3万字100道大数据技术之高频面试题总结(附答案)
时间:2023-10-07 06:07:02
?? 关注微信官方账号【笑风云路】,在文章底部加微信,获取《大数据技术高频面试题总结(附答案)》pdf,背题比较方便,一文在手,面试我有
前言
最近有很多粉丝问我,有什么方法可以快速提高自己,通过阿里、腾讯、字节跳动、京东等互联网工厂面试,我认为短时间提高自己最快的方法是面试,最近总结了大数据高频面试,与你分享,希望每个人都能梦想大工厂,来吧,我的生活由我决定。
目录
-
- 1、Hadoop常用端口号?
- 2、Hadoop配置文件?
- 3、HDFS读写过程
- 4、HDFS小文件处理
- 5、HDFS的NameNode内存
- 6、NameNode心跳并发配置
- 7、Shuffle优化
- 8、说一下Yarn工作机制?
- 9、Yarn什么是调度器?
- 10、Hadoop停机怎么办?
- 11、Hadoop解决数据倾斜问题
- 12、Kafka架构
- 13、Kafka的机器数量
- 14.设置副本数
- 15、Kafka日志保存时间
- 16、Kakfa分区数
- 17、Kafka的ISR同步队列副本
- 18、Kafka分区分配策略
- 19、Kafka挂了怎么办?
- 20、Kafka如何确保数据不丢失
- 21、Kafka如何一次准确地实现数据?
- 22、Kafka过期数据清理
- 23、Kafka如何保证高效读写数据?
- 24、Kafka数据积压
- 25、Kafka如何增加吞吐量?
- 26、Kafka单日志传输大小
- 27、Kafka参数优化
- 28、HQL提交流程?
- 29、Hive比较数据库
- 30.内表和外表的区别?
- 31、Hive中4个By区别?
- 32、自定义UDF、UDTF函数
- 33、窗口函数
- 34、Hive优化
- 35、Hive支持引擎和差异?
- 36、Spark和Hadoop的最大区别
- 37、Spark运行模式
- 38、Spark常用端口号
- 39、简述Spark架构及操作提交流程
- 40、Spark提交作业参数
- 41、Spark的transformation算子
- 42、Spark的action算子
- 43、map和mapPartitions区别
- 44、Repartition和Coalesce区别
- 45、reduceByKey与groupByKey的区别
- 46、reduceByKey、foldByKey、aggregateByKey、combineByKey区别
- 47、Kryo序列化
- 48、Spark分区
- 49、SparkSQL中RDD、DataFrame、DataSet三者的转换
- 50、当Spark如何减少涉及数据库的操作?Spark运行中的数据库连接数?
- 51、Spark Shuffle默认并行度
- 52、控制Spark reduce缓存 调优shuffle
- 53、Spark Streaming第一次运行不丢失数据
- 54、Spark Streaming一次精确消费
- 55、Spark Streaming控制每秒消费数据的速度
- 56、Spark Streaming背压机制
- 57、Spark Streaming一个stage耗时
- 58、Spark Streaming优雅关闭
- 59、Spark Streaming默认分区数
- 60、SparkStreaming消费的方式有哪些?Kafka它们之间的数据有什么区别?
- 61、简述SparkStreaming窗口函数的原理
- 62、Spark 数据倾斜解决方案
- 简单介绍一下 Flink?
- 64、Flink跟Spark Streaming的区别
- 65、Flink集群的作用是什么?它们各自的作用是什么?
- 66.公司提交了多少实时任务?Job Manager? 有多少TaskManager?
- 67、Flink了解并行度吗?Flink并行度设置是什么?
- 68、Flink的keyby如何实现分区?分区和分组有什么区别?
- 69、Flink的interval join实现原理?join不上去怎么办?
- 70、介绍一下Flink状态编程和状态机制?
- 71、Flink三种时间语义
- 72、Flink 中的Watermark机制
- 73、Watermark是数据吗?怎么生成的?怎么传递的?
- 74、Watermark生成方法?
- 75、说说Flink窗口(分类、生命周期、触发、划分)
- 76、Exactly-Once的保证
- 77、Flink分布式快照的原理是什么?
- 78、Checkpoint如何设置参数?
- 79、介绍一下Flink的CEP机制
- 80、Flink CEP 当状态未到达时,数据将保存在哪里?
- 81、Flink SQL工作机制?
- 82、FlinkSQL怎么对SQL优化句子?
- 83、Flink常见的维表Join方案
- 84、Checkpoint和Savepoint的区别
- 85、Flume组成,Put事务,Take事务
- 86、Flume Channel选择器
- 87、Flume监控器
- 88、 Flume收集数据会丢失吗?(防止数据丢失的机制)
- 89、Datax速度控制
- 90、Datax内存调整
- 91、Datax空值处理
- 92、HBase的RowKey设计原则
- 93、HBase的一级索引
- 94、Sqoop参数
- 95、Sqoop导入导出Null存储一致性问题
- 96、 Sqoop底层运行的任务是什么?
- 97、Sqoop当导入数据时,数据倾斜
- 98、Sqoop数据导出Parquet(项目中遇到的问题)
- 99、Azkaban集群每天运行多少指标?
- 任务挂了怎么办?
1、Hadoop常用端口号?
| hadoop2.x | hadoop3.x | |
|---|---|---|
| 访问HDFS端口 | 50070 | 9870 |
| 访问MR执行端口 | 8088 | 8088 |
| 历史服务器 | 19888 | 19888 |
| 客户端访问集群端口 | 9000 | 8020 |
2、Hadoop配置文件?
