CS224N WINTER 2022(四)机器翻译、注意力机制、subword模型(附Assignment4答案)
时间:2023-01-31 12:30:00
CS224N WINTER 2022(1)词向量(附)Assignment1答案)
CS224N WINTER 2022(2)反向传播、神经网络、依存分析(附件)Assignment2答案)
CS224N WINTER 2022(三)RNN、语言模型、梯度消失和梯度爆炸Assignment3答案)
CS224N WINTER 2022年(4)机器翻译注意力机制subword模型(附Assignment4答案)
CS224N WINTER 2022(五)Transformers详解(附Assignment5答案)
序言
-
CS224N WINTER 2022课件可从https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1224/下载,也可从以下网盘获取:
https://pan.baidu.com/s/1LDD1H3X3RS5wYuhpIeJOkA 提取码: hpu3本系列博客的开头还将提供下载链接,总结相应的课件。
-
课件、作业答案、学习笔记(Updating):GitHub@cs224n-winter-2022
-
本系列博客内容说明:
-
作者根据自己的情况记录更有用的知识点,并提出少量的意见或扩展延伸,而不是slide内容完整笔注;
-
CS224N WINTER 2022年共五次作业,作者提供自己完成的参考答案,不保证其正确性;
-
由于CSDN限制博客字数,作者不能在博客中发表完整内容,只能分篇发布,可以从我身上发布GitHub Repository获得完整的笔记,本系列其他分篇博客发布(Updating):
CS224N WINTER 2022(1)词向量(附)Assignment1答案)
CS224N WINTER 2022(2)反向传播、神经网络、依存分析(附件)Assignment2答案)
CS224N WINTER 2022(三)RNN、语言模型、梯度消失和梯度爆炸Assignment3答案)
CS224N WINTER 2022年(4)机器翻译注意力机制subword模型(附Assignment4答案)
CS224N WINTER 2022(五)Transformers详解(附Assignment5答案)
-
文章目录
- 序言
-
- lecture 7 机器翻译,注意机制,subword模型
-
- slides
- notes
- suggested readings
- assignment4 参考答案
-
- 1. Neural Machine Translation with RNNs
- 2. Analyzing NMT Systems
- lecture 8 期末项目
-
- slides
- tips
- suggested readings
- projects
lecture 7 机器翻译,注意机制,subword模型
slides
[slides]
-
机器翻译:slides p.4
-
统计机器翻译(SMT,1990s-2010s):slides p.7
核心观点从数据中学习获得概率模型。
例如,我们想把中文翻译成英文,给出中文句子 x x x,目标是找到最好的英语句子 y y y作为译文:
