计算机视觉CV-目标检测OB
时间:2023-02-23 09:00:00
计算机视觉CV-目标检测OB
一、简介
目标检测,又称目标提取,是计算机视觉四大基本任务之一(分类、定位、检测、分割),是一种基于目标几何和统计特征的图像分割。目的是划分和识别图像上的预定目标。一般来说,检测图像中的内容和位置通常用矩形框来设定目标。
在传统机器学习时代,目标检测的经典算法大多基于滑动窗口、人工特征提取等技术手段,代表算法VJ检测器、HOG行人检测器和DPM检测器等;
在深度学习时代,大放异彩的卷积神经网络也引入了目标检测任务,实现了工业级的真正使用。在此期间,经典诞生了Archor-Based范式,即双阶段目标检测(two-stage)、单阶段目标检测(one-stage)两种算法。
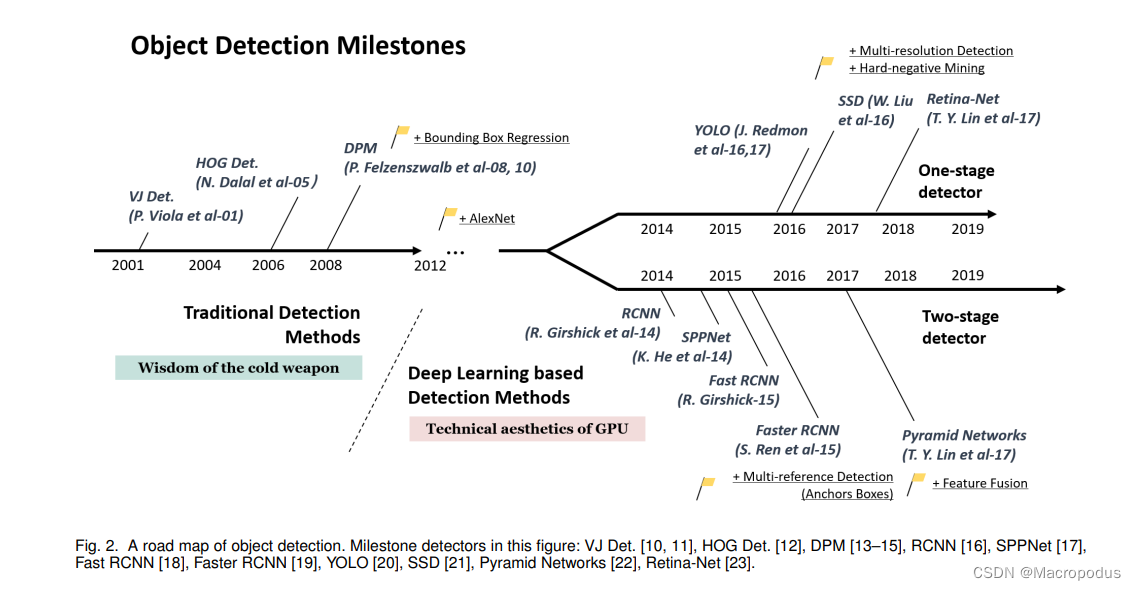
双阶段目标检测算法有:RCNN -> SPPNet -> Fast-RCNN -> Faster-RCNN -> Mask-RCNN -> FPN。
单阶段目标检测算法有:YOLO -> SSD -> RetinaNet。
近几年Archor-free算法也大放异彩,成为新的研究热点, 有:DenseBox -> YoloV1 -> CornerNet -> ExtremeNet -> CenterNet -> FSAF -> FCOS -> ATSS -> YOLOX。
基于Transformer的算法有:DETR -> Swin -> DINO。
二、Archor-Based
2.1 双阶段目标检测算法(two-stage)
2.1.1 RCNN(2013)
RCNN目标检测流程图
RCNN将卷积神经网络引入目标检测 Object-Detection 开山任务,两阶段目标检测的经典作品。
RCNN流程主要是:1.候选框ROI生成(Selective Search方法, 切割 相似度) -> 2.候选框ROI的CNN特征提取(AlexNet, 预训练 微调) -> 3.候选框ROI的SVM类别分类(少数据下难以分类样本挖掘) -> 4.BBox回归和候选边框装饰(NMS)。
特点:
- 1.使用Selective Search方法提取2000个候选框,替代传统的滑动窗口方法,大大提升了速度(但2000区域还是很慢, 模型推理耗时47s(14.7)/image);
- 2.第一次成功引入目标检测任务CNN特征抽取,在VOC-07数据集的平均精度为33.7%提升到58.5%;
2.1.2 SPPNet(2014)
SPPNet目标检测流程图
SPPNet网络主要解决方案RCNN中生成2000 候选框引起的速度过慢, 即空间金字塔池化层(SPP, spatial pyramid pooling)。
SPPNet流程主要是:1.候选框ROI生成 -> 2.候选框ROI的CNN特征提取(ZFNet, 一次卷积, 多尺度融合, 只对全连接层进行微调) -> 3.候选框ROI的SVM类别分类 -> 4.BBox回归和候选边框装饰(NMS)。
特点:
- 1.引入空间金字塔池的特征生成(SPP, spatial pyramid pooling), 只需要一次CNN特征抽取, 解决了候选框规模不同的问题, 在ILSVRC-2014年目标检测取得好成绩(目标检测第2/图像分类第3)。
- 2.与RCNN与不损失精度的前提相比, 训练耗时比RCNN快3倍, 模型推理耗时4.3s(2.3)/image, 比RCNN快10-100倍。
2.1.3 Fast-RCNN(2015)
Fast-RCNN目标检测流程图
FastRCNN其实网络还是多阶段的, 对RCNN、SPPNet进一步改进, 主要是将之前独立的SVM将类别分类整合到特征抽取后的特征抽取中FC层, 进行类别的Softmax分类和BBox的回归。
Fast-RCNN流程主要是: 1.候选框ROI生成 -> 2.候选框ROI的CNN同时提取特征Softmax类别分类与BBox回归(VGG) -> 3.边框边框装饰(NMS)。
特点:
- 1.单阶段训练, 即引入VGG网络/ROI-Pooling层(ROI, regions of interest, 感兴趣区域/多任务学习(VGG直接连接分类器/回归模型, 二者loss等等,直接加), 抛弃了前两阶段的训练SVM或线性回归模型。
