[39题] 牛客深度学习专项题
时间:2023-01-05 14:30:00
1. [卷积核大小] 提升卷积核(convolutional kernel)卷积神经网络的性能将显著提高。这种说法是
- 正确的
- 错误的
卷积核的大小是超参数(hyperparameter),也就是说,改变它既有可能提高,也有可能降低模型的性能。
2. [混沌度] 混沌度(Perplexity)深度学习处理是一种常见的应用NLP哪种说法对问题过程中的评价技术的混乱是正确的?
- 混沌没有影响
- 混沌越低越好
- 混沌越高越好
- 混沌对结果的影响不一定
混沌可以理解为不确定性,当然越低越好。
3. [Dropout] 假设我们有一个5层的神经网络,这个神经网络在使用一个4GB完成培训需要3个小时才能显示显卡。在测试过程中,单个数据需要2秒。 如果我们现在改变架构,当评分为0时.2和0.3.在第二层和第四层分别添加Dropout,那么测试新架构需要多长时间呢?
- 少于2s
- 大于2s
- 仍是2s
- 说不准
添加到架构中Dropout这种变化只会影响训练过程,而不会影响测试过程。
4. [感受野] 在CNN在网络中,图A被核为3x三、步长为2的卷积层,ReLU激活函数层,BN一步长为2,核为22池化层后,通过33的卷积层,步长为1,此时的感觉是()
- 10
- 11
- 12
- 13
l n ? 1 = ( l n ? 1 ) × s n ? 1 k n ? 1 l_{n - 1} = (l_n - 1) \times s_{n - 1} k_{n - 1} ln?1=(ln?1)×sn−1+kn−1
其中: l n = 1 l_n = 1 ln=1,因此我们可以推出:
l 0 = 1 l 1 = ( 1 − 1 ) × 1 + 3 = 3 l 2 = ( 3 − 1 ) × 2 + 2 = 6 l 3 = ( 6 − 1 ) × 2 + 3 = 13 \begin{aligned} & l_0 = 1 \\ & l_1 = (1 - 1) \times 1 + 3 = 3 \\ & l_2 = (3 - 1) \times 2 + 2 = 6 \\ & l_3 = (6 - 1) \times 2 + 3 = 13 \end{aligned} l0=1l1=(1−1)×1+3=3l2=(3−1)×2+2=6l3=(6−1)×2+3=13
即导数第三层特征图的感受野为13。
5. [梯度下降法的顺序] 梯度下降算法的正确步骤是什么?
a. 计算预测值和真实值之间的误差
b. 重复迭代,直至得到网络权重的最佳值
c. 把输入传入网络,得到输出值
d. 用随机值初始化权重和偏差
e. 对每一个产生误差的神经元,调整相应的(权重)值以减小误差
- abcde
- edcba
- cbaed
- dcaeb
dcaeb 这几个步骤面试的时候最好是能够背着说出来吧
6. [卷积核可视化] 下图所示的网络用于训练识别字符H和T,如下所示
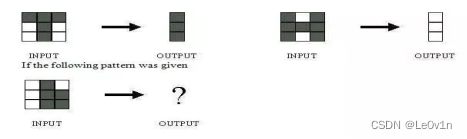
-
-
-
-
可能是A或B,取决于神经网络的权重设置
训练出来的就是个二分类器,简单举例,如果分类器认为中间一列全为黑就是 T,否则就是H,那么输出全黑,如果分类器认为右下角为黑就是 H,否则就是T,那么输出全白,具体还得看分类器权重是怎么学的
我在做这道题的时候,其实第一反应就是,直接选择D的。因为网络的中间权重不知道,我怎么判断特定的结果呢? 换句话说,权重是random的, 只有两个输入和两个对应的输出,是不能说,中间的权重一定是啥啥啥。
首先你网络学习到的结果就两种结果,可以把他当做一个分类问题。
7. [调整超参数] 假设你需要调整超参数来最小化代价函数(cost function),会使用下列哪项技术?
