PyTorch学习笔记【5】:使用卷积进行泛化
时间:2023-06-17 15:07:00
文章目录
- 前言
- 1. 卷积介绍
-
- 1.1. 卷积的定义
- 1.2. 卷积的特征
- 2. 卷积实战
-
- 2.1. nn.Conv2d
- 2.2. 填充边界
- 2.3. 用卷积检测特征
- 2.4. 进一步研究使用深度和池化技术
-
- 2.4.1. 从大到小:采样
- 2.4.2. 将卷积与下采样相结合
- 2.5. 整合网络
- 3. 训练我们的convnet
-
- 3.1. 训练循环
- 2.2. 测量精度
- 2.3. 保存并加载我们的模型
- 2.4. 在GPU上训练
- 3. 模型设计
-
- 3.1. 增加内存容量:宽度
- 3.2. 正则化
-
- 3.2.1. 检查参数:权重惩罚
- 3.2.2. 不太依赖单一输入:Dropout
- 3.2.3. 保持激活:批量归一化
- 3.3. 深入学习更复杂的结构:深度
-
- 3.3.1. 跳跃连接
- 3.3.2. 使用PyTorch建立非常深的网络
- 总结
前言
本文是基于《Pytorch《深度学习实战》第八章整理的学习笔记
解释相关代码和相应的扩展。
本文使用的代码均基于jupyter
1. 卷积介绍
1.1. 卷积的定义
被定义为二维图像权重矩阵的标量积,即该函数与输入中每个邻域的标量积。
卷积操作:我们从一个小的权重矩阵开始,即卷积核(kernel)首先,让它逐渐扫描二维输入数据。在滑动卷积核的同时,计算权重矩阵和扫描数据矩阵的乘积,然后将结果总结为输出像素。
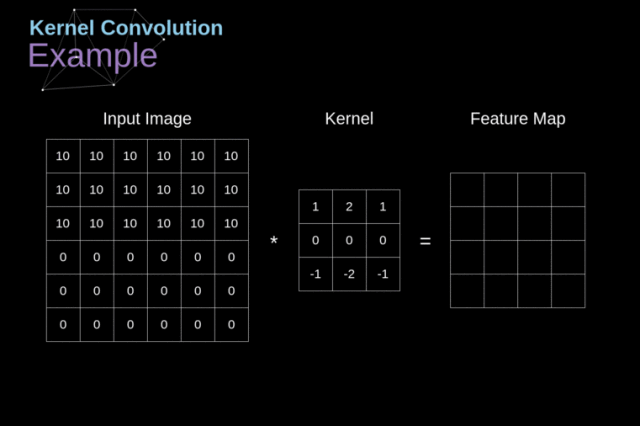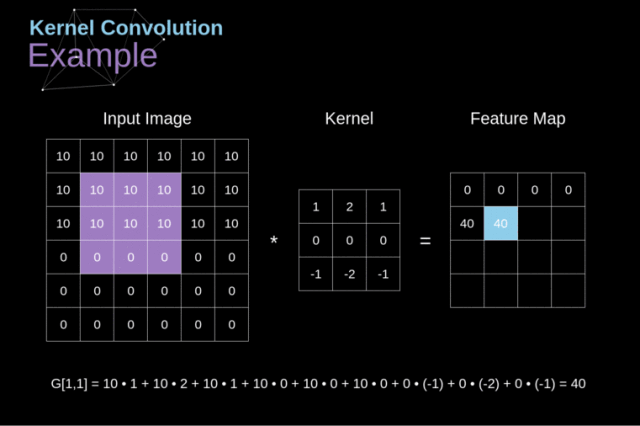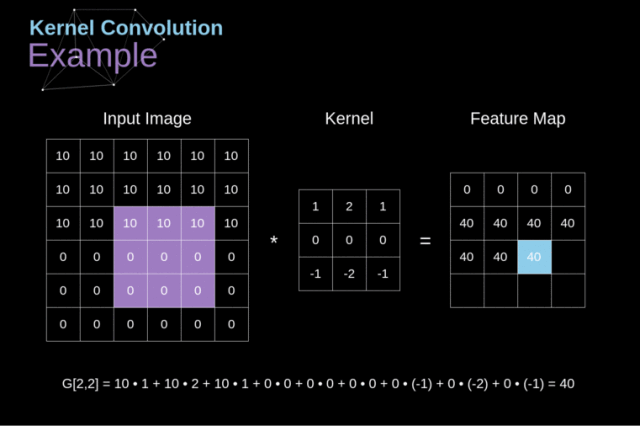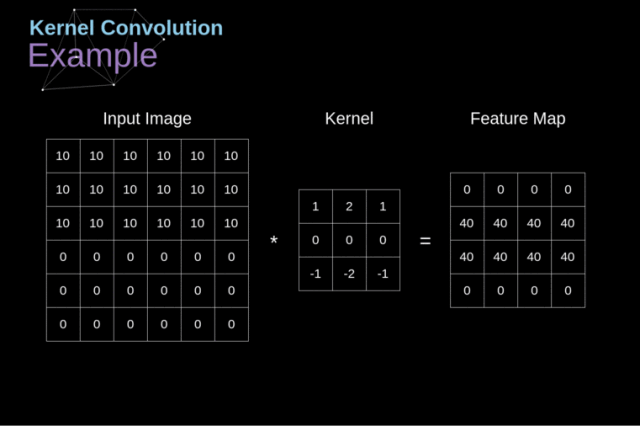
在将输入特征矩阵转换为另一个二维特征矩阵之前,卷积核将在所有位置重复上述操作。
1.2. 卷积的特征
- 邻域局部操作
输出是转换后内核与图像之间的标量积矩阵 - 平移不变性
在图像中使用相同的核权重 - 模型的参数大幅减少
如上面gif原6x经过卷积操作,6矩阵变成4x4的矩阵
2. 卷积实战
%matplotlib inline from matplotlib import pyplot as plt import numpy as np import collections import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim torch.set_printoptions(edgeitems=2) torch.manual_seed(123) class_names = ['airplane','automobile','bird','cat','deer', 'dog','frog','horse','ship','truck'] from torchvision import datasets, transforms data_path = 'data/p1ch7/' cifar10 = datasets.CIFAR10( data_path, train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4915, 0.4823, 0.4468),
(0.2470, 0.2435, 0.2616))
]))
cifar10_val = datasets.CIFAR10(
data_path, train=False, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4915, 0.4823, 0.4468),
(0.2470, 0.2435, 0.2616))
]))
label_map = {
0: 0, 2: 1}
class_names = ['airplane', 'bird']
cifar2 = [(img, label_map[label])
for img, label in cifar10
if label in [0, 2]]
cifar2_val = [(img, label_map[label])
for img, label in cifar10_val
if label in [0, 2]]
2.1. nn.Conv2d
- 用于二维卷积
提供给nn.Conv2d的参数至少包括输入特征(或通道,因为我们处理的是多通道图像,也就是说,每个像素有多个值)的数量、输出特征的数量以及核的大小。
约定俗成的,在所有维度上都使用相同大小的卷积核(二维上使用大小为3x3的卷积核)
conv = nn.Conv2d(3, 16, kernel_size=3)
conv
- 权重张量的形状
对于单个输出像素值,我们的卷积核考虑有in_ch=3个输入通道,因此对于单个输出像素值,其权重分量(平移整个输出通道的不变量)为in_chx3x3。最后,我们有和输出通道一样多的通道。所以完整的权重张量是out_chxin_chx3x3。
conv.weight.shape, conv.bias.shape
一个二维卷积核产生一个二维图像并将其作为输出,它的像素是输入图像邻域的加权和。