argmax y P ( y ∣ x ) = argmax y P ( x ∣ y ) P ( y ) (7.1) \text{argmax}_yP(y|x)=\text{argmax}_yP(x|y)P(y)\tag{7.1} argmaxyP(y∣x)=argmaxyP(x∣y)P(y)(7.1)
式 ( 7.1 ) (7.1) (7.1)成立的原因是 P ( x ) P(x) P(x)是一个已知的常数(从中文语料库中利用语言模型计算得到),然后利用贝叶斯法则容易推得。我们可以这样解释式 ( 7.1 ) (7.1) (7.1)右侧的两项:
① P ( y ) P(y) P(y)是一个语言模型,用以使得翻译得到的英文语句尽可能地通顺流畅;
② P ( x ∣ y ) P(x|y) P(x∣y)是一个翻译模型,用以使得翻译得到的英文语句尽可能匹配中文语句;
式 ( 7.1 ) (7.1) (7.1)的建模难点显然在于如何构建翻译模型 P ( x ∣ y ) P(x|y) P(x∣y),这通常需要一系列的平行语料(parallel data),即人工编纂的中英互译样本对。
然后引入一个对齐向量(alignment) a a a,用以指示平行语料之间单词级别的对应关系(如中文中的明天对应英文中的Tommorrow),这是一个隐变量(latent variables),即并没有在数据中被直接指示出来,仅仅是我们为了更好的建模引入的假想变量,需要一些特殊的学习算法(如EM算法)来学习得到隐变量的参数分布,翻译模型由此改进为 P ( x , a ∣ y ) P(x,a|y) P(x,a∣y)。
但是语言之间的语义对应关系可能并不总是那么简单,不同的语言拓扑结构可能导致复杂的对应关系(多对一,一对多),甚至某些单词根本不存在对应词。这里推荐一篇比较古老的讲SMT中参数估计的paper(1994年发表于Computational Linguistics)。
式 ( 7.1 ) (7.1) (7.1)还有一个难点在于如何计算 argmax \text{argmax} argmax,难道需要遍历所有的英文语句 y y y吗?这显然非常的不经济,通常的做法是在模型中强加条件独立性假设(impose strong independence assumption),然后利用动态规划算法(如Viterbi算法)来求解全局最优解,这个求解最优 y y y的过程称为解码(decoding)。
关于强加条件独立性假设这个做法,类比可以联想到概率论以及随机模型中大多假定样本独立同分布,或者参数之间具有独立性等等,不过这在SMT中究竟是指什么的确令人费解。于是笔者在上面那篇老古董paper里找到了independence assumption的说明(p. 40-42),具体如下:
一般性的公式是这样的:
P θ ( x , a ∣ y ) = P θ ( m ∣ y ) P θ ( x ∣ m , y ) P θ ( x ∣ a , m , y ) (7.2) P_\theta(x,a|y)=P_\theta(m|y)P_\theta(x|m, y)P_\theta(x|a,m,y)\tag{7.2} Pθ(x,a∣y)=Pθ(m∣y)Pθ(x∣m,y)Pθ(x∣a,m,y)(7.2)