- 2.Fast-RCNN在VOC-07数据集检测精度mAP从58.5%提高到70%, 训练耗时比RCNN快9倍, 模型推理耗时2.32s(0.32)/image, 比RCNN快213倍。
2.1.4 Faster-RCNN【FPN】(2015)
Faster-RCNN目标锚图
Faster RCNN是目标检测最经典的算法之一, 后来的模型大多是由它改进而来的, 他是第一个成功利用卷积神经网络的人CNN候选框抽取(region proposal)的网络, 提出的Archor-Base思想影响至今, 它仍然广泛应用于工业界。
Faster-RCNN流程主要是: 端到端训练网络两阶段, 1. 候选区域网络(RPN, region proposal networks, 1x1-conv区分目标, 即前景与背景 & 3x3-conv【候选区】 -> 2.ROI层 类别分类和框回归(ROI Pooling Classification Regression)
Faster-RCNN目标检测流程图
特点:
- 1.Faster RCNN深度学习检测算法是第一个真正意义上可以端到端训练、推理、近实时性能的, 将候选框提取并引入卷积神经网络;
- 2.提出区域生成网络(RPN, region proposal networks), 传统的基于滑窗的无类别object检测器融入CNN网络;
- 三、提出锚点(Archor)概念, 即预设一组不同尺度不同位置的固定参考框,覆盖几乎所有位置和尺度,每个参考框负责检测与其交并比大于阈值 (训练预设值,常用0.5或0.7) 的目标, anchor技术将问题转化为"在这个固定的参考框中,目标框偏离参考框有多远?", 不再需要多尺度遍历滑窗, 大大提高了速度。同时anchor的存在, 不同物体的中心点也解决了grid cell中的问题;
- 4.RPN VGG shared模型推理耗时0.198s(0.198)/image, 每张图片使用300张 proposals, PASCAL-VOC-73.2%mAP, PASCAL-VOC-7012年数据集.4%mAP, 达到了新的stoa;
2.1.5 FPN(2017)
FPN块block图
金字塔网络的特点(FPN, Feature Pyramid Networks), 它是一种的网络架构具有横向连接, 高级语义信息可以从不同尺度的高底网络层中提取, 是CV提高模型精度最重要的技术之一。
FPN流程主要是: 1.骨干网络backbone(ResNets) -> 2.颈部网络neck(FPN) ->3.头部网络head(RPN Fast R-CNN)
FPN目标网络架构图
特点:
- 1.FPN特色金字塔网络, 目标检测最流行的架构最初形成(backbone/neck/head), 金字塔结构包括自底向上的线路, 自顶向下的线路与横向连接, 即特征提取/上采样/特征融合/多尺度特征输出。
- 2.FPN模型推理耗时 4 FPS(0.25s/image), COCO数据集上mAP@.5达到59.1%, mAP@[.5,.95]达到36.2%, 当时新的stoa。
2.2 单阶段目标检测算法(one-stage)
2.2.1 YOLO(2016)
YOLOv1网络架构图
YOLO一系列目标检测算法是目标检测任务中最受欢迎的, 算法应用最广泛, 特别是在工业领域, 是非常经典的单阶段模型(one-stage)。
YOLO系列历史:
- YOLOv1: Archor-Free, 1.骨干网络backbone(Darknet框架改写的GoogLeNet) -> 2.颈部网络neck(FC-4096 FC-30) ->3.头部网络head(Grip网格MSE); 检测速度提高,但精度降低(PASCALVOC-2007数据集上mAP有63.4%, 推理速度 45 FPS)。
- YOLOv2: Archor-Based, 1.骨干网络backbone(Darknet-19, 类似VGG) -> 2.颈部网络neck(FC-4096 + FC-30) ->3.头部网络head(Grip网格MSE); 检测精度与Faster RCNN相当的情况下速度可达 40 FPS。tricks如下:BatchNorm + AVGPool + passthrough-layer + high-pixel + anchor-boxes + dimension-clusters + direct-location-prediction + multi-scale-training + hierarchical-classification。