- 穷举搜索
- 随机搜索
- Bayesian优化
- 都可以
穷举搜索法,随机搜索法,贝叶斯优化都可以优化超参数,各有优劣。所以ABC三种都可实现调整优化超参数。
穷举搜索:如网格法grid search 随机搜索快于穷举 bayesian优化:在上一次结果较好的参数取值附近查找
8. [Pooling] 当在卷积神经网络中加入池化层(pooling layer)时,平移变换的不变性会被保留,是吗?
- 不知道
- 看情况
- 是
- 否
池化算法比如取最大值/取平均值等, 都是输入数据旋转后结果不变, 所以多层叠加后也有不变性。
不变性,对于一个函数,如果对其输入施加的某种操作丝毫不会影响到输出,那么这个函数就对该变换具有不变性。
对于加入池化层,卷积神经网络具有近似不变性,如果是max池化,只要不是对最大值进行变换,其变换不会影响最后的输出矩阵。
[ResNet] 9. ResNet-50 有多少个卷积层? ()
- 48
- 49
- 50
- 51
ResNet-50就是因为它有50层网络,这50层里只有一个全连接层,剩下的都是卷积层,所以是50-1=49
10. [防止过拟合] 深度学习中,以下哪些方法可以降低模型过拟合?()
- 增加更多的样本
- Dropout
- 增大模型复杂度,提高在训练集上的效果
- 增加参数惩罚
防止模型过拟合:
- 引入正则化(参数范数惩罚)
- Dropout
- 提前终止训练
- 增加样本量
- 参数绑定与参数共享
- 辅助分类节点(auxiliary classifiers)
- Batch Normalization
正则化(regularization)会给给代价函数增加一个惩罚项,使得系数不会达到很大的值。
11. [激活函数] 深度学习中的激活函数需要具有哪些属性?()
- 计算简单
- 非线性
- 具有饱和区
- 几乎处处可微
- 非线性:即导数不是常数。这个条件是多层神经网络的基础,保证多层网络不退化成单层线性网络。这也是激活函数的意义所在。
- 几乎处处可微:可微性保证了在优化中梯度的可计算性。传统的激活函数如sigmoid等满足处处可微。对于分段线性函数比如ReLU,只满足几乎处处可微(即仅在有限个点处不可微)。对于SGD算法来说,由于几乎不可能收敛到梯度接近零的位置,有限的不可微点对于优化结果不会有很大影响。
- 计算简单:非线性函数有很多。极端的说,一个多层神经网络也可以作为一个非线性函数,类似于Network In Network中把它当做卷积操作的做法。但激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。这也是ReLU之流比其它使用Exp等操作的激活函数更受欢迎的其中一个原因。
- 非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。最经典的例子是Sigmoid,它的导数在x为比较大的正值和比较小的负值时都会接近于0。更极端的例子是阶跃函数,由于它在几乎所有位置的梯度都为0,因此处处饱和,无法作为激活函数。ReLU在x>0时导数恒为1,因此对于再大的正值也不会饱和。但同时对于x<0,其梯度恒为0,这时候它也会出现饱和的现象(在这种情况下通常称为dying ReLU)。Leaky ReLU和PReLU的提出正是为了解决这一问题。
- 单调性(monotonic):即导数符号不变。这个性质大部分激活函数都有,除了诸如sin、cos等。个人理解,单调性使得在激活函数处的梯度方向不会经常改变,从而让训练更容易收敛。
- 输出范围有限:有限的输出范围使得网络对于一些比较大的输入也会比较稳定,这也是为什么早期的激活函数都以此类函数为主,如Sigmoid、TanH。但这导致了前面提到的梯度消失问题,而且强行让每一层的输出限制到固定范围会限制其表达能力。因此现在这类函数仅用于某些需要特定输出范围的场合,比如概率输出(此时loss函数中的log操作能够抵消其梯度消失的影响)、LSTM里的gate函数。
- 接近恒等变换(identity):即约等于x。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加,从而使网络更为稳定,同时梯度也能够更容易地回传。这个与非线性是有点矛盾的,因此激活函数基本只是部分满足这个条件,比如TanH只在原点附近有线性区(在原点为0且在原点的导数为1),而ReLU只在x>0时为线性。这个性质也让初始化参数范围的推导更为简单。这种恒等变换的性质也被其他一些网络结构设计所借鉴,比如CNN中的ResNet和RNN中的LSTM。
- 参数少:大部分激活函数都是没有参数的。像PReLU带单个参数会略微增加网络的大小。还有一个例外是Maxout,尽管本身没有参数,但在同样输出通道数下k路Maxout需要的输入通道数是其它函数的k倍,这意味着神经元数目也需要变为k倍;但如果不考虑维持输出通道数的情况下,该激活函数又能将参数个数减少为原来的k倍。
- 归一化(normalization):这个是最近才出来的概念,对应的激活函数是SELU,主要思想是使样本分布自动归一化到零均值、单位方差的分布,从而稳定训练。在这之前,这种归一化的思想也被用于网络结构的设计,比如Batch Normalization。
12. [权重共享] 下列哪个神经网络结构会发生权重共享?