配置文件:
hadoop2.x:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml slaves
hadoop3.x: cor-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml workers
3、HDFS读流程和写流程
读流程:
- hdfs客户端向NameNode发送下载请求,请求中携带目标文件
- NameNode节点响应下载请求,返回目标文件的元数据
- 客户端就会根据元数据去数据所在的DataNode节点发送读数据请求
- DataNode节点就传输数据到客户端
- 所有DataNode节点的数据传输完成
写流程:
- hdfs 客户端向NameNode节点发送上传文件请求
- NameNode响应请求,返回可以上传文件
- hdfs 客户端发送要上传第一个Block(0-128MB)的请求
- NameNode响应请求,返回存储数据的DataNode的节点信息
- 往上一步中得到DataNode节点发送建立Block传输通道的请求
- DataNode节点应答成功
- 客户端开始向DataNode节点传输数据
- 当向所有的DataNode节点的数据传输完成之后,客户端就会给NameNode节点反馈传输数据完成。
4、HDFS小文件处理
1)会有什么影响
(1)存储层面:
1个文件块,占用namenode多大内存150字节
128G能存储多少文件块? 128 g* 1024m1024kb1024byte/150字节 = 9.1亿文件块
(2)计算层面:
每个小文件都会起到一个MapTask,1个MapTask默认内存1G。浪费资源。
2)怎么解决
(1)采用har归档方式,将小文件归档
(2)采用CombineTextInputFormat
(3)有小文件场景开启JVM重用;如果没有小文件,不要开启JVM重用,因为会一直占用使用到的task卡槽,直到任务完成才释放。
JVM重用可以使得JVM实例在同一个job中重新使用N次,N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间
<property>
<name>mapreduce.job.jvm.numtasksname>
<value>10value>
<description>How many tasks to run per jvm,if set to -1 ,there is no limitdescription>
property>
5、HDFS的NameNode内存
1)Hadoop2.x系列,配置NameNode默认2000m
2)Hadoop3.x系列,配置NameNode内存是动态分配的
NameNode内存最小值1G,每增加100万个block,增加1G内存。
6、NameNode心跳并发配置
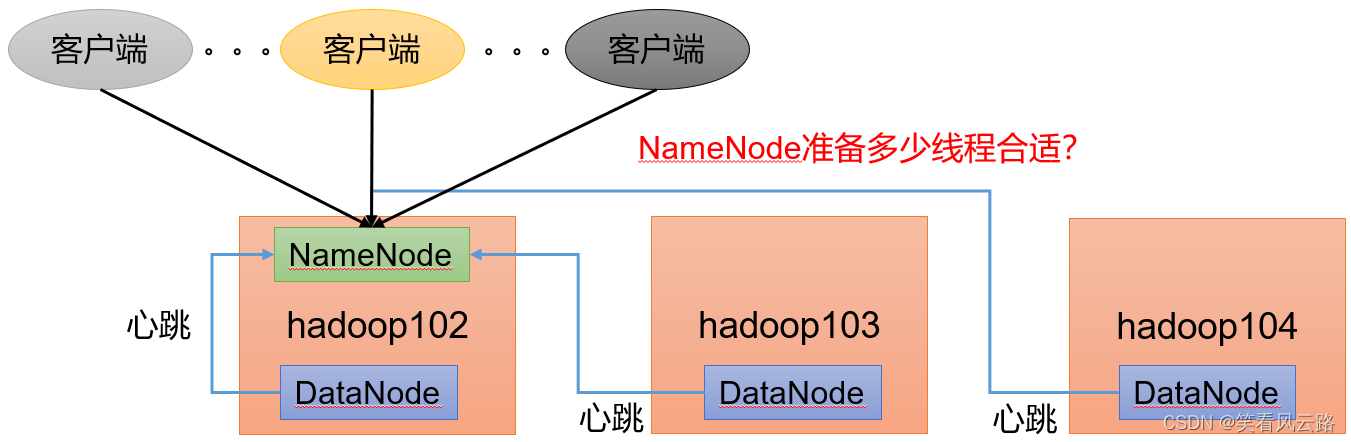
企业经验:dfs.namenode.handler.count=20×loge^(Cluster Size),比如集群规模(DataNode台数)为3台时,此参数设置为21。
7、Shuffle优化
MapReduce优化:
8、说一下Yarn工作机制?
Yarn工作机制:
Yarn生产环境核心参数:
9、Yarn调度器有哪些?
1)主要分为三类:
FIFO 、Capacity Scheduler(容量调度器)和Fair Sceduler(公平调度器)。
Apache默认的资源调度器是容量调度器;
CDH默认的资源调度器是公平调度器。
2)区别:
FIFO调度器:支持单队列 、先进先出 生产环境不会用。
容量调度器:支持多队列。队列资源分配,优先选择资源占用率最低的队列分配资源;作业资源分配,按照作业的优先级和提交时间顺序分配资源;容器资源分配,本地原则(同一节点/同一机架/不同节点不同机架)
公平调度器:支持多队列,保证每个任务公平享有队列资源。资源不够时可以按照缺额分配。
3)在生产环境下怎么选择?
大厂:如果对并发度要求比较高,选择公平,要求服务器性能必须OK;
中小公司,集群服务器资源不太充裕选择容量。
4)在生产环境怎么创建队列?