nn.Conv2d()期望输入一个BxCxHxW的张量
img, _ = cifar2[0]
output = conv(img.unsqueeze(0))
img.unsqueeze(0).shape, output.shape
显示输入与输出
plt.figure(figsize=(10, 4.8))
ax1 = plt.subplot(1, 2, 1)
plt.title('output')
plt.imshow(output[0, 0].detach(), cmap='gray')
plt.subplot(1, 2, 2, sharex=ax1, sharey=ax1)
plt.imshow(img.mean(0), cmap='gray')
plt.title('input')
plt.show()
2.2. 填充边界
当我们把输入的特征矩阵转换成了输出的特征矩阵,输入图像的边缘被“修剪”掉了,这是因为边缘上的像素永远不会位于卷积核中心,而卷积核也没法扩展到边缘区域以外。这是不理想的,通常我们都希望输入和输出的大小应该保持一致。
Padding就是针对这个问题提出的一个解决方案:它会用额外的“假”像素填充边缘(值一般为0),这样,当卷积核扫描输入数据时,它能延伸到边缘以外的伪像素,从而使输出和输入大小相同。
conv = nn.Conv2d(3, 1, kernel_size=3, padding=1)
output = conv(img.unsqueeze(0))
img.unsqueeze(0).shape, output.shape
无论是否使用填充,权重和偏置的大小都不会改变
2.3. 用卷积检测特征
手动设置权重来处理卷积
- 直接打印卷积后的图像
将偏置归零,然后将权重设置为一个常熟值,这样输出中的每个像素都能得到其相邻像素的均值
with torch.no_grad():
conv.bias.zero_()
with torch.no_grad():
conv.weight.fill_(1.0 / 9.0)
output = conv(img.unsqueeze(0))
plt.figure(figsize=(10, 4.8))
ax1 = plt.subplot(1, 2, 1)
plt.title('output')
plt.imshow(output[0, 0].detach(), cmap='gray')
plt.subplot(1, 2, 2, sharex=ax1, sharey=ax1)
plt.imshow(img.mean(0), cmap='gray')
plt.title('input')
plt.show()
- 设置卷积核的权重后打印图像
conv = nn.Conv2d(3, 1, kernel_size=3, padding=1)
with torch.no_grad():
conv.weight[:] = torch.tensor([[-1.0, 0.0, 1.0],
[-1.0, 0.0, 1.0],
[-1.0, 0.0, 1.0]])
conv.bias.zero_()
output = conv(img.unsqueeze(0))
plt.figure(figsize=(10, 4.8))
ax1 = plt.subplot(1, 2, 1)
plt.title('output')
plt.imshow(output[0, 0].detach(), cmap='gray')
plt.subplot(1, 2, 2, sharex=ax1, sharey=ax1)
plt.imshow(img.mean(0), cmap='gray')
plt.title('input')
plt.show()
2.4. 使用深度和池化技术进一步研究
2.4.1. 从大到小:下采样
将图像缩放一半相当于取4个相邻像素作为输入,产生1个像素作为输出
可选择的操作:
- 取4个像素的平均值,即平均池化(现在用得少)
- 取4个像素的最大值,即最大池化(目前最常用的方法之一,但会导致丢失3个点)
- 使用带步长的卷积,只将第N个像素纳入计算,步长为2的3x4卷积仍然包含来自前一层所有像素的输入
最大池化由`nn.MaxPool2d模块提供
pool = nn.MaxPool2d(2)
output = pool(img.unsqueeze(0))
img.unsqueeze(0).shape, output.shape
2.4.2. 将卷积和下采样结合
可以理解为开始的卷积核对一阶、第几特征的小邻域进行操作,而第二组卷积核则有效地对更宽的邻域进行操作,生成由先前特征组成的特征。
池化可以理解为提取卷积产生的特征中最关键的部分进行训练,往往进行几次卷积就要进行一次池化操作。
2.5. 整合网络
model = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.Tanh(),
nn.MaxPool2d(2),
nn.Conv2d(16, 8, kernel_size=3, padding=1),
nn.Tanh(),
nn.MaxPool2d(2),
# ... 还需要补充的地方
nn.Linear(8 * 8 * 8, 32),
nn.Tanh(),
nn.Linear(32, 2))