- YOLOv3: Archor-Based, 1.骨干网络backbone(DarkNet-53, 类似ResNet) -> 2.颈部网络neck(三条分支检测, 类似FPN) ->3.头部网络head(Logistic替换Softmax); 在COCO数据集上mAP@.5可达57.9%, mAP@[.5, .95]可达33.0%的情况下, 推理速度有20 FPS(0.051s/image)
- YOLOv4: Archor-Based, 1.骨干网络backbone(CSPDarknet53, 类似DenseNet) -> 2.颈部网络neck(SPP + PAN) ->3.头部网络head(YOLOv3); 在COCO数据集上mAP@.5可达65.7%, mAP@[.5, .95]可达43.5%的情况下, 推理速度有23 FPS(0.043s/image)。tricks:Mosaic增强、cmBN、SAT对抗、CSPDarknet53、Mish、Dropblock、SAM、SPP(类似FPN+PAN)、CIOU、DIOU_NMS。
YOLOv4网络架构图
2.2.2 SSD(2016)
SSDv1网络架构图
SSD网络诞生于FPN前, 是多尺度目标检测的先驱, 特点一是不同尺度的特征图来做检测, 二是采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes), 但是因为没有哦后续版本的缘故, 不如YOLO系列有名气。
SSD流程主要是: 1.骨干网络backbone(VGG) -> 2.颈部网络neck(Multi-scale feature maps) ->3.头部网络head(3x3conv); PASCAL-VOC-2007数据集上mAP有74.3%, 推理速度 59 FPS, 优于YOLOv1。
2.2.3 RetinaNet
RetinaNet网络架构图
RetinaNet网络主要解决一阶段网络训练中存在的类别不平衡问题,提出能根据Loss大小自动调节权重的Focal-loss。
RetinaNet流程主要是: 1.骨干网络backbone(ResNet) -> 2.颈部网络neck(FPN) ->3.头部网络head(class-subnet(top) + box-subnet(bottom) + focal-loss)
RetinaNet在COCO数据集上mAP@.5可达59.1%, mAP@[.5, .95]可达39.1%的情况下, 推理速度有5 FPS(0.198s/image)。
RetinaNet的损失函数Fcoalloss图
三、Archor-Free
3.1 基于多关键点
3.1.1 CornerNet(2018)
CornerNet网络架构图
CornerNet是Anchor free技术路线的开创之作,提出新的对象检测方法,将网络对目标边界框的检测转化为一对关键点的检测(即左上角和右下角),通过将对象检测为成对的关键点,而无需设计Anchor box作为先验框。
CornerNet流程主要是: 1.骨干网络backbone(hourglass, 姿态预测领域, 类似UNet) -> 2.颈部网络neck(Corner-Pooling + 3x3conv-bn) ->3.头部网络head(3x3Conv-ReLU + 1x1Conv);
CornerNet在COCO数据集上mAP@.5可达57.8%, mAP@[.5, .95]可达42.2%的情况下, 推理速度有4 FPS(0.250s/image)。
3.2 基于单中心点
3.2.1 CenterNet(2019)
CenterNet目标示意图
CenterNet直接预测物体bbox的中心点和尺寸, 在预测阶段不需要NMS操作, 真正意义上的Archor-Free。
CenterNet流程主要是: 1.骨干网络backbone(Resnet-18/DLA-34/Hourglass-104) -> 2.颈部网络neck(FC-channel-heatmap) ->3.头部网络head(focal-loss + L1);