(1)调度器默认就1个default队列,不能满足生产要求。
(2)按照框架:hive /spark/ flink 每个框架的任务放入指定的队列(企业用的不是特别多)
(3)按照部门:业务部门1、业务部门2
(4)按照业务模块:登录注册、购物车、下单
5)创建多队列的好处?
(1)因为担心员工不小心,写递归死循环代码,把所有资源全部耗尽。
(2)实现任务的降级使用,特殊时期保证重要的任务队列资源充足。
业务部门1(重要)=》业务部门2(比较重要)=》下单(一般)=》购物车(一般)=》登录注册(次要)
10、Hadoop宕机怎么办?
1)如果MR任务造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
2)如果写入文件过快造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。例如,可以调整Flume每批次拉取数据量的大小参数batchsize。
11、Hadoop解决数据倾斜方法
1)提前在map进行combine,减少传输的数据量
在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。
如果导致数据倾斜的key大量分布在不同的mapper的时候,这种方法就不是很有效了。
2)导致数据倾斜的key 大量分布在不同的mapper
(1)局部聚合加全局聚合。
第一次在map阶段对那些导致了数据倾斜的key 加上1到n的随机前缀,这样本来相同的key 也会被分到多个Reducer中进行局部聚合,数量就会大大降低。
第二次mapreduce,去掉key的随机前缀,进行全局聚合。
思想:二次mr,第一次将key随机散列到不同reducer进行处理达到负载均衡目的。第二次再根据去掉key的随机前缀,按原key进行reduce处理。
这个方法进行两次mapreduce,性能稍差。
(2)增加Reducer,提升并行度
JobConf.setNumReduceTasks(int)
(3)实现自定义分区
根据数据分布情况,自定义散列函数,将key均匀分配到不同Reducer
12、Kafka架构
生产者、Broker、消费者、Zookeeper;
注意:Zookeeper中保存Broker id和消费者offsets等信息,但是没有生产者信息。
生产者发送数据流程:
Broker工作流程:
消费者组初始化流程:
消费者组消费数据流程:
13、Kafka的机器数量
Kafka机器数量 = 2 *(峰值生产速度 * 副本数 / 100)+ 1
14、副本数设定
一般我们设置成2个或3个,很多企业设置为2个。
副本的优势:提高可靠性;副本劣势:增加了网络IO传输
15、Kafka日志保存时间
默认保存7天;生产环境建议3天
16、Kakfa分区数
(1)创建一个只有1个分区的topic。
(2)测试这个topic的producer吞吐量和consumer吞吐量。
(3)假设他们的值分别是Tp和Tc,单位可以是MB/s。
(4)然后假设总的目标吞吐量是Tt,那么分区数 = Tt / min(Tp,Tc)。
例如:producer吞吐量 = 20m/s;consumer吞吐量 = 50m/s,期望吞吐量100m/s;
分区数 = 100 / 20 = 5分区
分区数一般设置为:3-10个
分区数不是越多越好,也不是越少越好,需要搭建完集群,进行压测,再灵活调整分区个数。
17、Kafka的ISR副本同步队列
ISR(In-Sync Replicas),副本同步队列。如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认30s。。
任意一个维度超过阈值都会把Follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的Follower也会先存放在OSR中。
Kafka分区中的所有副本统称为AR = ISR + OSR
18、Kafka分区分配策略
1)生产端分区分配
- 指明partition的情况下,直接将指明的值作为partition值,例如partition=0,所有数据写入分区0
- 没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值,例如:key1的hash值=5,key2的hash值=6,topic的partition数=2,那么key1对应的value1写入1号分区,key2对应的value2写入0号分区
- 既没有partition值又没有key值的情况下,kafka采用粘性分区器,随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,kafka再随机选择一个分区进行使用。
2)消费端分区分配策略
分区分配策略之Range:
分区分配策略之RoundRobin:
19、Kafka挂掉怎么办?
在生产环境中,如果某个Kafka节点挂掉。
正常处理办法:
(1)先尝试重新启动一下,如果能启动正常,那直接解决。
(2)如果重启不行,考虑增加内存、增加CPU、网络带宽。
(3)如果将kafka整个节点误删除,如果副本数大于等于2,可以按照服役新节点的方式重新服役一个新节点,并执行负载均衡。
(4)Flume缓存 + 日志服务器有备份
20、Kafka如何保证不丢失数据
1)producer角度
acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等;
acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低;
在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景。
2)broker角度
副本数大于等于2
min.insync.replicas大于等于2
21、Kafka数据如何做到精准一次
(1)生产者角度
acks设置为-1 (acks=-1)。
幂等性(enable.idempotence = true) + 事务 。
(2)broker服务端角度
分区副本大于等于2 (–replication-factor 2)。
ISR里应答的最小副本数量大于等于2 (min.insync.replicas = 2)。
(3)消费者
事务 + 手动提交offset (enable.auto.commit = false)。
消费者输出的目的地必须支持事务(MySQL、Kafka)。
22、Kafka过期数据清理
日志清理的策略只有delete和compact两种
1)delete日志删除:将过期数据删除
log.cleanup.policy = delete 所有数据启用删除策略
(1)基于时间:默认打开。以segment中所有记录中的最大时间戳作为该文件时间戳。
(2)基于大小:默认关闭。超过设置的所有日志总大小,删除最早的segment。
log.retention.bytes,默认等于-1,表示无穷大。
2)compact日志压缩
对于不同key的不同value值,只保留最后一个版本。
log.cleanup.policy = compact 所有数据启用压缩策略
注意: 压缩后的offset可能是不连续的,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息开始消费。
这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息里就保存了所有用户最新的资料。
23、Kafka高效读写数据是如何保证的?