然后我们定义 ϵ ( m ∣ l ) \epsilon(m|l) ϵ(m∣l)是语句长度的分布概率, t ( x ∣ y ) t(x|y) t(x∣y)是翻译概率;其中 θ \theta θ是模型参数, a a a即为对齐向量, m m m是中文语句 x x x的长度, l l l是英文语句 y y y的长度,那么条件独立性假设如下所示:
P θ ( m ∣ y ) = ϵ ( m ∣ l ) P θ ( a ∣ m , y ) = ( l + 1 ) − m P θ ( x ∣ a , m , y ) = ∏ j = 1 m t ( x j ∣ y a j ) (7.3) P_\theta(m|y)=\epsilon(m|l)\\ P_\theta(a|m,y)=(l+1)^{-m}\\ P_\theta(x|a,m,y)=\prod_{j=1}^m t(x_j|y_{a_j})\tag{7.3} Pθ(m∣y)=ϵ(m∣l)Pθ(a∣m,y)=(l+1)−mPθ(x∣a,m,y)=j=1∏mt(xj∣yaj)(7.3)
其中 a j a_j aj即中文语句 x x x的第 j j j个位置对应的英文语句 y y y的下标,这样转换的好处是引入了语句长度这个变量,我们就可以逐字翻译,具体而言在slides p.16中给出的SMT解码示例中,对每一个中文词生成候选的对应英文单词,然后进行一个全局性的搜索(包括位置对应,选取哪个候选词等等),这就可以使用动态规划来求解了。 -
神经机器翻译(NMT,2014):slides p.18
直接将机器翻译问题转化为seq2seq建模,常见可以用seq2seq建模的机器学习任务有:文本综述,对话系统,文本解析,代码生成。这涉及两个RNN网络层,一个是编码器(encoder),另一个是解码器(decoder):
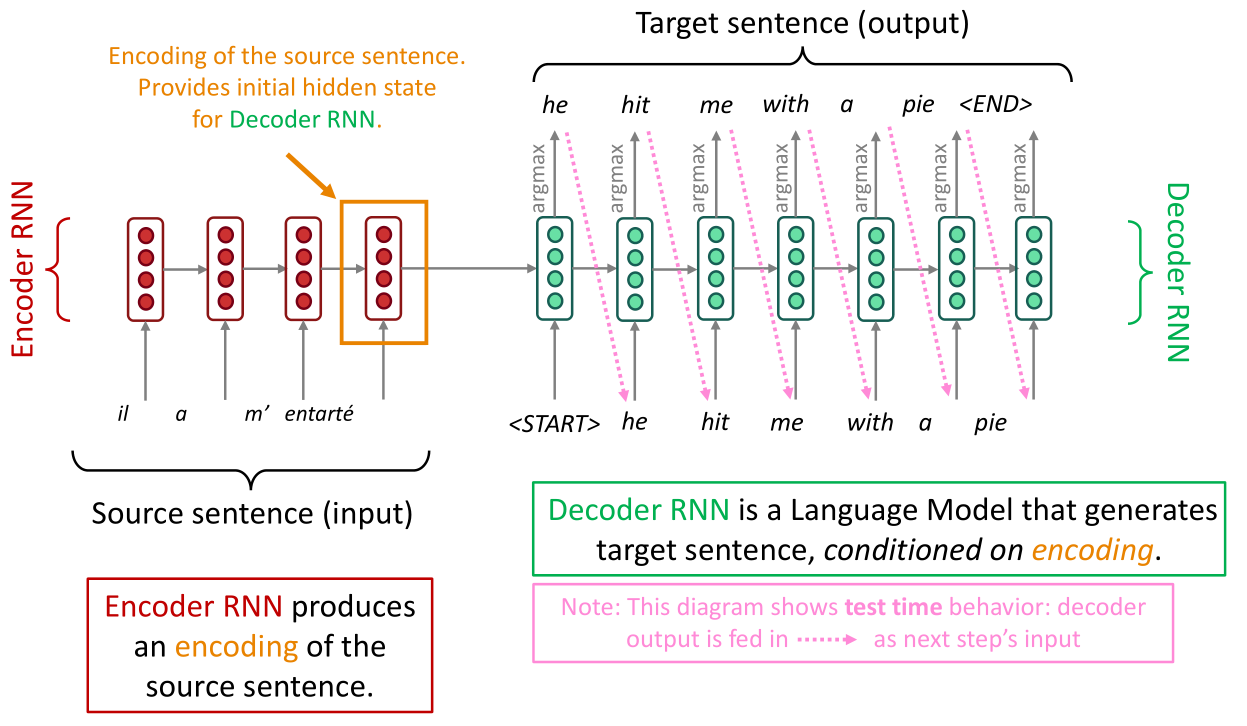
seq2seq模型是条件语言模型(Conditional Language Model)的一种范例,类似式 ( 7.1 ) (7.1) (7.1)中的标记,NMT直接计算 P ( y ∣ x ) P(y|x) P(y∣x)的值:
P ( y ∣ x ) = P ( y 1 ∣ x ) P ( y 2 ∣ y 1 , x ) P ( y 3 ∣ y 1 , y 2 , x ) . . . P ( y T ∣ y 1 , . . . , y T − 1 , x ) (7.4) P(y|x)=P(y_1|x)P(y_2|y_1,x)P(y_3|y_1,y_2,x)...P(y_T|y_1,...,y_{T-1},x)\tag{7.4} P(y∣x)=P(y1∣x)P(y2∣y1,x)P(y3∣y1,y2,x)...P(yT∣y1,...,yT−1,x)(7.4)
这时候我们再次审阅上图,注意右边的解码器是逐字进行解码(翻译)的,这就是式 ( 7.4 ) (7.4) (7.4)的思想,首先翻译第一个单词,然后给定第一个单词翻译第二个单词,依此类推。如何训练seq2seq模型:
上图是单层的encoder-decoder架构,也可以改进为多层的形式,这个可能与直观上的多层有一些区别,并非encoder的最后一层输出接到decoder的第一层输入上,而是encoder每一层都会与decoder的对应层相连接,具体如下图所示:
接下来要说的是NMT中非常关键的问题:式 ( 7.4 ) (7.4) (7.4)到底如何求解(解码)?
