Elasticsearch集群的搭建与管理
时间:2023-09-23 17:37:01
主机规划:
-
192.168.0.1(node1)
-
192.168.0.2(node2)
部署node1
node1配置如下:
下载https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.15.2-linux-x86_64.tar.gz后,解压。
在config/jvm.options文件中增加如下内容:
-Xms1g -Xmx1g 在config/elasticsearch.yml在文件中添加以下内容:
network.host: 192.168.0.1 discovery.seed_hosts: ["192.168.0.1"] 创建es用户,不能使用root用户运行,否则会报错:
groupadd es useradd es -g es -p es chown -R es:es /data/soft/elasticsearch-7.15.2 启动node1:sudo -u es bin/elasticsearch -d
启动后,我们来看看当前集群的状态:
$ curl 192.168.0.1:9200/_cluster/state/master_node,nodes?pretty {
"cluster_name" : "elasticsearch", "cluster_uuid" : "PyE4PgLaQn698Oi4b8gXyQ", "master_node" : "W8ACq9LrTLWj0PCq7Sb2qQ", "nodes" : {
"W8ACq9LrTLWj0PCq7Sb2qQ" : {
"name" : "node1", "ephemeral_id" : "J89TeHYAQ76VgslQdtTRNQ", "transport_address" : "192.168.0.1:9300", "attributes" : {
"ml.machine_memory" : "16827039744", "xpack.installed" : "true", "transform.node" : "true", "ml.max_open_jobs" : "512", "ml.max_jvm_size" : "1073741824" }, "roles" : [ "data", "data_cold", "data_content", "data_frozen", "data_hot", "data_warm", "ingest", "master", "ml", "remote_cluster_client", "transform" ] } } } 目前集群中只有一个节点。
node2的部署
其他配置node同样,主要修改是config/elasticsearch.yml在文件中添加以下内容:
network.host: 192.168.0.2
discovery.seed_hosts: ["192.168.0.1", "192.168.0.2"]
启动node2后再来看一下目前集群的状态:
$ curl 192.168.0.1:9200/_cluster/state/master_node,nodes?pretty
{
"cluster_name" : "elasticsearch",
"cluster_uuid" : "PyE4PgLaQn698Oi4b8gXyQ",
"master_node" : "W8ACq9LrTLWj0PCq7Sb2qQ",
"nodes" : {
"80jV8x3AQfKDRjTubn9wmw" : {
"name" : "node2",
"ephemeral_id" : "QOlP9iIrTOS5PvmQLZ73Ug",
"transport_address" : "192.168.0.2:9300",
"attributes" : {
"ml.machine_memory" : "16657477632",
"ml.max_open_jobs" : "512",
"xpack.installed" : "true",
"ml.max_jvm_size" : "1073741824",
"transform.node" : "true"
},
"roles" : [
"data",
"data_cold",
"data_content",
"data_frozen",
"data_hot",
"data_warm",
"ingest",
"master",
"ml",
"remote_cluster_client",
"transform"
]
},
"W8ACq9LrTLWj0PCq7Sb2qQ" : {
"name" : "node1",
"ephemeral_id" : "J89TeHYAQ76VgslQdtTRNQ",
"transport_address" : "192.168.0.1:9300",
"attributes" : {
"ml.machine_memory" : "16827039744",
"xpack.installed" : "true",
"transform.node" : "true",
"ml.max_open_jobs" : "512",
"ml.max_jvm_size" : "1073741824"
},
"roles" : [
"data",
"data_cold",
"data_content",
"data_frozen",
"data_hot",
"data_warm",
"ingest",
"master",
"ml",
"remote_cluster_client",
"transform"
]
}
}
}
可以发现目前集群中已经有两个节点了。
集群的状态
集群的状态有以下三种:
- green:每个索引的primary shard和replica shard都是active状态的
- yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
- red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
先kill node2。
向es集群中创建一个索引:test_index,指定主分片为1个。
put test_index
{
"settings": {
"index.number_of_shards": 1
}
}
此时查询集群的监控状态为yellow:
GET /_cluster/health
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 8,
"active_shards" : 8,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 1,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 88.88888888888889
}
说明不是所有的replica shard都是active状态,那么是哪些索引的replica shard不都是active状态呢?
