3D 语义分割——Scribble-Supervised LiDAR Semantic Segmentation
时间:2022-12-21 23:00:00
??论文(
CVPR2022 Oral)主要贡献:
- 提出第一个涂鸦标签(scribble-annotated) 激光雷达语义分割数据集 ScribbleKITTI
- 提出平衡范围的自我训练(class-range-balanced self-training)处理伪标签占据主要数量和近距离密集区域的类别偏好(bias)问题
- 通过金字塔局部语义上下文描述子(pyramid local semantic-context descriptor) 增强输入点云,从而增强输入点云提高伪标签的质量
- 通过将第
2和3点与 mean teacher 框架结合,论文提出 pipeline 可在仅使用8%在标注点下实现95.7%的全监督(fully-supervised)性能
??密集标注(densely annotating)激光雷达点云费用还是太大了,因此无法跟上不断增长的数据量。 3D 语义分割的科研工作主要集中在全监督使用方法弱监督(weak supervision)实现有效 3D 语义分割方法尚未探索。因此,论文提出使用涂鸦(scribbles)第一个用于标记激光雷达点云并发布 3D 语义分割的涂鸦标注(scribble-annotated)数据集 ScribbleKITTI。但这也导致了包含边缘信息的人未标注(unlabeled)未使用点,且由于缺乏大量的标注点(该方法仅使用 8% 标注点)的数据影响了有长尾分布类信度(监督减少)最终使模型性能下降。
??因此,论文提出了减少使用这种弱标记的建议(weak annotations)性能差距 pipeline,该 pipeline 它可以由三个独立的部分组成与任何 LiDAR 结合语义分割模型,采用论文代码 Cylinder3D 模型,若对 Cylinder3D 如果你感兴趣,请参考我以前的博客。只使用 8% 如果标的情况下,可以实现 95.7% 全监督性能。
ScribbleKITTI 数据集
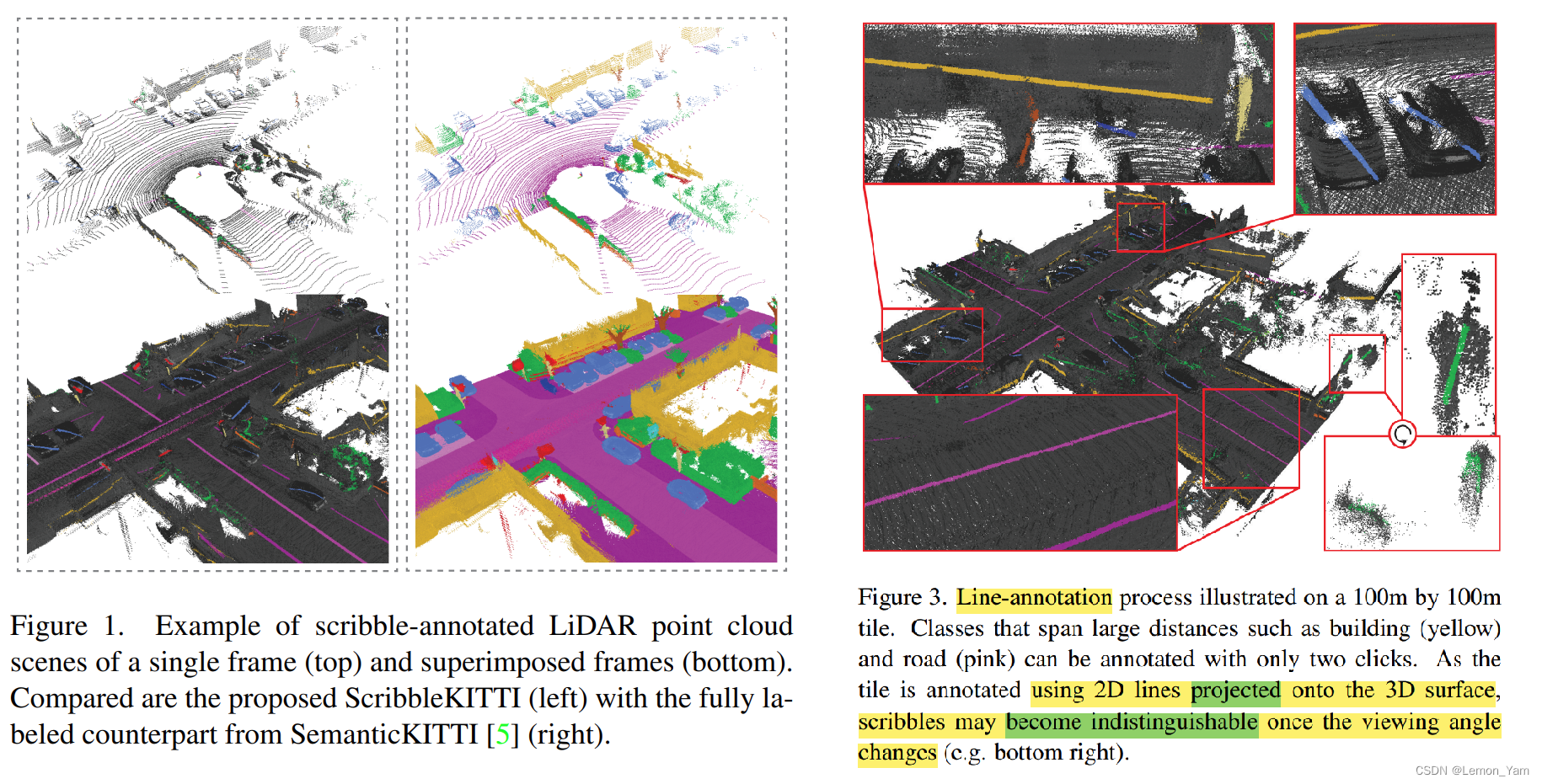
??用涂鸦标注 2D 语义分割中是一种较为流行且有效的方法,但与 2D 图像不同,3D 点云保留测量(metric)空间,导致它几何结构高。为了解决这个问题,建议使用更多几何的论文直线涂鸦(line-scribble)标注激光雷达点云和 free-formed 与涂鸦相比,直线涂鸦可以更快地标记跨越大距离的几何类(如道路、人行道等)。),直线涂鸦只需要知道这些点(某种点云)起始与结束位置。如上图所示,汽车(蓝线)只需确定两点即可完成标记。这将使原本需要花费 1.5-4.5 小时的标记时间减少到 10-25 分钟。
??ScribbleKITTI 基于数据集 SemanticKITTI 的 train-split 部分标注。SemanticKITTI 的 train-split 部分包含 10 个 sequences、19130 个 scans、2349 数百万点;和。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。........................................……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………… ScribbleKITTI 只包含 189 百万个标注点。
??如上面 Figure 3 论文中的直线涂鸦主要是 2D 线投影 3D 表面,当视角发生变化时,直线涂鸦会变得非常模糊(indistinguishable)。
