Python深度学习-快速指南
时间:2023-07-20 17:37:00
Python深度学习-快速指南 (Python Deep Learning - Quick Guide)
Python深度学习-简介 (Python Deep Learning - Introduction)
Deep structured learning or hierarchical learning or deep learning in short is part of the family of machine learning methods which are themselves a subset of the broader field of Artificial Intelligence.
深度结构化学习或分层学习或简称深度学习是机器学习方法家族的一部分,机器学习方法本身是人工智能领域更广泛的子集。
Deep learning is a class of machine learning algorithms that use several layers of nonlinear processing units for feature extraction and transformation. Each successive layer uses the output from the previous layer as input.
深度学习是一种机器学习算法,它使用几层非线性处理单元来提取和转换特征。 每个后续层都使用前一层的输出作为输入。
Deep neural networks, deep belief networks and recurrent neural networks have been applied to fields such as computer vision, speech recognition, natural language processing, audio recognition, social network filtering, machine translation, and bioinformatics where they produced results comparable to and in some cases better than human experts have.
深度神经网络、深度信念网络和递归神经网络已应用于计算机视觉、语音识别、自然语言处理、音频识别、社交网络过滤、机器翻译和生物信息学,在某些情况下优于人类专家。
Deep Learning Algorithms and Networks ?
算法和网络的深度学习-
are based on the unsupervised learning of multiple levels of features or representations of the data. Higher-level features are derived from lower level features to form a hierarchical representation.
基于无监督学习数据的多层次特征或表达形式。 较高级别的功能来自较低级别的功能,形成层次表示。
use some form of gradient descent for training.
训练采用某种形式的梯度下降。
Python深度学习-环境 (Python Deep Learning - Environment)
In this chapter, we will learn about the environment set up for Python Deep Learning. We have to install the following software for making deep learning algorithms.
本章将学习为Python设置深度学习环境。 深度学习算法必须安装以下软件。
- Python 2.7 Python 2.7以上
- Scipy with Numpy 脾气暴躁的西皮
- Matplotlib Matplotlib
- Theano 茶野
- Keras 凯拉斯
- TensorFlow TensorFlow
It is strongly recommend that Python, NumPy, SciPy, and Matplotlib are installed through the Anaconda distribution. It comes with all of those packages.
强烈建议通过Anaconda发行版安装Python,NumPy,SciPy和Matplotlib。 它包含了所有这些软件包。
We need to ensure that the different types of software are installed properly.
我们需要确保不同类型的软件安装正确。
Let us go to our command line program and type in the following command ?
让我们进入命令行程序,输入以下命令-
$ python Python 3.6.3 |Anaconda custom (32-bit)| (default, Oct 13 2017, 14:21:34) [GCC 7.2.0] on linux Next, we can import the required libraries and print their versions ?
接下来,我们可以导入所需的库并打印其版本-
import numpy print numpy.__version__ 输出量 (Output)
1.14.2 安装Theano,TensorFlow和Keras (Installation of Theano, TensorFlow and Keras)
Before we begin with the installation of the packages ? Theano, TensorFlow and Keras, we need to confirm if the pip is installed. The package management system in Anaconda is called the pip.
软件包开始安装-Theano,TensorFlow和Keras在此之前,我们需要确认是否已安装pip 。 Anaconda包裹管理系统称为包裹管理系统pip。
To confirm the installation of pip, type the following in the command line ?
要确认pip请在命令行中键入以下安装内容-
$ pip Once the installation of pip is confirmed, we can install TensorFlow and Keras by executing the following command ?
确认安装了pip之后,我们可以通过执行以下命令来安装TensorFlow和Keras-
$pip install theano $pip install tensorflow $pip install keras Confirm the installation of Theano by executing the following line of code ?
通过执行以下代码来确认Theano的安装-
$python –c “import theano: print (theano.__version__)” 输出量 (Output)
1.0.1Confirm the installation of Tensorflow by executing the following line of code −
通过执行以下代码行来确认Tensorflow的安装-
$python –c “import tensorflow: print tensorflow.__version__”输出量 (Output)
1.7.0Confirm the installation of Keras by executing the following line of code −
通过执行以下代码行来确认Keras的安装-
$python –c “import keras: print keras.__version__” Using TensorFlow backend输出量 (Output)
2.1.5Python深度基础机器学习 (Python Deep Basic Machine Learning)
Artificial Intelligence (AI) is any code, algorithm or technique that enables a computer to mimic human cognitive behaviour or intelligence. Machine Learning (ML) is a subset of AI that uses statistical methods to enable machines to learn and improve with experience. Deep Learning is a subset of Machine Learning, which makes the computation of multi-layer neural networks feasible. Machine Learning is seen as shallow learning while Deep Learning is seen as hierarchical learning with abstraction.
人工智能(AI)是使计算机能够模仿人类认知行为或智力的任何代码,算法或技术。 机器学习(ML)是AI的子集,它使用统计方法来使机器学习并根据经验进行改进。 深度学习是机器学习的一个子集,它使多层神经网络的计算变得可行。 机器学习被视为浅层学习,而深度学习被视为具有抽象的分层学习。
Machine learning deals with a wide range of concepts. The concepts are listed below −
机器学习涉及各种各样的概念。 概念在下面列出-
- supervised 监督的
- unsupervised 无监督
- reinforcement learning 强化学习
- linear regression 线性回归
- cost functions 成本函数
- overfitting 过度拟合
- under-fitting 不合身
- hyper-parameter, etc. 超参数等
In supervised learning, we learn to predict values from labelled data. One ML technique that helps here is classification, where target values are discrete values; for example,cats and dogs. Another technique in machine learning that could come of help is regression. Regression works onthe target values. The target values are continuous values; for example, the stock market data can be analysed using Regression.