- 卷积神经网络
- 循环神经网络
- 全连接神经网络
- 选项A和B
权值共享就是说,给一张输入图片,用一个卷积核去扫这张图,卷积核里面的数就叫权重,这张图每个位置是被同样的卷积核扫的,所以权重是一样的,也就是共享。可以极大地减少参数数量,这是全连接神经网络不具备的优势。
CNN,RNN
13. [dropout] 下面哪项操作能实现跟神经网络中Dropout的类似效果?
- Boosting
- Bagging
- Stacking
- Mapping
- Bagging:独立的集成多个模型,每个模型有一定的差异,最终综合有差异的模型的结果,获得学习的最终的结果;
- Boosting(增强集成学习):集成多个模型,每个模型都在尝试增强(Boosting)整体的效果;
- Stacking(堆叠):集成 k 个模型,得到 k 个预测结果,将 k 个预测结果再传给一个新的算法,得到的结果为集成系统最终的预测结果;
14. [BN] 批规范化(Batch Normalization)的好处都有啥?
- 让每一层的输入的范围都大致固定
- 它将权重的归一化平均值和标准差
- 它是一种非常有效的反向传播(BP)方法
- 这些均不是
是对数据进行归一化,而不是权重
15. [BN] BatchNorm 层对于 input batch 会统计出 mean 和 variance 用于计算 EMA。如果input batch 的 shape 为(B, C, H, W),统计出的 mean 和 variance 的 shape 为: ()
- B * 1 * 1 * 1
- 1 * C * 1 * 1
- B * C * 1 * 1
- 1 * 1 * 1 * 1
B代表图像的batch,即多少张图像一个batch。C代表图像的通道数。
BN是对多张图像的同一通道做Normalization
所以有多少通道就有多少个mean和variance
16. [Loss] CNN常见的Loss函数不包括以下哪个()
- softmax_loss
- sigmoid_loss
- Contrastive_Loss
- siamese_loss
contrastive loss表示三元损失函数,是基于 样本对在特征空间距离的 损失函数,希望相似样本距离近,不相似样本距离远,来源于降维。
在传统的siamese network中一般使用Contrastive Loss作为损失函数,这种损失函数可以有效的处理孪生神经网络中的paired data的关系。
17. [caffe] 下列是caffe支持的loss优化的方法的是()
- Adam
- SGD
- AdaDelta
- Nesterov
caffe六种优化方法:
- Stochastic Gradient Descent (type: “SGD”): 随机梯度下降
- AdaDelta (type: “AdaDelta”): 自适应学习率
- Adaptive Gradient (type: “AdaGrad”): 自适应梯度
- Adam (type: “Adam”): 自适应学习,推荐使用
- Nesterov’s Accelerated Gradient (type: “Nesterov”): 加速梯度法
- RMSprop (type: “RMSProp”)
18. [矩阵计算] 深度学习是当前很热门的机器学习算法,在深度学习中,涉及到大量的矩阵相乘,现在需要计算三个稠密矩阵A,B,C 的乘积ABC,假设三个矩阵的尺寸分别为m∗n,n∗p,p∗q,且m
- (AB)C
- AC(B)
- A(BC)
- 所以效率都相同
维度低的先相乘效率更高
19. [深度学习定义] 已知:(1)大脑是有很多个叫做神经元的东西构成,神经网络是对大脑的简单的数学表达。(2)每一个神经元都有输入、处理函数和输出。(3)神经元组合起来形成了网络,可以拟合任何函数。(4)为了得到最佳的神经网络,我们用梯度下降方法不断更新模型。给定上述关于神经网络的描述,什么情况下神经网络模型被称为深度学习模型?