1)Kafka本身是分布式集群,可以采用分区技术,并行度高
2)读数据采用稀疏索引,可以快速定位要消费的数据
3)顺序写磁盘
Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
4)页缓存 + 零拷贝技术
24、Kafka数据积压
1)如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数 = 分区数。(两者缺一不可)
增加分区数;
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3
2)如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压。
fetch.max.bytes:默认Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受message.max.bytes (broker config)or max.message.bytes (topic config)影响。
max.poll.records:一次poll拉取数据返回消息的最大条数,默认是500条
25、Kafka如何提升吞吐量?
1)提升生产吞吐量
(1)buffer.memory:发送消息的缓冲区大小,默认值是32m,可以增加到64m。
(2)batch.size:默认是16k。如果batch设置太小,会导致频繁网络请求,吞吐量下降;如果batch太大,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
(3)linger.ms,这个值默认是0,意思就是消息必须立即被发送。一般设置一个5-100毫秒。如果linger.ms设置的太小,会导致频繁网络请求,吞吐量下降;如果linger.ms太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
(4)compression.type:默认是none,不压缩,但是也可以使用lz4压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大producer端的CPU开销。
2)增加分区
3)消费者提高吞吐量
(1)调整fetch.max.bytes大小,默认是50m。
(2)调整max.poll.records大小,默认是500条。
26、Kafka单条日志传输大小
Kafka对于消息体的大小默认为单条最大值是1M但是在我们应用场景中,常常会出现一条消息大于1M,如果不对Kafka进行配置。则会出现生产者无法将消息推送到Kafka或消费者无法去消费Kafka里面的数据,这时我们就要对Kafka进行以下配置:server.properties:
message.max.bytes:默认1m,broker端接收每个批次消息最大值。
max.request.size:默认1m,生产者发往broker每个请求消息最大值。针对topic级别设置消息体的大小。
replica.fetch.max.bytes:默认1m,副本同步数据,每个批次消息最大值。
27、Kafka参数优化
重点调优参数:
(1)buffer.memory 32m
(2)batch.size:16k
(3)linger.ms默认0 调整 5-100ms
(4)compression.type采用压缩 snappy
(5)消费者端调整fetch.max.bytes大小,默认是50m。
(6)消费者端调整max.poll.records大小,默认是500条。
(7)单条日志大小:message.max.bytes、max.request.size、replica.fetch.max.bytes适当调整2-10m
(8)Kafka堆内存建议每个节点:10g ~ 15g
在kafka-server-start.sh中修改
if [ “x$KAFKA_HEAP_OPTS” = “x” ]; then
export KAFKA_HEAP_OPTS=“-Xmx10G -Xms10G”
fi
(9)增加CPU核数
num.io.threads = 8 负责写磁盘的线程数,整个参数值要占总核数的50%。 12
num.replica.fetchers = 1 副本拉取线程数,这个参数占总核数的50%的1/3。 4
num.network.threads = 3 数据传输线程数,这个参数占总核数的50%的2/3。 8
(10)日志保存时间log.retention.hours 3天
(11)副本数 调整为2
28、HQL提交流程?
1.进入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为AST(抽象语法树)
2.遍历AST,抽象出查询的基本组成单元QueryBlock(查询块),可以理解为最小的查询执行单元
3.遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元
4.使用逻辑优化器对OperatorTree(操作树)进行逻辑优化,例如合并不必要的ReduceSinkOperator,减少Shuffle数据量
5.遍历OperatorTree,转换为TaskTree,也就是翻译为MR任务的流程,将逻辑执行计划转换物理执行计划
6.使用物理优化器对TaskTree进行物理优化
7.生成最终的执行计划,提交任务到Hadoop集群运行。
29、Hive和数据库比较
Hive 和数据库除了拥有类似的查询语言,再无类似之处。
1)数据存储位置
Hive 存储在 HDFS 。数据库将数据保存在块设备或者本地文件系统中。
2)数据更新
Hive中不建议对数据的改写。而数据库中的数据通常是需要经常进行修改的,
3)执行延迟
Hive 执行延迟较高。数据库的执行延迟较低。当然,这个是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
4)数据规模
Hive支持很大规模的数据计算;数据库可以支持的数据规模较小。
30、内部表和外部表的区别?
元数据、原始数据
1)删除数据时:
内部表:元数据、原始数据,全删除
外部表:元数据 只删除
2)在公司生产环境下,什么时候创建内部表,什么时候创建外部表?
在公司中绝大多数场景都是外部表。
自己使用的临时表,才会创建内部表;
31、Hive中4个By区别?
1)Order By:全局排序,只有一个Reducer;
2)Sort By:分区内有序;
3)Distrbute By:类似MR中Partition,进行分区,结合sort by使用。
4) Cluster By:当Distribute by和Sorts by字段相同时,可以使用Cluster by方式。Cluster by除了具有Distribute by的功能外还兼具Sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
在生产环境中Order By用的比较少,容易导致OOM。
在生产环境中Sort By + Distrbute By用的多。
32、自定义UDF、UDTF函数
1)在项目中是否自定义过UDF、UDTF函数,以及用他们处理了什么问题,及自定义步骤?