在监督学习中,我们学习根据标记数据预测值。 分类法,其中目标值是离散值,这是帮助ML的一种技术。 例如猫和狗。 机器学习中的另一种可能会带来帮助的技术是回归。 回归适用于目标值。 目标值是连续值。 例如,可以使用回归分析股市数据。
In unsupervised learning, we make inferences from the input data that is not labelled or structured. If we have a million medical records and we have to make sense of it, find the underlying structure, outliers or detect anomalies, we use clustering technique to divide data into broad clusters.
在无监督学习中,我们从未标记或未结构化的输入数据中进行推断。 如果我们有一百万条医疗记录,并且我们必须弄清楚它,发现底层结构,离群值或检测异常,则可以使用聚类技术将数据划分为广泛的聚类。
Data sets are divided into training sets, testing sets, validation sets and so on.
数据集分为训练集,测试集,验证集等。
A breakthrough in 2012 brought the concept of Deep Learning into prominence. An algorithm classified 1 million images into 1000 categories successfully using 2 GPUs and latest technologies like Big Data.
2012年的一项突破使深度学习的概念倍受关注。 该算法使用2个GPU和最新技术(例如大数据)成功地将100万张图像分类为1000个类别。
深度学习与传统机器学习的关系 (Relating Deep Learning and Traditional Machine Learning)
One of the major challenges encountered in traditional machine learning models is a process called feature extraction. The programmer needs to be specific and tell the computer the features to be looked out for. These features will help in making decisions.
传统机器学习模型中遇到的主要挑战之一是称为特征提取的过程。 程序员需要具体说明并告诉计算机要注意的功能。 这些功能将有助于做出决策。
Entering raw data into the algorithm rarely works, so feature extraction is a critical part of the traditional machine learning workflow.
将原始数据输入算法很少,因此特征提取是传统机器学习工作流程的关键部分。
This places a huge responsibility on the programmer, and the algorithm's efficiency relies heavily on how inventive the programmer is. For complex problems such as object recognition or handwriting recognition, this is a huge issue.
这给程序员带来了巨大的责任,算法的效率在很大程度上取决于程序员的创造力。 对于诸如对象识别或手写识别之类的复杂问题,这是一个巨大的问题。
Deep learning, with the ability to learn multiple layers of representation, is one of the few methods that has help us with automatic feature extraction. The lower layers can be assumed to be performing automatic feature extraction, requiring little or no guidance from the programmer.
能够学习多层表示的深度学习是帮助我们进行自动特征提取的少数几种方法之一。 可以假设较低的层正在执行自动特征提取,几乎不需要程序员的指导。
人工神经网络 (Artificial Neural Networks)
The Artificial Neural Network, or just neural network for short, is not a new idea. It has been around for about 80 years.
人工神经网络,或者简称为神经网络,并不是一个新想法。 它已经存在了大约80年。
It was not until 2011, when Deep Neural Networks became popular with the use of new techniques, huge dataset availability, and powerful computers.
直到2011年,深度神经网络因使用新技术,巨大的数据集可用性和强大的计算机而变得流行。
A neural network mimics a neuron, which has dendrites, a nucleus, axon, and terminal axon.
神经网络模仿具有树突,核,轴突和末端轴突的神经元。
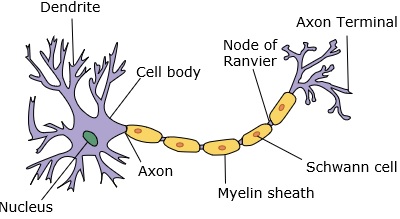
For a network, we need two neurons. These neurons transfer information via synapse between the dendrites of one and the terminal axon of another.
对于一个网络,我们需要两个神经元。 这些神经元通过突触在一个的树突和另一个的终轴突之间传递信息。
A probable model of an artificial neuron looks like this −
人工神经元的可能模型看起来像这样-
A neural network will look like as shown below −
神经网络如下图所示-
The circles are neurons or nodes, with their functions on the data and the lines/edges connecting them are the weights/information being passed along.
圆圈是神经元或节点,它们在数据上具有功能,连接它们的线/边是传递的权重/信息。
Each column is a layer. The first layer of your data is the input layer. Then, all the layers between the input layer and the output layer are the hidden layers.
每列是一个层。 数据的第一层是输入层。 然后,输入层和输出层之间的所有层都是隐藏层。
If you have one or a few hidden layers, then you have a shallow neural network. If you have many hidden layers, then you have a deep neural network.
如果您有一个或几个隐藏层,那么您就拥有一个浅层的神经网络。 如果您有许多隐藏层,那么您将拥有一个深层的神经网络。
In this model, you have input data, you weight it, and pass it through the function in the neuron that is called threshold function or activation function.
在此模型中,您具有输入数据,对其进行加权,然后将其通过神经元中的函数(称为阈值函数或激活函数)传递。
Basically, it is the sum of all of the values after comparing it with a certain value. If you fire a signal, then the result is (1) out, or nothing is fired out, then (0). That is then weighted and passed along to the next neuron, and the same sort of function is run.
基本上,它是将它与某个特定值进行比较之后所有值的总和。 如果您发射信号,则结果为(1),否则没有结果,则为(0)。 然后将其加权并传递到下一个神经元,并运行相同类型的功能。
We can have a sigmoid (s-shape) function as the activation function.
我们可以将S型(s形)函数作为激活函数。
As for the weights, they are just random to start, and they are unique per input into the node/neuron.
至于权重,它们只是随机开始的,并且对于节点/神经元的每个输入都是唯一的。
In a typical "feed forward", the most basic type of neural network, you have your information pass straight through the network you created, and you compare the output to what you hoped the output would have been using your sample data.
在典型的“前馈”(神经网络的最基本类型)中,您的信息将直接通过创建的网络传递,然后将输出与希望使用示例数据获得的输出进行比较。
From here, you need to adjust the weights to help you get your output to match your desired output.
在这里,您需要调整权重以帮助您获得与所需输出匹配的输出。
The act of sending data straight through a neural network is called a feed forward neural network.