网络结构
- 论文提出的
pipeline可分为training、pseudo-labeling和distillation这三个阶段与生成的伪标签质量密切相关,从而提高了模型的精度 - 在 training 阶段,先通过 PLS 来对增强数据,再训练 mean teacher,这对后面有好处生成更高质量的伪标签
- 在 pseudo-labeling 阶段,通过 CRB 产生目标标签,由于点云本身属性降低,产生伪标签的质量降低
- 在 distillation 阶段,通过之前生成的伪标签再对 mean teacher 进行训练
- mean teacher 中 L S L_S LS 和 L U L_U LU 分别对应有标注的点和未标注各自的损失
Partial Consistency Loss with Mean Teacher
mean teacher 框架由 2 部分组成,分别是权值为 θ \theta θ 的学生网络和权值为 θ E M A \theta^{EMA} θEMA 的教师网络。通常,学生网络的权值通过梯度下降获得,而教师网络的权值则由指数加权平均(exponential moving average)学生的权值获得,其计算公式如下:θ t E M A = α θ t − 1 E M A + ( 1 − α ) θ t \theta_t^{EMA} = \alpha \theta_{t-1}^{EMA} + (1-\alpha)\theta_t θtEMA=αθt−1EMA+(1−α)θt
✍️其中, θ t \theta_t θt 为第 t t t 步中学生网络的权值, θ t E M A \theta_t^{EMA} θtEMA 为第 t t t 步中教师网络的权值, α \alpha α 为平滑系数。通过指数加权平均,可避免 Temporal Ensembling 方法的局限性,且可得到更为精准的模型(相比于直接使用训练的到的权重)
partial consistency loss仅将 consistency loss 用在未标注的点上,这样可通过减少教师网络注入(injected)的不确定性来对标注点进行更严格的监督,同时利用更精准的教师网络输出来对未标注点进行监督。其损失函数如下:
min θ ∑ f = 1 F ∑ i = 1 ∣ P f ∣ G i , f = { H ( y ^ f , i ∣ θ , y f , i ) , p f , i ∈ S l o g ( y ^ f , i ∣ θ ) y ^ f , i ∣ θ E M A , p f , i ∈ U \min_{\theta} \sum_{f=1}^{F} \sum_{i=1}^{|P_f|}G_{i, f} = \begin{cases} H(\hat{y}_{f, i}|_{\theta}, y_{f, i}), & p_{f, i} \in S \\ log(\hat{y}_{f, i}|_{\theta})\hat{y}_{f, i}|_{\theta^{EMA}}, & p_{f, i} \in U \end{cases} θminf=1∑Fi=1∑∣Pf∣Gi,f={ H(y^f,i∣θ,yf,i),log(y^f,i∣θ)y^f,i∣θEMA,pf,i∈Spf,i∈U
