ILPD(印度肝病患者)分类BP算法和KNN
时间:2023-06-06 00:07:00
声明:本文是我课程作业的内容,只提供平时的学习参考,请勿转载。
介绍:数据挖掘
来源:kaibo_lei_ZZU
ILPD数据集
ILPD数据集来自加州大学统计学习相关网站(UCI)数据集的名称叫Indian Liver Patient Dataset三位印度教授从印度安德拉邦东北部收集了416名肝癌患者和167名非肝癌患者583名肝病患者的记录。583名患者包括441名男性患者和142名女性患者,其中任何89岁以上的患者都被列为90岁。
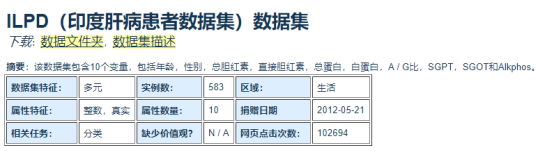
ILPD数据集属性描述
在ILPD数据集包括416名肝病患者和167名非肝病患者。共有10个主要属性和583个样本,包括肝病患者和非肝病患者的记录。
具体属性描述如下表:
显示原始数据集
这个数据集是一个CSV共有538行11列数据的格式数据文件。
下图显示了原始数据集的前25个数据:
数据的第一列代表患者的年龄,第二列代表患者的性别。在这里,性别是一个字符串形式的表示。我们需要在下面的数据分析中将数据转换为离散数据表示,这可以促进我们的数据分析。数据的最后一行表示是否生病,1表示肝癌患者,2表示非肝癌患者。
数据处理
首先对数据进行简单的预处理,进行偏差检测,即检查识别离散值和噪声值。然后清理数据,即处理缺失值和噪声。通过观察数据集,我们可以在数据集的第二列中找到男性male说,女人是female为了提高我们的分类准确性,这里需要更换,男性male用1表示,female用2来表示。
处理后的数据集表示如下:
1. BP(反向传播)算法实现
BP算法描述
BP算法(Back-propagation),误差反向传输算法,其基本思想:学习过程由两个过程组成:信号正向传输(损失)和误差反向传输(误差回传)。网络的运行流程为:当输入一个样例后,获得该样例的特征向量,再根据权向量得到感知器的输入值,然后使用函数计算出每个感知器的输出,再将此输出作为下一层感知器的输入,依次类推,直到输出层。在多层神经网络中,误差曲面可能有多个局部极小值,这意味着使用梯度下降算法可能会发现局部极小值,而不是整体最小值。损失函数现在可以使用。此时,输出结点中的输入权向量可以根据损失函数进行调整,权重可以通过随机梯度下降算法逐层调整,这是反向传输算法计算的一般过程。
BP算法是一种监督学习算法,其主要步骤是输入学习样本,使用反向传播算法反复调整网络权重和偏差,使输出向量尽可能接近预期向量,当网络输出层误差平方小于指定误差时,保存网络权重和偏差。具体步骤如下:
(1)初始化,随机给定各连接权[w],[v]及阈值θi,rt。
(2)由给定的输入输出模式对计算隐层、输出层各单元输出bj=f(wijai-θj) ct=f(vjtbj-rt)
式中:bj实际输出隐层第j神经元;ct实际输出输出层t神经元;wij从输入层到隐层的连接权;vjt从隐层到输出层的连接权。
dtk=(ytk-ct)ct(1-ct) ejk=[dtvjt] bj(1-bj)
(3)选择下一个输入模式对返回第二步进行反复训练,直到网络设置输出误差达到要求。
实验设计
(1)数据集划分
在本数据集中,共有538条数据,前400条数据用于参数培训,后138条数据用于测试数据。
%阅读训练数据 [NUM]=xlsread('shujv','A1:K400') [A]=xlsread('shujv','A1:J400') %读取测试数据 [NUMT]=xlsread('shujv','A401:K583') [C]=xlsread('shujv','A401:J583') (2)算法步骤
输入前400条数据,即(患者年龄和患者) 性别性别、TB总胆红素 、DB直接胆红素、碱性磷酸酶、氨基转移酶、天冬氨酸转移酶TP总标本、ALB白蛋白 、A / G将相应的分类结果作为输出。matlab自带的premnmx()函数将这些数据归一化。
%特征值归一化 [input,minI,maxI] = premnmx( [A ]') ; 通过样本数据的训练,不断修正网络权值和阈值,使误差函数沿负梯度方向下降,接近预期输出。
归一化后,欧洲的数据形式如下:
训练集一化:
测试一体化:
输入输出:
该模型以每组数据的指标为输入,以分类结果为输入层的节点数为10,输出层的节点数为1。
隐含层设计:
IW = net.IW{1,1};
LW = net.LW{2,1};
b1 = net.b{1}
b2 = net.b{2}
net是训练网络,IW表示隐含层的权矩阵,维数 = 隐含层神经元数 * 特征数,LW表示隐含层权矩阵,维数 = 1 * 隐含层神经元数,b输入层的阈值,b2隐含层的阈值。
如下图所示:
激励函数:
BP通常使用神经网络Sigmoid可微函数和线性函数作为网络的激励函数。本文选择S型正切函数tansig作为隐藏神经元的激励函数。由于网络的输出属于[ -1, 1]范围内, 因此,选择预测模型S 型对数函数tansig作为输出层神经元的激励函数。
代码如下:
out1 =1./(1 exp(-n1)); % tansig函数表达式,out1表示输入层的输出结果 Z = (LW * out1) repmat(b2,1,size(testInput,2)); out2 =1./(1 exp(-Z)); % tansig函数表达式,out2表示输入层的输出结果 将训练样本数据归一化后输入网络, 设定网络隐层和输出层激励函数分别为tansig, 网络训练函数为traingdx, 网络性能函数为mse,隐层神经元数初设为4。
设定网络参数:
网络迭代次数epochs为10000次, 期望误差goal为0.01, 学习速率lr为0.01,设置完毕,开始训练。
%设置训练参数
net.trainparam.epochs = 10000 ;
net.trainparam.goal = 0.01 ;
net.trainParam.lr = 0.01 ;
完整代码
[NUM]=xlsread('shujv','A1:K400')
[A]=xlsread('shujv','A1:J400')
%特征值归一化
[input,minI,maxI] = premnmx( [A ]') ;
%构造输出矩阵
s = size(A,1);
output = zeros( s , 5 ) ;