直接通过神经网络发送数据的行为称为前馈神经网络。
Our data goes from input, to the layers, in order, then to the output.
我们的数据从输入开始依次到各层,再到输出。
When we go backwards and begin adjusting weights to minimize loss/cost, this is called back propagation.
当我们倒退并开始调整权重以最小化损失/成本时,这称为反向传播。
This is an optimization problem. With the neural network, in real practice, we have to deal with hundreds of thousands of variables, or millions, or more.
这是一个优化问题。 使用神经网络,在实际中,我们必须处理成千上万个变量,甚至数百万个甚至更多。
The first solution was to use stochastic gradient descent as optimization method. Now, there are options like AdaGrad, Adam Optimizer and so on. Either way, this is a massive computational operation. That is why Neural Networks were mostly left on the shelf for over half a century. It was only very recently that we even had the power and architecture in our machines to even consider doing these operations, and the properly sized datasets to match.
第一个解决方案是使用随机梯度下降作为优化方法。 现在,有一些选项,例如AdaGrad,Adam Optimizer等。 无论哪种方式,这都是一个庞大的计算操作。 这就是为什么神经网络大部分被搁置了半个多世纪。 直到最近,我们甚至在机器中都拥有强大的功能和体系结构,甚至可以考虑执行这些操作,并选择合适大小的数据集进行匹配。
For simple classification tasks, the neural network is relatively close in performance to other simple algorithms like K Nearest Neighbors. The real utility of neural networks is realized when we have much larger data, and much more complex questions, both of which outperform other machine learning models.
对于简单的分类任务,神经网络在性能上与其他简单算法(例如K最近邻居)相对接近。 当我们拥有更大的数据和更复杂的问题时,神经网络才真正发挥作用,这两者都胜过其他机器学习模型。
深度神经网络 (Deep Neural Networks)
A deep neural network (DNN) is an ANN with multiple hidden layers between the input and output layers. Similar to shallow ANNs, DNNs can model complex non-linear relationships.
深度神经网络(DNN)是在输入和输出层之间具有多个隐藏层的ANN。 与浅层ANN相似,DNN可以对复杂的非线性关系建模。
The main purpose of a neural network is to receive a set of inputs, perform progressively complex calculations on them, and give output to solve real world problems like classification. We restrict ourselves to feed forward neural networks.
神经网络的主要目的是接收一组输入,对其进行渐进的复杂计算,并提供输出以解决诸如分类之类的现实问题。 我们限制自己前馈神经网络。
We have an input, an output, and a flow of sequential data in a deep network.
在深度网络中,我们具有输入,输出和顺序数据流。
Neural networks are widely used in supervised learning and reinforcement learning problems. These networks are based on a set of layers connected to each other.
神经网络广泛用于监督学习和强化学习问题。 这些网络基于彼此连接的一组层。
In deep learning, the number of hidden layers, mostly non-linear, can be large; say about 1000 layers.
在深度学习中,隐藏层的数量(大多数是非线性的)可能很大; 说大约1000层。
DL models produce much better results than normal ML networks.
DL模型比普通的ML网络产生更好的结果。
We mostly use the gradient descent method for optimizing the network and minimising the loss function.
我们主要使用梯度下降法来优化网络并最小化损失函数。
We can use the Imagenet, a repository of millions of digital images to classify a dataset into categories like cats and dogs. DL nets are increasingly used for dynamic images apart from static ones and for time series and text analysis.
我们可以使用Imagenet (数百万个数字图像的存储库)将数据集分类为猫和狗等类别。 DL网络越来越多地用于除静态图像之外的动态图像以及时间序列和文本分析。
Training the data sets forms an important part of Deep Learning models. In addition, Backpropagation is the main algorithm in training DL models.
训练数据集是深度学习模型的重要组成部分。 另外,反向传播是训练DL模型的主要算法。
DL deals with training large neural networks with complex input output transformations.
DL处理具有复杂输入输出转换的大型神经网络的训练。
One example of DL is the mapping of a photo to the name of the person(s) in photo as they do on social networks and describing a picture with a phrase is another recent application of DL.
DL的一个示例是将照片映射到照片中的人的名字,就像他们在社交网络上所做的那样,并用短语描述图片是DL的另一项最新应用。
Neural networks are functions that have inputs like x1,x2,x3…that are transformed to outputs like z1,z2,z3 and so on in two (shallow networks) or several intermediate operations also called layers (deep networks).
神经网络是具有x1,x2,x3等输入的函数,这些函数在两个(浅网络)或几个中间操作(也称为层)(深层网络)中转换为z1,z2,z3等输出。
The weights and biases change from layer to layer. ‘w’ and ‘v’ are the weights or synapses of layers of the neural networks.
权重和偏差会随层的不同而变化。 “ w”和“ v”是神经网络各层的权重或突触。
The best use case of deep learning is the supervised learning problem.Here,we have large set of data inputs with a desired set of outputs.
深度学习的最佳用例是有监督的学习问题。在这里,我们有大量的数据输入和所需的一组输出。
Here we apply back propagation algorithm to get correct output prediction.
在这里,我们应用反向传播算法来获得正确的输出预测。
The most basic data set of deep learning is the MNIST, a dataset of handwritten digits.
深度学习的最基本数据集是MNIST,这是手写数字的数据集。
We can train deep a Convolutional Neural Network with Keras to classify images of handwritten digits from this dataset.
我们可以使用Keras深度训练卷积神经网络,以对该数据集中的手写数字图像进行分类。
The firing or activation of a neural net classifier produces a score. For example,to classify patients as sick and healthy,we consider parameters such as height, weight and body temperature, blood pressure etc.
触发或激活神经网络分类器会产生一个分数。 例如,为了将患者分类为健康患者,我们考虑身高,体重和体温,血压等参数。
A high score means patient is sick and a low score means he is healthy.