(1)用UDF函数解析公共字段;用UDTF函数解析事件字段。
(2)自定义UDF:继承UDF,重写evaluate方法
(3)自定义UDTF:继承自GenericUDTF,重写3个方法:initialize(自定义输出的列名和类型),process(将结果返回forward(result)),close
2)为什么要自定义UDF/UDTF?
因为自定义函数,可以自己埋点Log打印日志,出错或者数据异常,方便调试。
引入第三方jar包时,也需要。
33、窗口函数
1)Rank
(1)RANK() 排序相同时会重复,总数不会变
(2)DENSE_RANK() 排序相同时会重复,总数会减少
(3)ROW_NUMBER() 会根据顺序计算
2) OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
(1)CURRENT ROW:当前行
(2)n PRECEDING:往前n行数据
(3) n FOLLOWING:往后n行数据
(4)UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
(5) LAG(col,n):往前第n行数据
(6)LEAD(col,n):往后第n行数据
(7) NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
34、Hive优化
1)MapJoin
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
2)行列过滤
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤。
3)列式存储
4)采用分区技术
5)合理设置Map数
mapred.min.split.size: 指的是数据的最小分割单元大小;min的默认值是1B
mapred.max.split.size: 指的是数据的最大分割单元大小;max的默认值是256MB
通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。
需要提醒的是,直接调整mapred.map.tasks这个参数是没有效果的。
https://www.cnblogs.com/swordfall/p/11037539.html
6)合理设置Reduce数
Reduce个数并不是越多越好
(1)过多的启动和初始化Reduce也会消耗时间和资源;
(2)另外,有多少个Reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
在设置Reduce个数的时候也需要考虑这两个原则:处理大数据量利用合适的Reduce数;使单个Reduce任务处理数据量大小要合适;
set mapreduce.job.reduces=5
7)小文件如何产生的?
(1)动态分区插入数据,产生大量的小文件,从而导致map数量剧增;
(2)reduce数量越多,小文件也越多(reduce的个数和输出文件是对应的);
(3)数据源本身就包含大量的小文件。
8)小文件解决方案
(1)在Map执行前合并小文件,减少Map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat没有对小文件合并功能。
(2)merge
// 输出合并小文件
SET hive.merge.mapfiles = true; – 默认true,在map-only任务结束时合并小文件
SET hive.merge.mapredfiles = true; – 默认false,在map-reduce任务结束时合并小文件
SET hive.merge.size.per.task = 268435456; – 默认256M
SET hive.merge.smallfiles.avgsize = 16777216; – 当输出文件的平均大小小于16m该值时,启动一个独立的map-reduce任务进行文件merge
(3)开启JVM重用
set mapreduce.job.jvm.numtasks=10
9)开启map端combiner(不影响最终业务逻辑)
set hive.map.aggr=true;
10)压缩(选择快的)
设置map端输出、中间结果压缩。(不完全是解决数据倾斜的问题,但是减少了IO读写和网络传输,能提高很多效率)
set hive.exec.compress.intermediate=true --启用中间数据压缩
set mapreduce.map.output.compress=true --启用最终数据压缩
set mapreduce.map.outout.compress.codec=…; --设置压缩方式
11)采用tez引擎或者spark引擎
35、Hive支持的引擎以及区别?
支持的引擎:Mr、tez、spark
区别:
Mr引擎:多job串联,基于磁盘,落盘的地方比较多。虽然慢,但一定能跑出结果。一般处理,周、月、年指标。
Spark引擎:虽然在Shuffle过程中也落盘,但是并不是所有算子都需要Shuffle,尤其是多算子过程,中间过程不落盘 DAG有向无环图。 兼顾了可靠性和效率。一般处理天指标。
Tez引擎:完全基于内存。 注意:如果数据量特别大,慎重使用。容易OOM。一般用于快速出结果,数据量比较小的场景。
36、Spark和Hadoop的最大区别
Hadoop主要解决,海量数据的存储和海量数据的分析计算。
Spark主要解决海量数据的分析计算。
37、Spark运行模式
1)Local:运行在一台机器上。 测试用。
2)Standalone:是Spark自身的一个调度系统。 对集群性能要求非常高时用。国内很少使用。
3)Yarn:采用Hadoop的资源调度器。 国内大量使用。
4)Mesos:国内很少使用。
38、Spark常用端口号
1)4040 spark-shell任务端口
2)7077 内部通讯端口。 类比Hadoop的8020/9000
3)8080 查看任务执行情况端口。 类比Hadoop的8088
4)18080 历史服务器。类比Hadoop的19888
注意:由于Spark只负责计算,所有并没有Hadoop中存储数据的端口50070
39、简述Spark的架构与作业提交流程
1、脚本启动执行,SparkSubmit中对参数进行解析,创建Client,对参数和命令进行封装,提交任务信息到ResourceManager(RM)
2、启动ApplicationMaster(AM)
3、AM根据参数,启动Driver线程,初始化SparkContext
4、向RM注册AM并申请资源
5、RM向AM返回可用资源列表
6、创建lunchtorPool,生成ExecutorRunnable,启动ExecutorBackend;启动RPC通信模块
7、ExecutorBackend的RPC与AM的RPC发送请求,注册Executor
8、AM的RPC返回注册成功
9、创建Executor成功
10、AM进行任务的切分
11、AM进行任务的分配