第1个卷积将我们从2个RGB通道带到16个RGB通道,因此给网络一个机会来生成16个独立的特征,以(希望)区分鸟和飞机的低级特征。然后应用Tanh活化函数。得到的有 16个通道的、32x32的图像被第1个MaxPool2d池化成有16个通道的、16×16的图像。在这一点上,下采样图像进行另一个卷积,产生一个有8个通道的、16×16的输出。如果幸运的话,这个输出将包含更高级的特性。同样,我们应用 Tanh 激活函数,然后将其池化到有8个通道的8x8的输出
计算一下这个小模型的参数数目
numel_list = [p.numel() for p in model.parameters()]
sum(numel_list), numel_list
运行一下这个模型
model(img.unsqueeze(0))
编译器将会报错,我们可以发现,这里还缺少从有8个通道的、8x8的图像转换为有512个元素的一维向量的步骤(忽律批处理的纬度)。
3. 训练我们的convnet
3.1. 训练循环
convnet的核心是2个嵌套的循环:
- 一个是跨迭代周期的外部循环
- 另一个是从数据集生成批次的DataLoader的内部循环
在每个循环中,我们都需要:
- 通过模型提供输入(正向传播)
- 计算损失(正向传播的一部分)
- 将任何上一次的梯度归零
- 调用loss.backward()来计算损失相对所有参数的梯度(反向传播)
- 让优化器朝着更低的损失迈进
import datetime
def training_loop(n_epochs, optimizer, model, loss_fn, train_loader):
for epoch in range(1, n_epochs + 1): # 循环变了从1开始到n_epochs
loss_train = 0.0
for imgs, labels in train_loader: # 在数据加载器为我们船舰的批中循环数据集
outputs = model(imgs) # 通过我们的模型提供一个批次
loss = loss_fn(outputs, labels) # 计算我们希望最小化的损失
optimizer.zero_grad() # 梯度归零
loss.backward() # 计算我们希望网络学习的参数的梯度
optimizer.step() # 更新模型
loss_train += loss.item() # 对整个训话遍历中得到的损失求和
if epoch == 1 or epoch % 10 == 0:
print('{} Epoch {}, Training loss {}'.format(
datetime.datetime.now(), epoch,
loss_train / len(train_loader))) # 除以训练数据加载器的长度,得到每批平均损失
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64,
shuffle=True) # 数据加载器批量处理cifar2的样本数据集,并随机打乱数据集中样本的顺序
model = Net() # 实例化网络
optimizer = optim.SGD(model.parameters(), lr=1e-2) # 设置优化器
loss_fn = nn.CrossEntropyLoss() # 设置损失函数
training_loop( # 调用定义的训练循环
n_epochs = 100,
optimizer = optimizer,
model = model,
loss_fn = loss_fn,
train_loader = train_loader,
)
2.2. 测量精度
比较模型在训练集和验证集上的精确度
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64, shuffle=False) val_loader = torch.utils.data.DataLoader(cifar2_val, batch_size=64, shuffle=False) def validate(model, train_loader, val_loader): for name, loader in [("train", train_loader), ("val", val_loader)]: correct = 0 total = 0 with torch.no_grad(): # 不需要梯度,因为在验证集上不希望更新参数 for imgs, labels in loader: outputs = model(imgs) _, predicted = torch.max(outputs, dim=1) # 将最大值的索引作为输出,_为占位符 total += labels.shape[0] # 计算样本的数量,因为total会随着批处理的大小而增加 correct += int((predicted == labels).sum()) # 比较具有最大概率的预测类和真实值标签,我们首先得到一个bool数组,统计这个批次中预测值和实际值一致的项的总数 print("Accuracy {}: {:.2f}".format(name , correct / total)) validate(model, train_loader, val_loader)
2.3. 保存并加载我们的模型