高分表示患者生病,低分表示患者健康。
Each node in output and hidden layers has its own classifiers. The input layer takes inputs and passes on its scores to the next hidden layer for further activation and this goes on till the output is reached.
输出层和隐藏层中的每个节点都有自己的分类器。 输入层接受输入并将其分数传递到下一个隐藏层以进行进一步激活,并一直进行到达到输出为止。
This progress from input to output from left to right in the forward direction is called forward propagation.
从输入到输出从左到右在向前方向上的这种进展称为前向传播。
Credit assignment path (CAP) in a neural network is the series of transformations starting from the input to the output. CAPs elaborate probable causal connections between the input and the output.
神经网络中的信用分配路径(CAP)是从输入到输出的一系列转换。 CAP详细说明了输入和输出之间可能的因果关系。
CAP depth for a given feed forward neural network or the CAP depth is the number of hidden layers plus one as the output layer is included. For recurrent neural networks, where a signal may propagate through a layer several times, the CAP depth can be potentially limitless.
给定前馈神经网络的CAP深度或CAP深度是隐藏层的数量加上包含输出层的一层。 对于递归神经网络,其中信号可能会多次传播穿过一层,因此CAP深度可能是无限的。
深网和浅网 (Deep Nets and Shallow Nets)
There is no clear threshold of depth that divides shallow learning from deep learning; but it is mostly agreed that for deep learning which has multiple non-linear layers, CAP must be greater than two.
没有明确的深度阈值将浅层学习与深度学习区分开。 但是大多数人都同意,对于具有多个非线性层的深度学习,CAP必须大于两个。
Basic node in a neural net is a perception mimicking a neuron in a biological neural network. Then we have multi-layered Perception or MLP. Each set of inputs is modified by a set of weights and biases; each edge has a unique weight and each node has a unique bias.
神经网络中的基本节点是模仿生物神经网络中神经元的感知。 然后我们有了多层感知或MLP。 每组输入都通过一组权重和偏差进行修改; 每个边缘都有唯一的权重,每个节点都有唯一的偏差。
The prediction accuracy of a neural net depends on its weights and biases.
神经网络的预测准确性取决于其权重和偏差。
The process of improving the accuracy of neural network is called training. The output from a forward prop net is compared to that value which is known to be correct.
提高神经网络准确性的过程称为训练。 将前向支撑网的输出与已知正确的值进行比较。
The cost function or the loss function is the difference between the generated output and the actual output.
成本函数或损失函数是生成的输出与实际输出之间的差。
The point of training is to make the cost of training as small as possible across millions of training examples.To do this, the network tweaks the weights and biases until the prediction matches the correct output.
训练的重点是使数百万个训练示例中的训练成本尽可能小。为此,网络会调整权重和偏差,直到预测与正确的输出匹配为止。
Once trained well, a neural net has the potential to make an accurate prediction every time.
一旦训练好,神经网络就有可能每次都能做出准确的预测。
When the pattern gets complex and you want your computer to recognise them, you have to go for neural networks.In such complex pattern scenarios, neural network outperformsall other competing algorithms.
当模式变得复杂而您想让计算机识别它们时,您就必须使用神经网络。在这种复杂的模式情况下,神经网络的性能优于所有其他竞争算法。
There are now GPUs that can train them faster than ever before. Deep neural networks are already revolutionizing the field of AI
现在有GPU可以比以往更快地训练它们。 深度神经网络已经在改变AI领域
Computers have proved to be good at performing repetitive calculations and following detailed instructions but have been not so good at recognising complex patterns.
事实证明,计算机擅长执行重复计算和遵循详细的说明,但对识别复杂的模式却不太擅长。
If there is the problem of recognition of simple patterns, a support vector machine (svm) or a logistic regression classifier can do the job well, but as the complexity of patternincreases, there is no way but to go for deep neural networks.
如果存在识别简单模式的问题,则支持向量机(svm)或逻辑回归分类器可以很好地完成工作,但是随着模式复杂性的增加,除了深度神经网络之外别无选择。
Therefore, for complex patterns like a human face, shallow neural networks fail and have no alternative but to go for deep neural networks with more layers. The deep nets are able to do their job by breaking down the complex patterns into simpler ones. For example, human face; adeep net would use edges to detect parts like lips, nose, eyes, ears and so on and then re-combine these together to form a human face
因此,对于像人脸这样的复杂模式,浅层神经网络会失败,并且别无选择,只能使用具有更多层的深层神经网络。 深层网络可以通过将复杂的模式分解为更简单的模式来完成其工作。 例如,人脸; adeep net将使用边缘检测嘴唇,鼻子,眼睛,耳朵等部分,然后将它们重新组合在一起以形成人脸
The accuracy of correct prediction has become so accurate that recently at a Google Pattern Recognition Challenge, a deep net beat a human.
正确预测的准确性变得如此精确,以至于在最近的Google模式识别挑战赛上,深网击败了人类。
This idea of a web of layered perceptrons has been around for some time; in this area, deep nets mimic the human brain. But one downside to this is that they take long time to train, a hardware constraint
关于分层感知器网的想法已经存在了一段时间。 在这个区域,深网模仿了人类的大脑。 但是这样做的一个缺点是他们需要花费很长时间进行训练,这是硬件的限制
However recent high performance GPUs have been able to train such deep nets under a week; while fast cpus could have taken weeks or perhaps months to do the same.
但是,最近的高性能GPU在一周之内就能训练出如此深的网络。 而快速的cpus可能要花费数周甚至数月才能完成相同的操作。
选择深网 (Choosing a Deep Net)
How to choose a deep net? We have to decide if we are building a classifier or if we are trying to find patterns in the data and if we are going to use unsupervised learning. To extract patterns from a set of unlabelled data, we use a Restricted Boltzman machine or an Auto encoder.