get /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .geoip_databases hnmSnA4tRSq_G-47xQwKqw 1 0 42 0 40.8mb 40.8mb
green open .apm-custom-link z6Kqz0vvSgu5wBD8VsGTQA 1 0 0 0 208b 208b
green open .kibana-event-log-7.15.2-000001 GMwxpEPhSAW0lTvPFiKXZA 1 0 1 0 6kb 6kb
green open .apm-agent-configuration mlmNrXCbSo2-DxDEKAezRQ 1 0 0 0 208b 208b
green open .kibana_7.15.2_001 TTnby0q2TaSijbqFyX5Jiw 1 0 34 13 2.3mb 2.3mb
yellow open test_index VE42lYQrTSCj2mAMy8A5gw 1 1 0 0 208b 208b
green open .kibana_task_manager_7.15.2_001 -fIXfz8-QYmgOXVCDKypZA 1 0 15 609 135kb 135kb
可以发现导致整个机器变为yellow的索引是刚刚创建的索引test_index。
为什么现在会处于一个yellow状态?因为我们创建的test_index是1个primary shard和1个replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动(primary shard与replica shard不能分配在同一个节点上)。
当启动完node2后,集群的状态又变为green了。
新增节点分片如何运作
当只启动node1时,test_index索引的主分片全部分配到节点node1.,而副本分片分配没有地方分配。在这种状态下,集群是黄色的,因为所有的主分片有了安家之处,但是副本分片还没有。
一旦第二个节点加入,尚未分配的副本分片就会分配到新的节点node2,这使得集群变为了绿色的状态。当另一个节点加入的时候,Elasticsearch会自动地尝试将分片在所有节点上进行均匀分配。
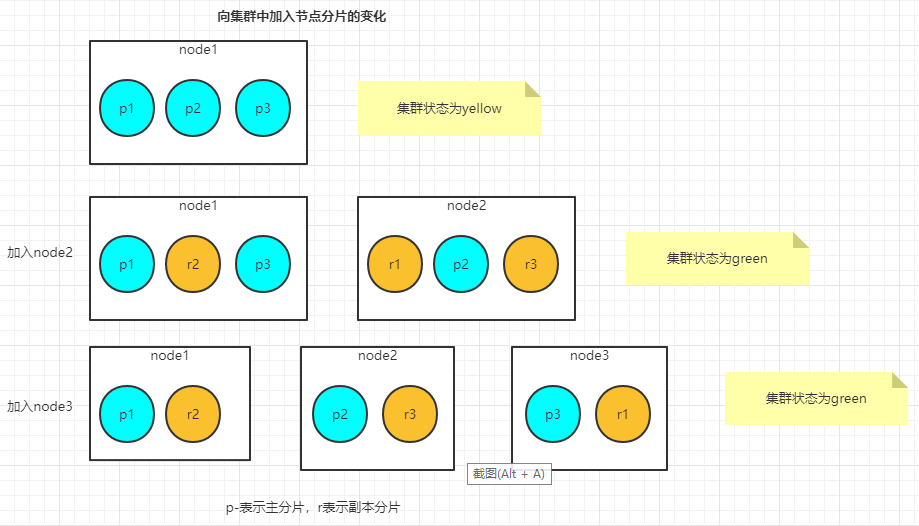
如果更多的节点加入集群,Elasticsearch将试图在所有的节点上均匀地配置分片数量,这样每个新加入的节点都能够通过部分数据(以分片的形式)来分担负载。
将节点加入Elasticsearch集群带来了大量的好处,主要的收益是高可用性和提升的性能。当副本分片是激活状态时(默认情况下是激活的),如果无法找到主分片,Elasticsearch会自动地将一个对应的副本分片升级为主分片。这样,即使失去了索引主分片所在的节点,仍然可以访问副本分片上的数据。数据分布在多个节点上同样提升了性能,原因是主分片和副本分片都可以处理搜索和获取结果的请求。如此扩展还为整体集群增加了更多的内存,所以如果过于消耗内存的搜索和聚集运行了太长时间或致使集群耗尽了内存,那么加入更多的节点总是一个处理更多更复杂操作的便捷方式。
如何发现其他ES节点
集群的第二个节点是如何发现第一个节点、并自动地加入集群的,或者在集群中有更多的节点的情况下,如何知道?Elasticsearch 7.0中引入的新集群协调子系统来处理这些事,采用的是单播机制,这种机制需要已知节点的列表来进行连接。
单播发现(unicast discovery)让Elasticsearch连接一系列的主机,并试图发现更多关于集群的信息。使用单播时,我们告诉Elasticsearch集群中其他节点的IP地址以及(可选的)端口或端口范围。
在elasticsearch.yml中通过discovery.seed_hosts配置种子地址列表,这样每个节点在启动时发现和加入集群的步骤就是:
- 去连接种子地址列表中的主机,如果发现某一个Node是Master Eligible Node,那么该Master Eligible Node会共享它知道的Master Eligible Node,这些共享的Master Eligible Node也会作为种子地址的一部分继续去试探;