for i = 1 : s
output( i , NUM(i,11)) = 1 ;
end
%创建神经网络
net = newff( minmax(input) , [55 5] , { 'logsig' 'logsig' } , 'traingdx' ) ;
%设置训练参数
net.trainparam.show = 25 ;
net.trainparam.epochs = 10000 ;
net.trainparam.goal = 0.01 ;
net.trainParam.lr = 0.01 ;
%开始训练
net = train( net, input , output' ) ;
%读取测试数据
[NUMT]=xlsread('shujv','A401:K583')
[C]=xlsread('shujv','A401:J583')
%测试数据归一化
testInput = tramnmx ( [C]' , minI, maxI ) ;
%仿真
Y = sim( net , testInput )
IW = net.IW{1,1}; % net是训练得到的网络,IW表示隐含层的权矩阵
% 维数 = 隐含层神经元个数 * 特征数
LW = net.LW{2,1}; % LW表示隐含层权矩阵,维数 = 1 * 隐含层神经元个数
b1 = net.b{1} % 输入层的阈值
b2 = net.b{2} % 隐含层的阈值
t=size(testInput,2)
u=IW * testInput;
n1 = (IW * testInput) + repmat(b1,1,size(testInput,2));
out1 =1./(1+exp(-n1)); % tansig函数的表达式,out1表示输入层的输出结果
Z = (LW * out1) + repmat(b2,1,size(testInput,2)); % purelin函数就是形如 y = x,所以直接可以得到out2
out2 =1./(1+exp(-Z)); % tansig函数的表达式,out1表示输入层的输出结果
out3=(1./(1+exp(-LW))) * (1./(1+exp(- IW)));
C= LW * IW;
out4=1./(1+exp(-C));
%统计识别正确率
[s1 , s2] = size( Y ) ;
hitNum = 0 ;
for i = 1 : s2
[m , Index] = max( Y( : , i ) ) ;
if( Index == NUMT(i,11) )
hitNum = hitNum + 1 ;
end
end
sprintf('分类识别率是 %3.3f%%',100 * hitNum / s2 )
实验结果分析
网络训练完成后,进行测试集测试训练结果,与分类的正确率。
实验结果:
网络输出误差与训练状态
图 网络训练误差
图 网络训练状态
2. KNN算法分类
KNN算法步骤
KNN的算法原理描述与算法执行流程,我们在上一章的1.5章节已经介绍过,在这里不再重复介绍。本章节主要是KNN算法在印度肝病分类实验中的应用与分类效果。
KNN算法在分析印度肝病患者数据集时的具体算法步骤如下:
1)计算测试数据与各个训练数据之间的距离,也就是计算数据集中前400条训练数据与138条数据中各个属性之间的距离。
2)按照距离的递增关系进行排序,然后进行后续的坐标点的选择。
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
实验设计
(1)数据集分类
前400行前10列作为训练数据,第11列作为测试标签,后138行前10列作为测试属性,后138行第11列作为测试标签。
[NUM]=xlsread(‘shujv’,‘A1:J400’)
[A]=xlsread(‘shujv’,‘K1:K400’)
%读取测试数据
[NUMT]=xlsread(‘shujv’,‘A401:J538’)
[C]=xlsread(‘shujv’,‘K401:K538’)
(2)数据归一化
[mtrain,ntrain] = size(NUM);
[mtest,ntest] = size(NUMT);
dataset = [NUM;NUMT];
[dataset_scale,ps] = mapminmax(dataset’,0,1);
dataset_scale = dataset_scale’;
train_data = dataset_scale(1:mtrain,:);
test_data = dataset_scale( (mtrain+1):(mtrain+mtest),: );
(3)算法代码
[NUM]=xlsread(‘shujv’,‘A1:J400’)
[A]=xlsread(‘shujv’,‘K1:K400’)
[NUMT]=xlsread(‘shujv’,‘A401:J538’)
[C]=xlsread(‘shujv’,‘K401:K538’)
mdl = ClassificationKNN.fit(NUM,A,‘NumNeighbors’,1);
predict_label = predict(mdl, NUMT);
accuracy = length(find(predict_label == C))/length©*100
测试分类标签和预测分类标签。(左侧为测试分类标签,右侧为预测分类标签)
实验结果
正确率:正确率 = 预测标签 / 测试标签
accuracy = length(find(predict_label == C))/length©*100
由实验结果可以看出来印度肝病患者这个数据集用BP网络训练的模型,分类的准确率更高。KNN自身的优点具有:计算简单,易于理解,可解释性强;比较适合处理有缺失属性的样本;能够处理不相关的特征;在相对短的时间内能够对大型数据源做出可行且效果良好的结果。缺点是往往忽略了数据之间的相关性;BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数。这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力。BP神经网络在其局部的或者部分的神经元受到破坏后对全局的训练结果不会造成很大的影响,也就是说即使系统在受到局部损伤时还是可以正常工作的。即BP神经网络具有一定的容错能力。