如何选择深网? 我们必须决定是否要构建分类器,或者是否要尝试在数据中查找模式,以及是否要使用无监督学习。 要从一组未标记的数据中提取模式,我们使用Restricted Boltzman机器或自动编码器。
Consider the following points while choosing a deep net −
选择深网时请考虑以下几点-
For text processing, sentiment analysis, parsing and name entity recognition, we use a recurrent net or recursive neural tensor network or RNTN;
对于文本处理,情感分析,解析和名称实体识别,我们使用递归网络或递归神经张量网络或RNTN;
For any language model that operates at character level, we use the recurrent net.
对于在字符级别运行的任何语言模型,我们都使用递归网络。
For image recognition, we use deep belief network DBN or convolutional network.
对于图像识别,我们使用深度置信网络DBN或卷积网络。
For object recognition, we use a RNTN or a convolutional network.
对于对象识别,我们使用RNTN或卷积网络。
For speech recognition, we use recurrent net.
对于语音识别,我们使用递归网络。
In general, deep belief networks and multilayer perceptrons with rectified linear units or RELU are both good choices for classification.
通常,深度信念网络和带有整流线性单元或RELU的多层感知器都是分类的好选择。
For time series analysis, it is always recommended to use recurrent net.
对于时间序列分析,始终建议使用递归网络。
Neural nets have been around for more than 50 years; but only now they have risen into prominence. The reason is that they are hard to train; when we try to train them with a method called back propagation, we run into a problem called vanishing or exploding gradients.When that happens, training takes a longer time and accuracy takes a back-seat. When training a data set, we are constantly calculating the cost function, which is the difference between predicted output and the actual output from a set of labelled training data.The cost function is then minimized by adjusting the weights and biases values until the lowest value is obtained. The training process uses a gradient, which is the rate at which the cost will change with respect to change in weight or bias values.
神经网络已经存在了50多年了。 但是直到现在,它们才变得突出。 原因是他们很难训练。 当我们尝试使用一种称为向后传播的方法训练它们时,我们会遇到一个称为消失或爆炸梯度的问题。 在训练数据集时,我们会不断地计算成本函数,这是一组标记的训练数据的预测输出与实际输出之间的差值,然后通过调整权重和偏差值直至最低值来最小化成本函数获得。 训练过程使用梯度,即相对于重量或偏差值的变化,成本变化的速率。
受限制的Boltzman网络或自动编码器-RBN (Restricted Boltzman Networks or Autoencoders - RBNs)
In 2006, a breakthrough was achieved in tackling the issue of vanishing gradients. Geoff Hinton devised a novel strategy that led to the development of Restricted Boltzman Machine - RBM, a shallow two layer net.
2006年,在解决梯度消失问题上取得了突破。 杰夫·欣顿(Geoff Hinton)设计了一种新颖的策略,从而开发了浅层两层网络Restricted Boltzman Machine-RBM 。
The first layer is the visible layer and the second layer is the hidden layer. Each node in the visible layer is connected to every node in the hidden layer. The network is known as restricted as no two layers within the same layer are allowed to share a connection.
第一层是可见层,第二层是隐藏层。 可见层中的每个节点都连接到隐藏层中的每个节点。 该网络被称为受限网络,因为同一层内的任何两个层均不允许共享连接。
Autoencoders are networks that encode input data as vectors. They create a hidden, or compressed, representation of the raw data. The vectors are useful in dimensionality reduction; the vector compresses the raw data into smaller number of essential dimensions. Autoencoders are paired with decoders, which allows the reconstruction of input data based on its hidden representation.
自动编码器是将输入数据编码为矢量的网络。 它们创建原始数据的隐藏或压缩表示。 向量在降维方面很有用。 向量将原始数据压缩为较少的基本维数。 自动编码器与解码器配对,可以基于其隐藏表示重建输入数据。
RBM is the mathematical equivalent of a two-way translator. A forward pass takes inputs and translates them into a set of numbers that encodes the inputs. A backward pass meanwhile takes this set of numbers and translates them back into reconstructed inputs. A well-trained net performs back prop with a high degree of accuracy.
RBM是双向转换器的数学等效项。 前向传递获取输入并将其转换为一组数字,这些数字对输入进行编码。 同时,向后传递采用这组数字并将其转换回重构的输入。 训练有素的网具有很高的准确性,可以执行反向支撑。
In either steps, the weights and the biases have a critical role; they help the RBM in decoding the interrelationships between the inputs and in deciding which inputs are essential in detecting patterns. Through forward and backward passes, the RBM is trained to re-construct the input with different weights and biases until the input and there-construction are as close as possible. An interesting aspect of RBM is that data need not be labelled. This turns out to be very important for real world data sets like photos, videos, voices and sensor data, all of which tend to be unlabelled. Instead of manually labelling data by humans, RBM automatically sorts through data; by properly adjusting the weights and biases, an RBM is able to extract important features and reconstruct the input. RBM is a part of family of feature extractor neural nets, which are designed to recognize inherent patterns in data. These are also called auto-encoders because they have to encode their own structure.
在这两个步骤中,权重和偏见都起着至关重要的作用。 它们帮助RBM解码输入之间的相互关系,并确定哪些输入对于检测模式至关重要。 通过前进和后退,RBM被训练为使用不同的权重和偏差来重构输入,直到输入和此处的构建尽可能接近为止。 RBM的一个有趣方面是不需要标记数据。 事实证明,这对于诸如照片,视频,语音和传感器数据之类的现实世界数据集非常重要,而所有这些数据集往往都没有标签。 RBM无需人工人工标记数据,而是自动对数据进行分类。 通过适当地调整权重和偏差,RBM能够提取重要特征并重建输入。 RBM是特征提取器神经网络家族的一部分,其旨在识别数据中的固有模式。 这些也称为自动编码器,因为它们必须编码自己的结构。
深度信仰网络-DBN (Deep Belief Networks - DBNs)
Deep belief networks (DBNs) are formed by combining RBMs and introducing a clever training method. We have a new model that finally solves the problem of vanishing gradient. Geoff Hinton invented the RBMs and also Deep Belief Nets as alternative to back propagation.