- 直到找到某一个seed addresss对应的是Master Node为止;
- 如果第二步没有找到任何满足条件的Node,ES会默认每隔1秒后去重新尝试寻找,默认为1秒
- 重复第三步操作直到找到满足条件为止,也就是直到最终发现集群中的主节点,会发出一个加入请求给主节点
- 获得整个集群的状态信息。
为什么实例需要知道集群状态信息?例如,搜索必须被路由到所有正确的分片,以确保搜索结果是准确的。在索引或删除某些文档时,必须更新每个副本。每个客户端请求都必须从接收它的节点转发到能够处理它的节点。每个节点都了解集群的概况,这样它们就可以执行搜索、索引和其他协调活动。discovery.seed_hosts中的节点地址列表,可以包括集群中部分或者全部集群节点,但是建议无论怎样都应该包含集群中Master-eligible nodes节点的部分或者全部。
选举主节点
一旦集群中的节点发现了彼此,它们会协商谁将成为主节点。一个集群有一个稳定的主节点是非常重要的,主节点是唯一一个能够更新集群状态的节点。主节点一次处理一个群集状态更新,应用所需的更改并将更新的群集状态发布到群集中的所有其他节点。
Elasticsearch认为所有的节点都有资格成为主节点,除非某个节点的node.master选项设置为false,而node.master在不做配置的情况下,缺省为true。如果完全使用默认配置启动新安装的Elasticsearch节点,它们会自动查找在同一主机上运行的其他节点,并在几秒钟内形成集群。在生产环境或其他分布式环境中还不够健壮。现在还存在一些风险:节点可能无法及时发现彼此,可能会形成两个或多个独立的集群。从Elasticsearch 7.0开始,如果你想要启动一个全新的集群,并且集群在多台主机上都有节点,那么你必须指定该集群在第一次选举中应该使用的一组符合主节点条件的节点作为选举配置。这就是所谓的集群引导,也可以称为集群自举,只在首次形成集群时才需要。cluster.initial_master_nodes这个参数就是用来设置一系列符合主节点条件的节点的主机名或IP地址来进行集群自举。集群形成后,不再需要此设置,并且会忽略它,也就是说,这个属性就只是在集群首次启动时有用。
在向集群添加新的符合主节点条件的节点时不再需要任何特殊的仪式,只需配置新节点,让它们可以发现已有集群,并启动它们。当有新节点加入时,集群将会自动地调整选举配置。在主节点被选举出来之后,它会建立内部的ping机制来确保每个节点在集群中保持活跃和健康,这被称为错误识别(fault detection),有两个故障检测进程在集群的生命周期中一直运行。一个是主节点的,ping集群中所有的其他节点,检查他们是否活着。另一种是每个节点都ping主节点,确认主节点是否仍在运行或者是否需要重新启动选举程序。
删除集群中的节点
添加节点是扩展的好方法,但是如果Elasticsearch集群中的一个节点掉线了或者被停机了,那又会发生什么呢?
这里使用上图中3个节点的集群为例,假设节点1宕机了,集群容错的步骤如下:
- 集群状态变为red,因为不是所有的primary shard都是active
- 将丢失的primary shard的某个replica shard升级为primary shard,集群状态变为yellow,此时所有的primary shard都是active,不是所有的replica shard都是active
- 从新的p1创建新的副本r1,集群状态变为green
注意Elasticsearch可以选择任一个副本分片并将其转变为主分片。只是在本例中每个主分片仅有一个副本分片供选择,就是节点node3上的副本分片。如果失去的节点多于1个,或者某个没有副本的主分片丢失了,那么集群就会变为红色的状态,这意味着某些数据永远地丢失了,你需要让集群重连拥有丟失数据的节点,或者对丢失的数据重新建立索引。
停用节点
当节点宕机时,让Elasticsearch自动地创建新副本分片是很棒的选择。可是,当集群进行例行维护的时候,你总是希望关闭某个包含数据的节点,而同时不让集群进人黄色的状态。也许硬件过于老旧,或者处理的请求流量有所下降,总之你不再需要这么多节点了。可以通过杀掉Java进程来停止节点,然后让Elasticsearch将数据恢复到其他节点,但是如果你的索引没有副本分片的时候怎么办?这意味着,如果不预先将数据转移,关闭节点就会让你丢失数据!
