /usr/share/nginx/html;
access_log /var/log/nginx/sc/access.log main;
location / {
}
}
5、# 创建sc目录用来收集访问www.sc.com的日志信息
[root@nginx-kafka01 html]# mkdir /var/log/nginx/sc
6、# 检查语法错误
[root@nginx-kafka01 html]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
7、# 检查nginx进程
[root@nginx-kafka01 html]# ps -ef|grep nginx
root 2176 1498 0 11:38 pts/0 00:00:00 grep --color=auto nginx
[root@nginx-kafka01 html]# systemctl restart nginx # 重启nginx服务
[root@nginx-kafka01 html]# ps -ef|grep nginx
root 2190 1 0 11:38 ? 00:00:00 nginx: master process /usr/sbin/nginx
nginx 2191 2190 0 11:38 ? 00:00:00 nginx: worker process
nginx 2192 2190 0 11:38 ? 00:00:00 nginx: worker process
nginx 2193 2190 0 11:38 ? 00:00:00 nginx: worker process
nginx 2194 2190 0 11:38 ? 00:00:00 nginx: worker process
root 2196 1498 0 11:38 pts/0 00:00:00 grep --color=auto nginx
[root@nginx-kafka01 html]#
8、修改nginx配置文件后要重新加载配置
# 重新加载配置
[root@nginx-kafka01 html]# nginx -s reload
[root@nginx-kafka01 html]#
9、# 访问网站 默认访问index.html
[root@nginx-kafka01 html]# ls
404.html en-US img nginx-logo.png sc.html
50x.html icons index.html poweredby.png
[root@nginx-kafka01 html]# less index.html
[root@nginx-kafka01 html]# pwd
/usr/share/nginx/html
[root@nginx-kafka01 html]#
2. 搭建kafka 集群
2.1 kafka优势
为什么要引入kafka ?
1.使用kafka做日志统一收集,故障发生时,方便定位问题,排除故障
2.日志一般用来做不同的用途,如果把程序放在nginx-filebeat集群上,则边缘应用占用了大量的资源,导致nginx服务不稳定,影响用户体验,所以有kafka集群在的话,方便做其他功能的扩展,对于其他的程序直接找kafka即可,尽可能地不影响nginx。
kafka有什么作用?
kafka:是一种消息中间件,主要作用有:
日志收集:收集日志信息。
业务解耦:方便扩展、提高业务的稳定性,把发送注册成功的功能移植出去,在核心业务上增加一个,消息中间件 然后让另外的程序去消费中间件,达到业务解耦。
流量削峰:理解为 提前把红包金额随机分20份 至消息中li间件,等待消费达到流量削峰的目的。
2.2 kafka组件分析
broker:broker1、 broker2、 broker3 组成了kafka集群,broker是kafka节点。
topic:消息的分类,比如nginx,mysql日志给不同的主题,就是不同的类型,例如:sc主题、xixi主题。
partition:分区,一般来说和broker数量一致,提高吞吐量,提高效率、并发;针对于sc topic来说,有三个分区,sc-partition1、sc-partition2、sc-partition3;
多个partition,会造成日志消息顺序混乱,如果对信息顺序有要求就只设置一个partition就可以了;
replica:副本,就是完整的数据分区备份,sc-partition1-bak副本、sc-partition2-bak副本、sc-partition3-bak副本
leader、follower:领导、跟随者,从partition中找一个作为leader 其他partition为follower。一般有n个副本 则有n-1个follower,1个leader
各部分的关系:理论上来说 如果broker数量和replica一致,则可以坏掉n-1台 ;partition数量一般来说和broker数量一致,提高吞吐量 提高效率、并发;
2.3 数据的一致性
2.3.1 生产者数据的一致性
nginx web传给leader 但是 leader挂掉了 导致数据不一致
解决办法:ISR List -> in-sync-replica集合列表 需要同步的follower集合,比如:5个副本 1个leader 4个follower -->ISR;
有一条信息来了,leader通过以下机制知道同步了那些副本:
根据ISR列表信息来判断,如果一个follower挂掉了,就从这个列表中删除,如果一个follower过慢或卡住了,则也会将其从列表中删除;
如何保证生产数据的一致性?
producer可以通过request required acks设置,ack可以为0(生产者不需要接受服务器的响应 发完就发下一条)或1(默认,leader受到就会给生产者发送响应,然后发送下一条),-1(等待ISR列表中的每一个副本都接受到,才给生产者响应);
2.3.2 消费者数据的一致性
如何保证消费数据的一致性?