CenterNet在COCO数据集上mAP@.5可达63.5%, mAP@[.5, .95]可达45.1%的情况下, 推理速度有1.4 FPS(0.714s/image)。
四、数据集
格式
一般常用的格式有COCO和VOC,即COCO(Common Objects in Context)比赛、VOC(The PASCAL Visual Object Classes)比赛。
COCO数据格式采用json格式存储label标注信息等, VOC数据格式则是采用xml格式存储。
参考资料 Archor-Based
- R-CNN: Rich feature hierarchies for accurate object detection and semantic segmentation
- SPPNet: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Fast R-CNN: Fast R-CNN
- Faster R-CNN: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- YOLOv1: You Only Look Once: Unified, Real-Time Object Detection
- SSD: SSD: Single Shot MultiBox Detector
- FPN: Feature Pyramid Networks for Object Detection
- YOLOv2: YOLO9000: Better, Faster, Stronger
- RetinaNet: Focal Loss for Dense Object Detection
- Mask R-CNN: [Mask R-CNN] (http://openaccess.thecvf.com/content_ICCV_2017/papers/He_Mask_R-CNN_ICCV_2017_paper.pdf)
- YOLOv3: YOLOv3: An Incremental Improvement
- Cascade R-CNN: Cascade R-CNN: Delving into High Quality Object Detection
- CornerNet: CornerNet: Detecting Objects as Paired Keypoints
- NAS-FPN: NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
- YOLOv4: YOLOv4: Optimal Speed and Accuracy of Object Detection
- EfficientDet: EfficientDet: Scalable and Efficient Object Detection
- DETR: End-to-End Object Detection with Transformers
参考资料 Archor-Free
- DenseBox: DenseBox: Unifying Landmark Localization with End to End Object Detection
- ExtremeNet: Bottom-up Object Detection by Grouping Extreme and Center Points
- FSAF: Feature Selective Anchor-Free Module for Single-Shot Object Detection
- FCOS: FCOS: Fully Convolutional One-Stage Object Detection
- CornerNet: CornerNet: Keypoint Triplets for Object Detection
- CenterNet: Objects as Points
- ATSS: Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
- YOLOX: YOLOX: Exceeding YOLO Series in 2021