40、Spark提交作业参数
在提交任务时的几个重要参数
executor-cores —— 每个executor使用的内核数,默认为1,官方建议2-5个,我们企业是4个
num-executors —— 启动executors的数量,默认为2
executor-memory —— executor内存大小,默认1G
driver-cores —— driver使用内核数,默认为1
driver-memory —— driver内存大小,默认512M
41、Spark的transformation算子
1)单Value
(1)map
(2)mapPartitions
(3)mapPartitionsWithIndex
(4)flatMap
(5)glom
(6)groupBy
(7)filter
(8)sample
(9)distinct
(10)coalesce
(11)repartition
(12)sortBy
(13)pipe
2)双vlaue
(1)intersection
(2)union
(3)subtract
(4)zip
3)Key-Value
(1)partitionBy
(2)reduceByKey
(3)groupByKey
(4)aggregateByKey
(5)foldByKey
(6)combineByKey
(7)sortByKey
(8)mapValues
(9)join
(10)cogroup
42、Spark的action算子
(1)reduce
(2)collect
(3)count
(4)first
(5)take
(6)takeOrdered
(7)aggregate
(8)fold
(9)countByKey
(10)save
(11)foreach
43、map和mapPartitions区别
1)map:每次处理一条数据
2)mapPartitions:每次处理一个分区数据
44、Repartition和Coalesce区别
1)关系:
两者都是用来改变RDD的partition数量的,repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
2)区别:
repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle
一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce
45、reduceByKey与groupByKey的区别
reduceByKey:具有预聚合操作
groupByKey:没有预聚合
在不影响业务逻辑的前提下,优先采用reduceByKey。
46、reduceByKey、foldByKey、aggregateByKey、combineByKey区别
ReduceByKey: 没有初始值 分区内和分区间逻辑相同
foldByKey:有初始值 分区内和分区间逻辑相同
aggregateByKey :有初始值 分区内和分区间逻辑可以不同
combineByKey:初始值可以变化结构 分区内和分区间逻辑不同
47、Kryo序列化
Kryo序列化比Java序列化更快更紧凑,但Spark默认的序列化是Java序列化并不是Kryo序列化,因为Spark并不支持所有序列化类型,而且每次使用都必须进行注册。注册只针对于RDD。在DataFrames和DataSet当中自动实现了Kryo序列化。
48、Spark分区
1)默认采用Hash分区
缺点:可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有RDD的全部数据。
2)Ranger分区
要求RDD中的KEY类型必须可以排序。
3)自定义分区
根据需求,自定义分区。
49、SparkSQL中RDD、DataFrame、DataSet三者的转换
50、当Spark涉及到数据库的操作时,如何减少Spark运行中的数据库连接数?
使用foreachPartition代替foreach,在foreachPartition内获取数据库的连接。
51、Spark Shuffle默认并行度
参数spark.sql.shuffle.partitions 决定 默认并行度200
52、控制Spark reduce缓存 调优shuffle
spark.reducer.maxSizeInFilght :此参数为reduce task能够拉取多少数据量的一个参数默认48MB,当集群资源足够时,增大此参数可减少reduce拉取数据量的次数,从而达到优化shuffle的效果,一般调大为96MB,,资源够大可继续往上调。
spark.shuffle.file.buffer :此参数为每个shuffle文件输出流的内存缓冲区大小,调大此参数可以减少在创建shuffle文件时进行磁盘搜索和系统调用的次数,默认参数为32k,一般调大为64k。
53、Spark Streaming第一次运行不丢失数据
kafka参数 auto.offset.reset 参数设置成earliest 从最初始偏移量开始消费数据
54、Spark Streaming精准一次消费
- 手动维护偏移量
- 处理完业务数据后,再进行提交偏移量操作
极端情况下,如在提交偏移量时断网或停电会造成spark程序第二次启动时重复消费问题,所以在涉及到金额或精确性非常高的场景会使用事物保证精准一次消费
55、Spark Streaming控制每秒消费数据的速度
通过spark.streaming.kafka.maxRatePerPartition参数来设置Spark Streaming从kafka分区每秒拉取的条数
56、Spark Streaming背压机制
把spark.streaming.backpressure.enabled 参数设置为ture,开启背压机制后Spark Streaming会根据延迟动态去kafka消费数据,上限由spark.streaming.kafka.maxRatePerPartition参数控制,所以两个参数一般会一起使用。
57、Spark Streaming一个stage耗时
Spark Streaming stage耗时由最慢的task决定,所以数据倾斜时某个task运行慢会导致整个Spark Streaming都运行非常慢。
58、Spark Streaming优雅关闭
把spark.streaming.stopGracefullyOnShutdown参数设置成ture,Spark会在JVM关闭时正常关闭StreamingContext,而不是立马关闭
Kill 命令:yarn application -kill 后面跟 applicationid
59、Spark Streaming默认分区个数
Spark Streaming默认分区个数与所对接的kafka topic分区个数一致,Spark Streaming里一般不会使用repartition算子增大分区,因为repartition会进行shuffle增加耗时。
60、SparkStreaming有哪几种方式消费Kafka中的数据,它们之间的区别是什么?