消费者消费数据时,引入了high water mark机制 木桶效应 最多只能消费到ISR列表里offset偏移量最小的副本;
2.4 配置kafka
kafka_2.12-2.8.1版本还需要zookeeper组件
1、打开配置文件
[root@nginx-kafka02 config]# pwd
/opt/kafka_2.12-2.8.1/config
[root@nginx-kafka02 config]#
[root@nginx-kafka02 config]# vim server.properties
配置每台nginx的broker.id
设置broker.id=1
设置broker.id=2
设置broker.id=3
2、配置每台nginx的listeners
listeners=PLAINTEXT://nginx-kafka01:9092
listeners=PLAINTEXT://nginx-kafka02:9092
listeners=PLAINTEXT://nginx-kafka03:9092
3、修改每台nginx上的日志收集目录
--
# A comma separated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
--
log.dirs=/data
4、修改分区数
num.partitions=3
5、添加连接
zookeeper.connect=192.168.2.192:2181,192.168.2.113:2181,192.168.2.73:2181
3.配置filebeat,测试consumer,producer
3.1 filebeat简介
在nginx web服务端 配置filebeat(生产者producer)(第三方日志统一收集程序),是一种日志收集器,配置/var/log/*.log即可收集log日志文件;
参考链接–filebeat
3.2 filebeat布署
#安装
1、rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
2、编辑/etc/yum.repos.d/fb.repo文件
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
3、yum安装
yum install filebeat -y
rpm -qa |grep fileberat #可以查看filebeat有没有安装 rpm -qa 是查看机器上安装的所有软件包
rpm -ql filebeat 查看filebeat安装到哪里去了,牵扯的文件有哪些
4、设置开机自启
systemctl enable filebeat
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/sc/access.log
#==========------------------------------kafka-----------------------------------
output.kafka:
hosts: ["192.168.1.173:9092","192.168.1.174:9092","192.168.1.175:9092"]
topic: nginxlog
keep_alive: 10s
*******************
#ymal格式
{
"filebeat.inputs": [
{
"type":"log",
"enabled":true,
"paths":["/var/log/nginx/sc_access"]
},
],
}
5、#配置
修改配置文件/etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/sc/access.log
#==========------------------------------kafka-----------------------------------
output.kafka:
hosts: ["192.168.229.139:9092","192.168.229.140:9092"]
topic: nginxlog
keep_alive: 10s
6、#创建主题nginxlog
bin/kaa-topics.sh --create --zookeeper 192.168.77.132:2181 --replication-factor 3 --partitions 1 --topic nginxlog
7、#启动服务:
systemctl start filebeat
[root@nginx-kafka01 opt]# ps -ef |grep filebeat root 5537 1 0 15:32 ? 00:00:08 /usr/share/filebeat/bin/filebeat --environment systemd -c /etc/filebeat/filebeat.yml --path.home /usr/share/filebeat --path.config /etc/filebeat --path.data /var/lib/filebeat --path.logs /var/log/filebeat
8、filebeat数据文件
[root@nginx-kafka01 filebeat]# pwd
/var/lib/filebeat/registry/filebeat
[root@nginx-kafka01 filebeat]# less log.json
9、# 查看效果
[root@nginx-kafka01 kafka_2.12-2.8.1]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.2.192:9092 --topic nginxlog --from-beginning
4.搭建zookeeper集群
4.1 配置zookeeper