深度信念网络(DBN)是通过结合RBM并引入聪明的训练方法而形成的。 我们有了一个新模型,最终解决了梯度消失的问题。 杰夫·欣顿(Geoff Hinton)发明了RBM和Deep Belief Nets作为反向传播的替代方法。
A DBN is similar in structure to a MLP (Multi-layer perceptron), but very different when it comes to training. it is the training that enables DBNs to outperform their shallow counterparts
DBN的结构与MLP(多层感知器)相似,但是在训练方面却大不相同。 正是这种培训使DBN能够胜过其浅薄的竞争对手
A DBN can be visualized as a stack of RBMs where the hidden layer of one RBM is the visible layer of the RBM above it. The first RBM is trained to reconstruct its input as accurately as possible.
DBN可以可视化为一堆RBM,其中一个RBM的隐藏层是其上方RBM的可见层。 训练了第一个RBM,以尽可能准确地重建其输入。
The hidden layer of the first RBM is taken as the visible layer of the second RBM and the second RBM is trained using the outputs from the first RBM. This process is iterated till every layer in the network is trained.
将第一RBM的隐藏层用作第二RBM的可见层,并使用第一RBM的输出来训练第二RBM。 重复此过程,直到网络中的每个层都经过培训为止。
In a DBN, each RBM learns the entire input. A DBN works globally by fine-tuning the entire input in succession as the model slowly improves like a camera lens slowly focussing a picture. A stack of RBMs outperforms a single RBM as a multi-layer perceptron MLP outperforms a single perceptron.
在DBN中,每个RBM都会学习整个输入。 当模型缓慢地改善,就像相机镜头缓慢地聚焦图像时,DBN通过连续地微调整个输入来全局地工作。 堆叠的RBM胜过单个RBM,因为多层感知器MLP胜过单个感知器。
At this stage, the RBMs have detected inherent patterns in the data but without any names or label. To finish training of the DBN, we have to introduce labels to the patterns and fine tune the net with supervised learning.
在这一阶段,RBM已检测到数据中的固有模式,但没有任何名称或标签。 要完成DBN的培训,我们必须在模式上引入标签,并在监督学习的基础上对网络进行微调。
We need a very small set of labelled samples so that the features and patterns can be associated with a name. This small-labelled set of data is used for training. This set of labelled data can be very small when compared to the original data set.
我们需要一小组标记的样本,以便将特征和样式与名称相关联。 这组小标签的数据用于训练。 与原始数据集相比,这组标记数据可能很小。
The weights and biases are altered slightly, resulting in a small change in the net's perception of the patterns and often a small increase in the total accuracy.
权重和偏差会略有变化,从而导致网络对模式的感知发生很小的变化,并且总精度往往会有所增加。
The training can also be completed in a reasonable amount of time by using GPUs giving very accurate results as compared to shallow nets and we see a solution to vanishing gradient problem too.
与浅网相比,使用GPU提供的结果也非常准确,因此训练也可以在合理的时间内完成,并且我们也看到了消失的梯度问题的解决方案。
生成对抗网络-GAN (Generative Adversarial Networks - GANs)
Generative adversarial networks are deep neural nets comprising two nets, pitted one against the other, thus the “adversarial” name.
生成对抗网络是包括两个网络的深层神经网络,其中两个网络相互抵触,因此称为“对抗性”名称。
GANs were introduced in a paper published by researchers at the University of Montreal in 2014. Facebook’s AI expert Yann LeCun, referring to GANs, called adversarial training “the most interesting idea in the last 10 years in ML.”
GAN在2014年由蒙特利尔大学的研究人员发表的一篇论文中进行了介绍。Facebook的AI专家Yann LeCun在提到GAN时称对抗训练为“过去10年来ML最有趣的想法”。
GANs’ potential is huge, as the network-scan learn to mimic any distribution of data. GANs can be taught to create parallel worlds strikingly similar to our own in any domain: images, music, speech, prose. They are robot artists in a way, and their output is quite impressive.
随着网络扫描学会模仿数据的任何分布,GAN的潜力巨大。 可以教导GAN在任何领域创建与我们自己惊人相似的平行世界:图像,音乐,语音,散文。 从某种意义上说,他们是机器人艺术家,他们的作品令人印象深刻。
In a GAN, one neural network, known as the generator, generates new data instances, while the other, the discriminator, evaluates them for authenticity.
在GAN中,一个神经网络(称为生成器)会生成新的数据实例,而另一个神经网络(鉴别器)会对它们的真实性进行评估。
Let us say we are trying to generate hand-written numerals like those found in the MNIST dataset, which is taken from the real world. The work of the discriminator, when shown an instance from the true MNIST dataset, is to recognize them as authentic.
假设我们正在尝试生成类似于MNIST数据集中的手写数字,这些数字取自现实世界。 鉴别器的工作是在显示来自真实MNIST数据集的实例时将其识别为真实的。
Now consider the following steps of the GAN −
现在考虑GAN的以下步骤-
The generator network takes input in the form of random numbers and returns an image.
生成器网络以随机数的形式获取输入并返回图像。
This generated image is given as input to the discriminator network along with a stream of images taken from the actual dataset.
将该生成的图像与从实际数据集中获取的图像流一起作为输入提供给鉴别器网络。
The discriminator takes in both real and fake images and returns probabilities, a number between 0 and 1, with 1 representing a prediction of authenticity and 0 representing fake.
鉴别器同时获取真实图像和伪造图像,并返回概率,介于0和1之间的数字,其中1代表对真实性的预测,0代表伪造。
So you have a double feedback loop −
所以你有一个双重反馈循环-
The discriminator is in a feedback loop with the ground truth of the images, which we know.