- 加入更多层,使神经网络的深度增加
- 有维度更高的数据
- 当这是一个图形识别的问题时
- 以上都不正确
正确答案A,更多层意味着网络更深。没有严格的定义多少层的模型才叫深度模型,目前如果有超过2层的隐层,那么也可以及叫做深度模型。
20. [学习率] 如果我们用了一个过大的学习速率会发生什么?
- 神经网络会收敛
- 不好说
- 都不对
- 神经网络不会收敛
正确答案是:D 学习率过大,会使得迭代时,越过最低点。
21. [非线性] 下列哪一项在神经网络中引入了非线性?
- 随机梯度下降
- 修正线性单元(ReLU)
- 卷积函数
- 以上都不正确
卷积函数是线性的,一般情况下,卷积层后会跟一个非线性函数。Relu函数是非线性激活函数
22. [Attention-Based] 关于Attention-based Model,下列说法正确的是()
- 相似度度量模型
- 是一种新的深度学习网络
- 是一种输入对输出的比例模型
- 都不对
Attention-based Model其实就是一个相似性的度量,当前的输入与目标状态越相似,那么在当前的输入的权重就会越大,说明当前的输出越依赖于当前的输入。
严格来说,Attention并算不上是一种新的model,而仅仅是在以往的模型中加入attention的思想,所以Attention-based Model或者Attention Mechanism是比较合理的叫法,而非Attention Model。
23. [网络深度] 在选择神经网络的深度时,下面哪些参数需要考虑?
- 神经网络的类型(如MLP,CNN)
- 输入数据
- 计算能力(硬件和软件能力决定)
- 学习速率
- 映射的输出函数
- 1,2,4,5
- 2,3,4,5
- 都需要考虑
- 1,3,4,5
24. [微调][fine-tune] 考虑某个具体问题时,你可能只有少量数据来解决这个问题。不过幸运的是你有一个类似问题已经预先训练好的神经网络。可以用下面哪种方法来利用这个预先训练好的网络?
- 把除了最后一层外所有的层都冻结,重新训练最后一层
- 对新数据重新训练整个模型
- 只对最后几层进行调参(fine tune)
- 对每一层模型进行评估,选择其中的少数来用
(样本少,相似性低)–> 冻结训练
(样本多,相似性低)–> 重新训练
(样本少,相似性高)–> 修改输出层
(样本多,相似性高)–> 预训练权+重新训练
不同数据集下使用微调:
- 数据集1-数据量少,但数据相似度非常高-在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
- 数据集2-数据量少,数据相似度低-在这种情况下,我们可以冻结预训练模型的初始层(比如 k k k 层),并再次训练剩余的 n − k n-k n−k 层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
- 数据集3-数据量大,数据相似度低-在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同,使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scratch)。
- 数据集4-数据量大,数据相似度高-这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
我认为A没错 少量数据就应该冻结更多的层 不然会过拟合
25. [H-K算法] 基于二次准则函数的H-K算法较之于感知器算法的优点是()?
- 计算量小
- 可以判别问题是否线性可分
- 其解完全适用于非线性可分的情况
正确答案是:B H-K算法思想很朴实,就是在最小均方误差准则下求得权矢量。他相对于感知器算法的优点在于,他适用于线性可分和非线性可分得情况:
- 对于线性可分的情况: 给出最优权矢量
- 对于非线性可分得情况: 能够判别出来,以退出迭代过程。
26. [优化器] 下列哪些项所描述的相关技术是错误的?