### 配置zookeeper ### 1、拷贝zoo_sample.cfg [root@nginx-kafka01 conf]# cp zoo_sample.cfg zoo.cfg [root@nginx-kafka01 conf]# ls configuration.xsl log4j.properties zoo.cfg zoo_sample.cfg [root@nginx-kafka01 conf]# pwd /opt/apache-zookeeper-3.6.3-bin/conf [root@nginx-kafka01 conf]# 2、修改zoo.cfg 文件 [root@nginx-kafka02 conf]# pwd /opt/apache-zookeeper-3.6.3-bin/conf [root@nginx-kafka02 conf]# vim zoo.cfg 在38行添加: server.1=192.168.2.192:3888:4888 server.2=192.168.2.113:3888:4888 server.3=192.168.2.73:3888:4888 3、创建 /tmp/zookeeper 目录 [root@nginx-kafka01 conf]# mkdir /tmp/zookeeper [root@nginx-kafka01 conf]# 4、根据server.1 server.2 server.3对应的ip地址对应的nginx 给每一台nginx定义编号1 2 3 --- [root@nginx-kafka01 conf]# mkdir /tmp/zookeeper [root@nginx-kafka01 conf]# cd /tmp/zookeeper/ [root@nginx-kafka01 zookeeper]# ls [root@nginx-kafka01 zookeeper]# echo 1 > /tmp/zookeeper/myid --- [root@nginx-kafka02 conf]# mkdir /tmp/zookeeper [root@nginx-kafka02 conf]# echo 2 > /tmp/zookeeper/myid [root@nginx-kafka02 conf]# --- [root@nginx-kafka03 conf]# vim zoo_sample.cfg [root@nginx-kafka03 conf]# mkdir /tmp/zookeeper [root@nginx-kafka03 conf]# echo 3 > /tmp/zookeeper/myid [root@nginx-kafka03 conf]# 5、启动zookeeper 三台都要启动 [root@nginx-kafka01 bin]# ./zkServer.sh start /usr/bin/java ZooKeeper JMX enabled by default Using config: /opt/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@nginx-kafka01 bin]# 6、查看 zookeeper状态 [root@nginx-kafka01 bin]#./zkServer.sh status /usr/bin/java ZooKeeper JMX enabled by default Using config: /opt/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: follower [root@nginx-kafka01 bin]# -- 7、启动kafka [root@nginx-kafka03 kafka_2.12-2.8.1]# pwd /opt/kafka_2.12-2.8.1 [root@nginx-kafka03 kafka_2.12-2.8.1]# [root@nginx-kafka03 kafka_2.12-2.8.1]# bin/kafka-server-start.sh -daemon config/server.properties [root@nginx-kafka01 kafka_2.12-2.8.1]# ps -ef|grep kafka zookeeper配置管理工具,通过4888端口来检验存活 通过3888端口传送数据 zookeeper开源式分布式应用程序协调服务,使用zookeeper管理配置, 功能:配置维护 分布式同步 组服务等 8、连接zookeeper [root@nginx-kafka01 conf]# cd /opt/apache-zookeeper-3.6.3-bin [root@nginx-kafka01 apache-zookeeper-3.6.3-bin]# cd bin/ [root@nginx-kafka01 bin]# ls README.txt zkEnv.sh zkSnapShotToolkit.sh zkCleanup.sh zkServer.cmd zkTxnLogToolkit.cmd zkCli.cmd zkServer-initialize.sh zkTxnLogToolkit.sh zkCli.sh zkServer.sh zkEnv.cmd zkSnapShotToolkit.cmd [root@nginx-kafka01 bin]# ./zkCli.sh # 查看zookeeper信息(kafka集群成功) [zk: localhost:2181(CONNECTED) 1] ls / [admin, brokers, cluster, config, consumers, controller, controller_epoch, feure, isr_change_notification, latest_producer_id_block, log_dir_event_notificion, zookeeper] [zk: localhost:2181(CONNECTED) 2] ls /brokers [ids, seqid, topics] [zk: localhost:2181(CONNECTED) 3] ls /brokers [ids, seqid, topics] [zk: localhost:2181(CONNECTED) 4] ls /brokers/ids [1, 2, 3] [zk: localhost:2181(CONNECTED) 5] # zookeeper目录结构: / |-----------------| brokers | | ids topics --- # 创建/sc [zk: localhost:2181(CONNECTED) 7] create /sc Created /sc [zk: localhost:2181(CONNECTED) 10] create /sc/xx Created /sc/xx [zk: localhost:2181(CONNECTED) 11] set /sc/xx yy [zk: localhost:2181(CONNECTED) 12] get /sc/xx yy [zk: localhost:2181(CONNECTED) 13] ls /sc [xx] [zk: localhost:2181(CONNECTED) 14] -- # 创建/sc/page [zk: localhost:2181(CONNECTED) 14] create /sc/page Created /sc/page # 设置/sc/page 的值 [zk: localhost:2181(CONNECTED) 15] set /sc/page 10 # 获取/sc/page 的值 元器件数据手册、IC替代型号,打造电子元器件IC百科大全!