鉴别器处于反馈循环中,具有图像的基本事实,这是我们所知道的。
The generator is in a feedback loop with the discriminator.
发生器与鉴别器处于反馈回路中。
递归神经网络-RNN (Recurrent Neural Networks - RNNs)
RNNSare neural networks in which data can flow in any direction. These networks are used for applications such as language modelling or Natural Language Processing (NLP).
RNN Sare神经网络,数据可以在任何方向流动。 这些网络用于语言建模或自然语言处理(NLP)等应用。
The basic concept underlying RNNs is to utilize sequential information. In a normal neural network it is assumed that all inputs and outputs are independent of each other. If we want to predict the next word in a sentence we have to know which words came before it.
RNN的基本概念是利用顺序信息。 在正常的神经网络中,假定所有输入和输出彼此独立。 如果我们想预测句子中的下一个单词,我们必须知道哪个单词在它之前。
RNNs are called recurrent as they repeat the same task for every element of a sequence, with the output being based on the previous computations. RNNs thus can be said to have a “memory” that captures information about what has been previously calculated. In theory, RNNs can use information in very long sequences, but in reality, they can look back only a few steps.
RNN之所以称为递归,是因为它们对序列的每个元素重复相同的任务,并且输出基于先前的计算。 因此,可以说RNN具有“内存”,可以捕获有关先前计算出的信息。 从理论上讲,RNN可以按很长的顺序使用信息,但实际上,它们只能回顾几步。
Long short-term memory networks (LSTMs) are most commonly used RNNs.
长短期内存网络(LSTM)是最常用的RNN。
Together with convolutional Neural Networks, RNNs have been used as part of a model to generate descriptions for unlabelled images. It is quite amazing how well this seems to work.
RNN与卷积神经网络一起被用作模型的一部分,以生成未标记图像的描述。 令人惊讶的是,这看起来效果如何。
卷积深度神经网络-CNN (Convolutional Deep Neural Networks - CNNs)
If we increase the number of layers in a neural network to make it deeper, it increases the complexity of the network and allows us to model functions that are more complicated. However, the number of weights and biases will exponentially increase. As a matter of fact, learning such difficult problems can become impossible for normal neural networks. This leads to a solution, the convolutional neural networks.
如果我们增加神经网络中的层数以使其更深,则它会增加网络的复杂性,并允许我们对更复杂的函数进行建模。 但是,权重和偏差的数量将成倍增加。 实际上,对于正常的神经网络来说,学习这样的难题变得不可能。 这导致了一个解决方案,即卷积神经网络。
CNNs are extensively used in computer vision; have been applied also in acoustic modelling for automatic speech recognition.
CNN广泛用于计算机视觉; 也已经在用于自动语音识别的声学建模中应用。
The idea behind convolutional neural networks is the idea of a “moving filter” which passes through the image. This moving filter, or convolution, applies to a certain neighbourhood of nodes which for example may be pixels, where the filter applied is 0.5 x the node value −
卷积神经网络背后的思想是穿过图像的“运动滤波器”的思想。 此移动滤镜或卷积应用于节点的某个邻域,例如可以是像素,其中应用的滤镜为节点值的0.5 x-
Noted researcher Yann LeCun pioneered convolutional neural networks. Facebook as facial recognition software uses these nets. CNN have been the go to solution for machine vision projects. There are many layers to a convolutional network. In Imagenet challenge, a machine was able to beat a human at object recognition in 2015.
著名的研究人员Yann LeCun开创了卷积神经网络。 Facebook作为面部识别软件使用了这些网络。 CNN已经成为机器视觉项目的解决方案。 卷积网络有很多层。 在Imagenet挑战中,一台机器在2015年的物体识别中能够击败人类。
In a nutshell, Convolutional Neural Networks (CNNs) are multi-layer neural networks. The layers are sometimes up to 17 or more and assume the input data to be images.
简而言之,卷积神经网络(CNN)是多层神经网络。 图层有时最多17个或更多,并假设输入数据为图像。
CNNs drastically reduce the number of parameters that need to be tuned. So, CNNs efficiently handle the high dimensionality of raw images.
CNN大大减少了需要调整的参数数量。 因此,CNN可以有效处理原始图像的高维度。
Python深度学习-基础 (Python Deep Learning - Fundamentals)
In this chapter, we will look into the fundamentals of Python Deep Learning.
在本章中,我们将研究Python深度学习的基础知识。
深度学习模型/算法 (Deep learning models/algorithms)
Let us now learn about the different deep learning models/ algorithms.
现在让我们了解不同的深度学习模型/算法。
Some of the popular models within deep learning are as follows −
深度学习中的一些流行模型如下-
- Convolutional neural networks 卷积神经网络
- Recurrent neural networks 递归神经网络
- Deep belief networks 深度信仰网络
- Generative adversarial networks 生成对抗网络
- Auto-encoders and so on 自动编码器等
The inputs and outputs are represented as vectors or tensors. For example, a neural network may have the inputs where individual pixel RGB values in an image are represented as vectors.
输入和输出表示为矢量或张量。 例如,神经网络可以具有输入,其中图像中的各个像素RGB值表示为矢量。
The layers of neurons that lie between the input layer and the output layer are called hidden layers. This is where most of the work happens when the neural net tries to solve problems. Taking a closer look at the hidden layers can reveal a lot about the features the network has learned to extract from the data.
位于输入层和输出层之间的神经元层称为隐藏层。 这是神经网络试图解决问题时大部分工作的地方。 仔细研究隐藏层可以揭示很多有关网络已学会从数据中提取的功能的信息。
Different architectures of neural networks are formed by choosing which neurons to connect to the other neurons in the next layer.