- AdaGrad使用的是一阶差分(first order differentiation)
- L-BFGS使用的是二阶差分(second order differentiation)
- AdaGrad使用的是二阶差分
- 牛顿法、拟牛顿法、adam,rmsgrad用到了二阶导
- momentum、adgrad用的是一阶导,adgrad的特点是历史梯度正则。
27. [caffe] caffe中基本的计算单元为()
- blob
- layer
- net
- solver
blob: caffe的数据存储单元
layer: caffe的计算单元
28. [Perception][多层感知机] 如果增加多层感知机(Multilayer Perceptron)的隐藏层层数,分类误差便会减小。这种陈述正确还是错误?
- 正确
- 错误
B并不总是正确。层数增加可能导致过拟合,从而可能引起错误增加。
29. [train][val] 有关深度神经网络的训练(Training)和推断(Inference),以下说法中不正确的是:()
- 将数据分组部署在不同GPU上进行训练能提高深度神经网络的训练速度。
- TensorFlow使用GPU训练好的模型,在执行推断任务时,也必须在GPU上运行。
- 将模型中的浮点数精度降低,例如使用float16代替float32,可以压缩训练好的模型的大小。
- GPU所配置的显存的大小,对于在该GPU上训练的深度神经网络的复杂度、训练数据的批次规模等,都是一个无法忽视的影响因素。
C也有问题吧?改变已训练好的模型的数值精度难道不会改变结果精度?那模型量化还要校准表干什么
训练好的模型大小不变,在执行推断的时候改变精度影响后续推断效果
30. [梯度] 在下面哪种情况下,一阶梯度下降不一定正确工作(可能会卡住)?
B这是鞍点(Saddle Point)的梯度下降的经典例子。
本题来源于:https://www.analyticsvidhya.com/blog/2017/01/must-know-questions-deep-learning/。
除了局部极小值,还有一类值为“鞍点”,简单来说,它就是在某一些方向梯度下降,另一些方向梯度上升,形状似马鞍,如下图红点就是鞍点。
对于深度学习模型的优化来说,鞍点比局部极大值点或者极小值点带来的问题更加严重。
31. [特征图计算] 假设你有5个大小为7x7、边界值为0的卷积核,同时卷积神经网络第一层的深度为1。此时如果你向这一层传入一个维度为224x224x3的数据,那么神经网络下一层所接收到的数据维度是多少?
- 218x218x5
- 217x217x8
- 217x217x3
- 220x220x5
注意区分深度、卷积核个数对特征图的影响
32. [GoogLeNet] GoogLeNet提出的Inception结构优势有()
- 保证每一层的感受野不变,网络深度加深,使得网络的精度更高
- 使得每一层的感受野增大,学习小特征的能力变大
- 有效提取高层语义信息,且对高层语义进行加工,有效提高网络准确度
- 利用该结构有效减轻网络的权重
不懂
33. [sigmoid] sigmoid导数为()
- f(z)
- f(1-z)
- f(1+z)f(1-z)
- f(z)(1-f(z))
Sigmoid函数由下列公式定义:
S ( x ) = 1 1 + e − x S(x) = \frac{1}{1+e^{-x}} S(x)=1+e−x1
其对 x x x的导数可以用自身表示:
S ′ ( x ) = e − x ( 1 + e − x ) 2 = S ( x ) ( 1 − S ( x ) ) S'(x) = \frac{e^{-x}}{ (1 + e^{-x})^2} = S(x)(1 - S(x)) S′(x)=(1+e−x)2e−x=S(x)(1−S(x))
34. [loss][lr] 在训练神经网络时,损失函数(loss)在最初的几个epochs时没有下降,可能的原因是?
- 学习率(learning rate)太低
- 正则参数太高
- 陷入局部最小值
- 以上都有可能
35. [量化][INFTY] 现有一 1920 × 1080 1920\times 1080 1920×1080 的单通道图像,每个像素用 float32 存储,对其进行 4 个 3 × 3 3\times 3 3×3 核的卷积(无 padding),卷积核如下:
- 256
- 284
- 296
- 324
36. [过拟合] 下列的哪种方法可以用来降低深度学习模型的过拟合问题?
- 增加更多的数据
- 使用数据扩增技术(data augmentation)
- 使用归纳性更好的架构
- 正规化数据
- 降低架构的复杂度