一、基于Receiver的方式
这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的(如果突然数据暴增,大量batch堆积,很容易出现内存溢出的问题),然后Spark Streaming启动的job会去处理那些数据。
然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
二、基于Direct的方式
这种新的不基于Receiver的直接方式,是在Spark 1.3中引入的,从而能够确保更加健壮的机制。替代掉使用Receiver来接收数据后,这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
优点如下:
简化并行读取:如果要读取多个partition,不需要创建多个输入DStream然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
高性能:如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复制一份到WAL中。而基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。
一次且仅一次的事务机制。
三、对比:
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
在实际生产环境中大都用Direct方式
61、简述SparkStreaming窗口函数的原理
窗口函数就是在原来定义的SparkStreaming计算批次大小的基础上再次进行封装,每次计算多个批次的数据,同时还需要传递一个滑动步长的参数,用来设置当次计算任务完成之后下一次从什么地方开始计算。
62、Spark 数据倾斜的解决方案
1.使用Hive ETL预处理数据
2.过滤少数导致倾斜的key
3.提高shuffle操作的并行度
4.两阶段聚合(局部聚合+全局聚合)
5.将reduce join转为map join
6.采样倾斜key并分拆join操作
7.使用随机前缀和扩容RDD进行join
8.上述多种方案组合使用
63、简单介绍一下 Flink?
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。并且 Flink 提供了数据分布、容错机制以及资源管理等核心功能。Flink提供了诸多高抽象层的API以便用户编写分布式任务:
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
此外,Flink 还针对特定的应用领域提供了领域库,例如: Flink ML,Flink 的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。 Gelly,Flink 的图计算库,提供了图计算的相关API及多种图计算算法实现。
64、Flink跟Spark Streaming的区别
Flink 是标准的实时处理引擎,基于事件驱动。而 Spark Streaming 是微批(Micro-Batch)的模型。
下面我们就分几个方面介绍两个框架的主要区别:
1)架构模型Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor,Flink 在运行时主要包含:Jobmanager、Taskmanager和Slot。
2)任务调度Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图DAG,Spark Streaming 会依次创建 DStreamGraph、JobGenerator、JobScheduler。Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
3)时间机制Spark Streaming 支持的时间机制有限,只支持处理时间。 Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。
4)容错机制对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰好一次处理语义。Flink 则使用两阶段提交协议来解决这个问题。
65、Flink集群有哪些角色?各自有什么作用?
Flink程序在运行时主要有TaskManager,JobManager,Client三种角色。
JobManager:扮演着集群中的管理者Master的角色,它是整个集群的协调者,负责接收Flink Job,协调检查点,Failover 故障恢复等,同时管理Flink集群中从节点TaskManager。
TaskManager:是实际负责执行计算的Worker,在其上执行Flink Job的一组Task,每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。
Client:是Flink程序提交的客户端,当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。
66、公司怎么提交的实时任务,有多少Job Manager? 有多少TaskManager?
1)我们使用yarn per-job模式提交任务
2)集群默认只有一个 Job Manager。但为了防止单点故障,我们配置了高可用。对于standlone模式,我们公司一般配置一个主 Job Manager,两个备用 Job Manager,然后结合 ZooKeeper 的使用,来达到高可用;对于yarn模式,yarn在Job Mananger故障会自动进行重启,所以只需要一个,我们配置的最大重启次数是10次。
3)基于yarn,动态申请TaskManager的数量
67、Flink的并行度了解吗?Flink的并行度设置是怎样的?
Flink中的任务被分为多个并行任务来执行,其中每个并行的实例处理一部分数据。这些并行实例的数量被称为并行度。我们在实际生产环境中可以从四个不同层面设置并行度:
操作算子层面(Operator Level)
执行环境层面(Execution Environment Level)
客户端层面(Client Level)
系统层面(System Level)
需要注意的优先级:算子层面>环境层面>客户端层面>系统层面。
68、Flink的keyby怎么实现的分区?分区、分组的区别是什么?
Keyby实现原理:
对指定的key调用自身的hashCode方法=》hash1
调用murmruhash算法,进行第二次hash =》键组ID
通过一个公式,计算出当前数据应该去往哪个下游分区:
键组id * 下游算子并行度 / 最大并行度(默认128)
分区:算子的一个并行实例可以理解成一个分区,是物理上的资源
分组:数据根据key进行区分,是一个逻辑上的划分
一个分区可以有多个分组,同一个分组的数据肯定在同一个分区
69、Flink的interval join的实现原理?join不上的怎么办?
底层调用的是keyby+connect ,处理逻辑:
1)判断是否迟到(迟到就不处理了)
2)每条流都存了一个Map类型的状态(key是时间戳,value是List存数据)
3)任一条流,来了一条数据,遍历对方的map状态,能匹配上就发往join方法
4)超过有效时间范围,会删除对应Map中的数据(不是clear,是remove)
Interval join不会处理join不上的数据,如果需要没join上的数据,可以用 coGroup+connect算子实现,或者直接使用flinksql里的left join或right join语法。
70、介绍一下Flink的状态编程、状态机制?
算子状态:作用范围是算子,算子的多个并行实例各自维护一个状态
键控状态:每个分组维护一个状态
状态后端:两件事=》 本地状态存哪里、checkpoint存哪里
本地状态 Checkpoint
内存 TaskManager的内存 JobManager内存
文件 TaskManager的内存 HDFS
RocksDB RocksDB HDFS
71、Flink的三种时间语义
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
Ingestion Time:是数据进入Flink的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
72、Flink 中的Watermark机制
1)Watermark 是一种衡量 Event Time 进展的机制,可以设定延迟触发
2)Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark 机制结合 window 来实现;
3)基于事件时间,用来触发窗口、定时器等
4)watermark主要属性就是时间戳,可以理解一个特殊的数据,插入到流里面
5)watermark是单调不减的
6)数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,如果后续还有timestamp 小于 Watermark 的数据到达,称为迟到数据
73、Watermark是数据吗?怎么生成的?怎么传递的?