通过选择哪些神经元连接到下一层中的其他神经元,可以形成神经网络的不同体系结构。
用于计算输出的伪代码 (Pseudocode for calculating output)
Following is the pseudocode for calculating output of Forward-propagating Neural Network −
以下是用于计算前向传播神经网络输出的伪代码-
- # node[] := array of topologically sorted nodes #node []:=拓扑排序节点的数组
- # An edge from a to b means a is to the left of b #从a到b的边表示a在b的左侧
- # If the Neural Network has R inputs and S outputs, #如果神经网络具有R输入和S输出,
- # then first R nodes are input nodes and last S nodes are output nodes. #然后,第一个R节点是输入节点,最后一个S节点是输出节点。
- # incoming[x] := nodes connected to node x #入站[x]:=连接到节点x的节点
- # weight[x] := weights of incoming edges to x #weight [x]:=输入边到x的权重
For each neuron x, from left to right −
对于每个神经元x,从左到右-
- if x <= R: do nothing # its an input node 如果x <= R:不执行任何操作#其输入节点
- inputs[x] = [output[i] for i in incoming[x]] 输入[x] = [输入[x]中i的输出[i]]
- weighted_sum = dot_product(weights[x], inputs[x]) weighted_sum = dot_product(权重[x],输入[x])
- output[x] = Activation_function(weighted_sum) 输出[x] =激活功能(加权和)
训练神经网络 (Training a Neural Network)
We will now learn how to train a neural network. We will also learn back propagation algorithm and backward pass in Python Deep Learning.
现在,我们将学习如何训练神经网络。 我们还将在Python深度学习中学习反向传播算法和反向传递。
We have to find the optimal values of the weights of a neural network to get the desired output. To train a neural network, we use the iterative gradient descent method. We start initially with random initialization of the weights. After random initialization, we make predictions on some subset of the data with forward-propagation process, compute the corresponding cost function C, and update each weight w by an amount proportional to dC/dw, i.e., the derivative of the cost functions w.r.t. the weight. The proportionality constant is known as the learning rate.
我们必须找到神经网络权重的最佳值才能获得所需的输出。 为了训练神经网络,我们使用迭代梯度下降法。 我们首先从权重的随机初始化开始。 随机初始化后,我们使用前向传播过程对数据的某些子集进行预测,计算相应的成本函数C,并以与dC / dw成比例的量更新每个权重w,即,重量。 比例常数称为学习率。
The gradients can be calculated efficiently using the back-propagation algorithm. The key observation of backward propagation or backward prop is that because of the chain rule of differentiation, the gradient at each neuron in the neural network can be calculated using the gradient at the neurons, it has outgoing edges to. Hence, we calculate the gradients backwards, i.e., first calculate the gradients of the output layer, then the top-most hidden layer, followed by the preceding hidden layer, and so on, ending at the input layer.
使用反向传播算法可以有效地计算出梯度。 向后传播或向后支撑的主要观察结果是,由于微分的链式规则,可以使用神经元的出射边缘来计算神经网络中每个神经元处的梯度。 因此,我们向后计算梯度,即首先计算输出层的梯度,然后是最顶层的隐藏层,然后是前面的隐藏层,依此类推,直到输入层为止。
The back-propagation algorithm is implemented mostly using the idea of a computational graph, where each neuron is expanded to many nodes in the computational graph and performs a simple mathematical operation like addition, multiplication. The computational graph does not have any weights on the edges; all weights are assigned to the nodes, so the weights become their own nodes. The backward propagation algorithm is then run on the computational graph. Once the calculation is complete, only the gradients of the weight nodes are required for update. The rest of the gradients can be discarded.
反向传播算法主要是使用计算图的思想来实现的,其中每个神经元都扩展到计算图中的许多节点,并执行简单的数学运算,例如加法,乘法。 计算图的边缘没有任何权重。 所有权重均分配给节点,因此权重成为其自己的节点。 然后在计算图上运行反向传播算法。 一旦计算完成,仅需要权重节点的梯度即可更新。 其余的梯度可以丢弃。
梯度下降优化技术 (Gradient Descent Optimization Technique)
One commonly used optimization function that adjusts weights according to the error they caused is called the “gradient descent.”
一种根据重量引起的误差调整权重的常用优化功能称为“梯度下降”。
Gradient is another name for slope, and slope, on an x-y graph, represents how two variables are related to each other: the rise over the run, the change in distance over the change in time, etc. In this case, the slope is the ratio between the network’s error and a single weight; i.e., how does the error change as the weight is varied.
梯度是坡度的另一个名称,坡度在xy图上表示两个变量如何相互关联:行程的上升,距离随时间的变化等。在这种情况下,坡度为网络错误与单个权重之间的比率; 也就是说,误差随着重量的变化如何变化。
To put it more precisely, we want to find which weight produces the least error. We want to find the weight that correctly represents the signals contained in the input data, and translates them to a correct classification.
为了更准确地说,我们想找出产生最小误差的权重。 我们想要找到正确表示输入数据中包含的信号的权重,并将其转换为正确的分类。
As a neural network learns, it slowly adjusts many weights so that they can map signal to meaning correctly. The ratio between network Error and each of those weights is a derivative, dE/dw that calculates the extent to which a slight change in a weight causes a slight change in the error.
随着神经网络的学习,它会缓慢调整许多权重,以便它们可以将信号正确映射到含义。 网络错误与这些权重中的每个权重之间的比率是导数dE / dw,它计算权重的轻微变化导致误差的轻微变化的程度。
Each weight is just one factor in a deep network that involves many transforms; the signal of the weight passes through activations and sums over several layers, so we use the chain rule of calculus to work back through the network activations and outputs.This leads us to the weight in question, and its relationship to overall error.
在涉及许多转换的深度网络中,每个权重只是一个因素。 权重的信号通过激活并在多个层上求和,因此我们使用演算的链式规则通过网络激活和输出进行反算,这导致了我们所讨论的权重及其与整体误差的关系。
Given two variables, error and weight, are mediated by a third variable, activation, through which the weight is passed. We can calculate how a change in weight affects a change in error by first calculating how a change in activation affects a change in Error, and how a change in weight affects


