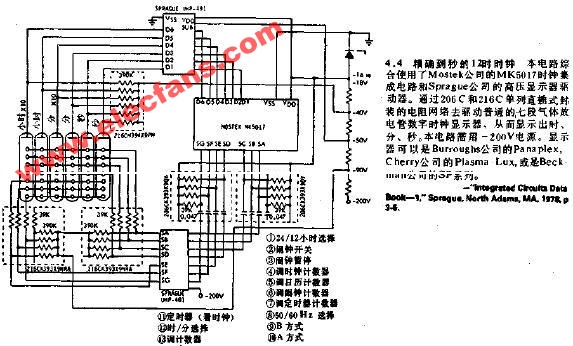
python使用BeautifulSoup解析豆瓣读书网页并获取相关数值
时间:2023-05-04 08:07:00
豆瓣阅读网站:(https://book.douban.com/tag/小说)
难点:
- 获得数值后保存数值。保存时,需要将整理好的书籍列表遍历,依次写入
- 最好在写入时使用str()强制字符化以防万一
- 可能会因为cookies问题不能或完整的页面,需要添加cookies
- 数据清洗阶段,select该方法可重复使用
import cchardet import requests from bs4 import BeautifulSoup class Douban(object): '''bs爬豆瓣数据实战‘’ def __init__(self): self.url = 'https://book.douban.com/tag/小说' # 如果爬不到完整的页面,可能是因为cookies问题,需要加上cookies self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/5。。。。。。。。。。。 Safari/537.36', 'Cookie':'ll="118281"; bid=BpEz4O5XrAo; __utmz=30149280.1631957091.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); dbcl2="221725636:d/GlYal/TfQ"; push_doumail_num=0; __utmv=30149280.22172; __gads=ID=ff013b82325bae46-229e8985cecb00。。。。。。。。。。。。。。。。。。。。。。。。。4-3202-4c71-89a7-84b66f896fc5=user_id:1; gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03_05f066f4-3202-4c71-89a7-84b66f896fc5=true; __utmt_douban=1; _pk_id.100001.8cb4=9bffb40cc78edf5e.1631957089.2.1632456399.1631957260.; __utmt=1; __utmb=30149280.13.10.1632452655'} self.proxies = {'http':'27.191.60.252:3256'} def send(self): ‘发送请求’ res = requests.get(url=self.url,headers=self.headers,proxies=self.proxies).content self.encoding = cchardet.detect(res)['encoding'] return res.decode(self.encoding) def clean(self,res): # 1 转换成bs4对象 soup = BeautifulSoup(res) # 2 得到书的名字 # 通过某一层(标签)的属性 标签名[属性名=属性值 data = soup.select('li[class="subject-item"]') # print(data) # 建立一个空列表来存储数据 book_list = [] for dara in data: book_name = dara.select('h2 a')[0].get('title') 书名通过标签的属性获得 book_url = dara.select('h2 a')[0].get('href') #通过标签的属性获得书链接 book_appraise = dara.select('span[class="rating_nums"]')[0].get_text() ##通过标签属性获得书的评分 # print(book_name) # print(book_url) # print(book_appraise) # print(type(book_name)) # print(['{%s:%s},%s'] % (book_name,book_url,book_appraise) ) total = [book_name,book_url,book_appraise] book_list.append(total) # print('=============') # print(book_list) return book_list def save(self,res): with open(10天/douban.txt','w',encoding='utf-8') as f: for i in range(len(res)): for a in res[i]: print(a) f.write(str(a) '\r') print(‘成功保存’) def run(self): # 1 发送请求 res = self.send() # 2 保存数据(取消保存,最后一步入库) # self.save(res) # 3 清洗 data = self.clean(res) # 4 入库(Excel,数据库) self.save(data) if __name__ == '__main__': Douban().run() # 以列表的形式保存 # d = [{'d':'sdf'},'da'] # # print(type(d))