✍️其中, S S S 是有标注的点, U U U 是未标注的点, H H H 是损失函数(通常为 cross-entropy), F F F 为点云帧数, ∣ P f ∣ |P_f| ∣Pf∣ 为某一帧点的数量, y ^ f , i ∣ θ \hat{y}_{f, i}|_{\theta} y^f,i∣θ 为学生网络的预测值, y f , i y_{f, i} yf,i 为真实值, y ^ f , i ∣ θ E M A \hat{y}_{f, i}|_{\theta^{EMA}} y^f,i∣θEMA 为教师网络的预测值, p f , i p_{f, i} pf,i 为第 f 帧的第 i 个点
😿尽管 mean teacher 对未标注点进行监督,但由于教师网络性能(performance)的影响,其获取到的信息仍是有限的。即使教师网络正确预测了一个点的标签,但由于软伪标签(soft pseudo-labeling)本身的原因,其他类标签的置信度仍会影响学生网络的输出。
Class-range-balanced Self-training (CRB-ST)
😸为了应对上面所说注入的不确定性并更直接地利用未标注点预测的置信度,论文扩展了标注数据集并使用了 self-training。论文通过将 self-training 与 mean teacher 一起引入,目的是保持 mean teacher 对不确定预测的软伪标签指导(guidance),同时强化某些预测的伪标签。通过使用教师网络中预测出的最大置信度那一类,可为未标注的点生成一组目标标签 L L L。
😸由于激光雷达传感器本身的性质,局部点密度随光束半径的变化而变化,稀疏度随距离的增加而增加。这导致伪标签主要从密度较大的区域采样,其估计置信度往往较高。为了减少伪标签生成中的这种问题,论文提出了一种修正的 self-training 方案并与类范围平衡( CRB) 组合使用。论文首先粗略地将横平面划分为以 ego-vehicle 为中心宽度为 B 的 R 个环,每个环点都包含在一定距离范围内的点,从这些点我们可以伪标(pseudo-label)出每个类别的全局最高置信度预测。这确保我们获得可靠的标签,同时在不同的范围和所有类中按比例分布它们。其损失函数如下:
min θ , y ^ ∑ f = 1 F ∑ i = 1 ∣ P f ∣ [ G i , f − ∑ c = 1 C ∑ r = 1 R F i , f , c , r ] F i , f , c , r = { ( l o g ( y ^ f , i ( c ) ∣ θ E M A ) + k ( c , r ) ) y ^ f , i ( c ) , r = ⌊ ∥ ( p x , y ) f , i ∥ / B ⌋ 0 , o t h e r w i s e \begin{aligned} &\min_{\theta, \hat{y}}\sum_{f=1}^{F}\sum_{i=1}^{|P_f|} [G_{i, f} - \sum_{c=1}^C \sum_{r=1}^R F_{i, f, c, r}] \\ & F_{i, f, c, r} = \begin{cases} (log(\hat{y}_{f, i}^{(c)}|_{\theta^{EMA}})+k^{(c, r)})\hat{y}_{f, i}^{(c)}, \quad &r = \lfloor \parallel(p_{x, y})_{f, i} \parallel/B \rfloor \\ 0, & otherwise\end{cases} \end{aligned} θ,y^minf=1∑Fi=1∑∣Pf∣[Gi,f−c=1∑Cr=1∑RFi,f,c,r]Fi,f,c,r={ (log(y^f,i(c)∣θEMA)+k(c,r))y^f,i(c),0,r=⌊∥(px,y)f,i∥/B⌋otherwise元器件数据手册、IC替代型号,打造电子元器件IC百科大全!