Watermark是一条携带时间戳的特殊数据,从代码指定生成的位置,插入到流里面。
一对多:广播
多对一:取最小
多对多:拆分来看,其实就是上面两种的结合
74、Watermark的生成方式?
间歇性:来一条数据,更新一次watermark
周期性:固定周期更新watermark
官方提供的api是基于周期的,默认200ms,因为间歇性会给系统带来压力。
Watermark=当前最大事件时间-乱序时间-1ms
75、说说Flink中的窗口(分类、生命周期、触发、划分)
1)窗口分类: Keyed Window和Non-keyed Window
基于时间:滚动、滑动、会话
基于数量:滚动、滑动
2)Window口的4个相关重要组件:
assigner(分配器):如何将元素分配给窗口
function(计算函数):为窗口定义的计算。其实是一个计算函数,完成窗口内容的计算。
triger(触发器):在什么条件下触发窗口的计算
evictor(退出器):定义从窗口中移除数据
3)窗口的划分:如,基于事件时间的滚动窗口
start=按照数据的事件时间向下取窗口长度的整数倍
end=start+size
比如开了一个10s的滚动窗口,第一条数据是857s,那么它属于[850s,860s)
4)窗口的创建:当属于某个窗口的第一个元素到达,Flink就会创建一个窗口,
5)窗口的销毁:当时间超过其结束时间+用户指定的允许延迟时间(Flink保证只删除基于时间的窗口,而不能删除其他类型的窗口,例如全局窗口)。
6)窗口为什么左闭右开:属于窗口的最大时间戳=end-1ms
7)窗口什么时候触发:如基于事件时间的窗口 watermark>=end-1ms
76、Exactly-Once的保证
一般说的是端到端一致性,要考虑source和sink:
Source:可重发
Flink内部:Checkpoint机制(介绍Chandy-Lamport算法、barrier对齐)
Sink:幂等性 或 事务性 写入
我们使用的Source和Sink主要是Kafka:
作为source可以重发,由Flink维护offset,作为状态存储
作为sink官方的实现类是基于两阶段提交,能保证写入的Exactly-Once
如果下级存储不支持事务:
具体实现是幂等写入,需要下级存储具有幂等性写入特性。
比如结合HBase的rowkey的唯一性、数据的多版本,实现幂等
77、Flink分布式快照的原理是什么?
Flink的容错机制的核心部分是制作分布式数据流和操作算子状态的一致性快照。 这些快照充当一致性checkpoint,系统可以在发生故障时回滚。 Flink用于制作这些快照的机制在“分布式数据流的轻量级异步快照”中进行了描述。 它受到分布式快照的标准Chandy-Lamport算法的启发,专门针对Flink的执行模型而定制。
barriers在数据流源处被注入并行数据流中。快照n的barriers被插入的位置(我们称之为Sn)是快照所包含的数据在数据源中最大位置。
例如,在Apache Kafka中,此位置将是分区中最后一条记录的偏移量。 将该位置Sn报告给checkpoint协调器(Flink的JobManager)。
然后barriers向下游流动。当一个中间操作算子从其所有输入流中收到快照n的barriers时,它会为快照n发出barriers进入其所有输出流中。
一旦sink操作算子(流式DAG的末端)从其所有输入流接收到barriers n,它就向checkpoint协调器确认快照n完成。
在所有sink确认快照后,意味快照着已完成。一旦完成快照n,job将永远不再向数据源请求Sn之前的记录,因为此时这些记录(及其后续记录)将已经通过整个数据流拓扑,也即是已经被处理结束。
78、Checkpoint的参数怎么设置的?
1)间隔、语义: 1min~10min,3min,语义默认精准一次
因为一些异常原因可能导致某些barrier无法向下游传递,造成job失败,对于一些时效性要求高、精准性要求不是特别严格的指标,可以设置为至少一次。
2)超时 : 参考间隔, 0.5~2倍之间, 建议0.5倍
3)最小等待间隔:上一次ck结束 到 下一次ck开始 之间的时间间隔,设置间隔的0.5倍
4)设置保存ck:Retain
5)失败次数:5
6)Task重启策略(Failover):
固定延迟重启策略: 重试几次、每次间隔多久
失败率重启策略: 重试次数、重试区间、重试间隔
79、介绍一下Flink的CEP机制
CEP全称为Complex Event Processing,复杂事件处理
Flink CEP是在 Flink 中实现的复杂事件处理(CEP)库
CEP 允许在无休止的事件流中检测事件模式,让我们有机会掌握数据中重要的部分
一个或多个由简单事件构成的事件流通过一定的规则匹配,然后输出用户想得到的数据 —— 满足规则的复杂事件
80、Flink CEP 编程中当状态没有到达的时候会将数据保存在哪里?
在流式处理中,CEP 当然是要支持 EventTime 的,那么相对应的也要支持数据的迟到现象,也就是watermark的处理逻辑。CEP对未匹配成功的事件序列的处理,和迟到数据是类似的。在 Flink CEP的处理逻辑中,状态没有满足的和迟到的数据,都会存储在一个Map数据结构中,也就是说,如果我们限定判断事件序列的时长为5分钟,那么内存中就会存储5分钟的数据,这在我看来,也是对内存的极大损伤之一。
81、Flink SQL的工作机制?
1)在Table/SQL 编写完成后,通过Calcite 中的parse、validate、rel阶段,以及Blink额