值得庆幸的是,Elasticsearch有一种停用节点(decommission)的方式,告诉集群不要再分配任何分片到某个或1组节点上。在3个节点的例子中,假设节点1、节点2和节点3的IP地址分别是192.168.1.10、192.168.1.11和192.168.1.12。
如果你想关闭节点1的同时保持集群为绿色状态,可以先停用节点,这个操作会将待停用节点上的所有分片转移到集群中的其他节点。系统通过集群设置的临时修改,来为你实现节点的停用,
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._name": "node-1"
}
}
或者:
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._ip": "192.168.1.10"
}
}
一旦运行了这个命令,Elaticsearch将待停用节点上的全部分片开始转移到集群中的其他节点上。
该过程可以重复,每次停止一个你想关闭的节点,或者也可以使用一个通过逗号分隔的IP地址列表,一次停止多个节点。请记住,集群中的其他节点必须有足够的磁盘和内存来处理分片的分配,所以在停止多个节点之前,做出相应的计划来确保你有足够的资源。
扩展策略
将节点加入集群以增加性能,看上去很简单,但是稍微做些计划会使得你在获取集群最佳性能的这条道路上走得更远。
Elasticsearch的使用方式各有各的不同,所以需要根据如何索引和搜索数据,为集群选择最佳的配置。通常来说,规划生产环境的Elasticsearch集群至少需要考虑:过度分片、将数据切分为索引和分片。
过度分片
过度分片(over-sharding)是指你有意地为索引创建大量分片,用于未来增加节点的过程。假设我们已经创建了拥有单一分片、无副本分片的索引。但是,在增加了另外一个节点之后又会发生什么?
我们将得不到增加集群节点所带来的任何好处了。由于全部的索引和查询负载仍然是由拥有单一分片的节点所处理,所以即使增加了一个节点你也无法进行扩展。
因为分片是Elasticsearch所能移动的最小单位,所以确保你至少拥有和集群节点一样多的主分片总是个好主意。如果现在有一个5个节点、11个主分片的集群,那么当你需要加入更多的节点来处理额外的请求时,就有成长的空间。使用同样的例子,如果你突然需要多于11个的节点,就不能在所有的节点中分发主分片,因为节点的数量将会超出分片的数量。
怎么办?创建一个有10000个主分片的索引?一开始的时候,这看上去是个好主意,但是Elasticsearch管理每个分片都隐含着额外的开销。每个分片都是完整的Lucene索引,它需要为索引的每个分段创建一些文件描述符,增加相应的内存开销。如果索引有过多的活跃分片,可能会占用了本来支撑性能的内存,或者触及机器文件描述符或内存的极限。对数据的压缩上也会有影响。
值得注意的是,没有对所有案例适用的完美分片索引比例。Elasticsearch选择的默认设置是5个分片,对于普通的用例是不错的主意,但是考虑你的规划在将来是如何增长(或缩减)所建分片的数量,这总是很件重要的事情。
不要忘记:一旦包含某些数量分片的索引被创建,其主分片的数量永远是不能改变的。
Elasticsearch索引能处理多大的数据
单一索引的极限取决于存储索引的机器之类型、你准备如何处理数据以及索引备份了多少副本。
如何评估ES中的数据量是否合适呢?有几个参考值:
- ES官方推荐分片的大小是20G-40G,最大不能超过50G。
- 每个节点上可以存储的分片数量与可用的堆内存大小成正比关系,但是Elasticsearch并未强制规定固定限值。这里有一个很好的经验法则:确保对于节点上已配置的每个GB,将分片数量保持在20以下。如果某个节点拥有3GB的堆内存,那最多可有60个分片,那么有三个机器的集群,ES可用总堆内存是9GB,则最多是180个分片,注意这个数据是包含了主副分片的。但是在此限值范围内,设置的分片数量越少,效果就越好。
- 通常来说,一个Lucene索引(也就是一个Elasticsearch分片)不能处理多于21亿篇文档,或者多于2740亿的唯一词条, 但是在达到这个极限之前,你可能就已经没有足够的磁盘空间了。
举例:三个机器的集群,总内存是9GB,准备1主2副,支持的总主分片数量最大不宜超过60个分片。
将数据切分为索引和分片
现在还没有方法让我们增加或者减少某个索引中的主分片数量,但是你总是可以对数据进行规划,让其横跨多个索引。这是另一种完全合理的切分数据的方式。
比如说以地理位置创建索引和分片,你可以为西藏索引创建2个主分片,而为上海索引创建10个主分片,或者可以将数据以日期来分段,为数据按年份创建索引:2019、2020和2021等。以这种方式将数据分段,对于搜索同样有所帮助,因为分段将恰当的数据放在恰当的位置。如果顾客只希望搜索2019年和2020年的活动或分组,你只需要搜索相应的索引,而不是整个数据集中检索。
使用索引进行规划的另一种方式是别名。别名(alias)就像指向某个索引或一组索引的指针。别名也允许你随时修改其所指向的索引。对于数据按照语义的方式来切分,这一点非常有用。你可以创建一个别名称为去年,指向2019,当2021年1 月1日到来,就可以将这个别名指向2020年的索引。
当索引基于日期的信息时(就像日志文件),这项技术是很常用的,如此一来数据就可以按照每月、每周、每日等日期来分段,而每次分段过时的时候,“当前”的别名永远可用来指向应该被搜索的数据,而无须修改待搜索的索引之名称。
此外,别名拥有惊人的灵活性,而且几乎没有额外负载,所以值得尝试。