正如上文所述,解码器是逐字解码的,那么根据语言模型的思想,很容易想到一种贪心解码(greedy decoding)的方式,在式 ( 7.4 ) (7.4) (7.4)中,我们每次解码得到概率值最大的 y i y_i yi,即首先根据 P ( y 1 ∣ x ) P(y_1|x) P(y1∣x)的取值搜索到最优的 y 1 y_1 y1,然后根据 P ( y 2 ∣ y 1 , x ) P(y_2|y_1,x) P(y2∣y1,x)的取值搜索到最优的 y 2 y_2 y2,依此类推。
显然这种贪心的方法未必能得到全局最优,但如果全局搜索则时间复杂度为 O ( ∣ V ∣ T ) O(|V|^T) O(∣V∣T),即遍历所有的 { y 1 , . . . , y T } \{y_1,...,y_T\} { y1,...,yT}的取值组合,或许可以使用动态规划的方法进行优化,但是这里提出的是一种经典的束搜索(beam search)策略。
束搜索(slides p.32-44有动画演示 )的核心思想是在每一步解码时,不同于贪心解码仅仅找到一个最优的解,而是找到前 k k k个最优的解作为候选(NMT中一般取5~10),然后一步步迭代下去,如果只是这样(稍微改进一些贪心算法),那么复杂度显然为 O ( k T ) O(k^T) O(kT),实际上束搜索还会考虑剪枝,具体而言,当分支数达到 k 2 k^2 k2时,只保留 k k k个最好的分支,然后接着进行后续的分支搜索。
束搜索不保证找到最优解,但相对于贪心算法更可能找到最优解。
-
统计机器翻译与神经机器翻译的对比:slides p.47
NMT相对于SMT最大的优势是可以生成更流畅的译文,此外NMT更好的利用了上下文信息以及短语的相似性。此外NMT相对来说人力成本更低,因为无需进行特征工程。NMT的劣势在于可解释性差,而且难以引入规则进行翻译控制。
-
机器翻译模型的评估指标(BLEU):slides p.49
BLUE不仅是机器翻译模型的指标,它是大多数seq2seq模型的评估指标之一,assignment4中会有BLEU的逻辑,它核心思想是比较预测序列与标准序列之间的相似性(基于n-gram短语)。
BLEU并非总是有效,因为如果翻译结果与标准翻译之间在n-gram短语上的重合度太低,评价就会很差,但是翻译这个事情本身就没有一个绝对标准的答案。
-
机器翻译的疑难:出现词汇表外的单词、迁移性(用中英互译的数据训练,但是需要在中法互译的测试集上评估)、低资源训练(训练数据很少)、代词零冠词辨别错误、形态一致性(morphological agreement)错误、常识与俚语。
但是尽管如此,NMT应该算是深度学习历史上取得的最大成功之一,因为自2014年出现后基本上彻底取代SMT。
-
-
注意力机制:slides p.59
回顾上文提到seq2seq模型的解码器是逐字解码的,问题在于它每次解码都将用到源语句的所有信息,事实上从人类翻译的角度来看中译英,每翻译一个英文单词,只需要关注中文语句中的一小块区域(这其实有点类似alignment的思想),在模型中即在解码器的每一步迭代中,使用一种方式直接连接到编码器(use direct connection to the encoder),这就是注意力机制。(slides p.63-74有动画演示)
如上图所示,当我们要开始翻译he的下一个单词时,我们计算he与源语句中每个输入单词的相似度(一般使用点积)得到注意力得分(Attention scores),得分越高给予的注意力权重也就越高,根据注意的输出结果预测得到 y ^ 2 \hat y_2 y^2,解码得到下一个单词(hit)。
具体而言,我们使用数学表达式描述整个流程:
-
已知编码器的隐层状态 h i ∈ R h , i = 1 , . . . , N h_i\in\R^h,i=1,...,N hi∈Rh
-