- 保存模型
torch.save(model.state_dict(), data_path + 'birds_vs_airplanes.pt')
- 将参数加载到模型实例中
loaded_model = Net() # 我们必须确保在报错模型状态和稍后加载模型状态期间不会改变Net的定义
loaded_model.load_state_dict(torch.load(data_path
+ 'birds_vs_airplanes.pt'))
2.4. 在GPU上训练
- 设置变量device
device = (torch.device('cuda') if torch.cuda.is_available()
else torch.device('cpu'))
print(f"Training on device {
device}.")
- 将待训练的张量移动到GPU上面
import datetime
def training_loop(n_epochs, optimizer, model, loss_fn, train_loader):
for epoch in range(1, n_epochs + 1):
loss_train = 0.0
for imgs, labels in train_loader:
imgs = imgs.to(device=device) # 将imgs和labels移动到我们正在训练的设备上
labels = labels.to(device=device)
outputs = model(imgs)
loss = loss_fn(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_train += loss.item()
if epoch == 1 or epoch % 10 == 0:
print('{} Epoch {}, Training loss {}'.format(
datetime.datetime.now(), epoch,
loss_train / len(train_loader)))
- 实例化模型,并将其移动到和device对应的设备上面
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64,
shuffle=True)
model = Net().to(device=device) # 将我们的模型(所有参数)移动到GPU。如果你忘记将模型或输入移动到GPU,你会得到张量不在同一设备上的错误
optimizer = optim.SGD(model.parameters(), lr=1e-2)
loss_fn = nn.CrossEntropyLoss()
training_loop(
n_epochs = 100,
optimizer = optimizer,
model = model,
loss_fn = loss_fn,
train_loader = train_loader,
)
- 更新validate()
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64,
shuffle=False)
val_loader = torch.utils.data.DataLoader(cifar2_val, batch_size=64,
shuffle=False)
all_acc_dict = collections.OrderedDict()
def validate(model, train_loader, val_loader):
accdict = {
}
for name, loader in [("train", train_loader), ("val", val_loader)]:
correct = 0
total = 0
with torch.no_grad():
for imgs, labels in loader:
imgs = imgs.to(device=device)
labels = labels.to(device=device)
outputs = model(imgs)
_, predicted = torch.max(outputs, dim=1) # <1>
total += labels.shape[0]
correct += int((predicted == labels).sum())
print("Accuracy {}: {:.2f}".format(name , correct / total))
accdict[name] = correct / total
return accdict
all_acc_dict["baseline"] = validate(model, train_loader, val_loader)
- 加载网络权重
PyTorch将尝试将权重加载到与保存它的设备相同的设备上
可通过在加载权重时,指示PyTorch覆盖设备信息会更加简洁
loaded_model = Net().to(device=device)
loaded_model.load_state_dict(torch.load(data_path
+ 'birds_vs_airplanes.pt',
map_location=device))