深度学习的坎坷六十年:从感知机到Transformer...
时间:2022-12-26 04:30:00
来源!机器之心
极市平台编辑
1958 年:感知机的兴起
1958 年,弗兰克 · 罗森布拉特发明了一种非常简单的机器模型,后来成为当今智能机器的核心和起源。
传感器是一个非常简单的二元分类器,可以确定给定的输入图像是否属于给定的类别。为了实现这一点,它使用了单位阶跃激活函数。如果输入大于单位阶跃激活函数 0,则输出为 1,否则为 0。
下图是感知机算法。
Frank 感知机构不是用算法构建的,而是用机器构建的。感知机在名称中 Mark I 在感知机的硬件中实现。Mark I 感知机是纯电机。 400 个光电管(或光电探测器),其权重被编码到电位器中,权重更新(发生在反向传播中)由电动机执行。下图是 Mark I 感知机。
就像你今天在新闻中看到的神经网络一样,感知机也是当时的头条新闻。据《纽约时报》报道,[海军] 预计电子计算机的初步模型将能够行走、说话、观察、写作、自我复制和意识到它的存在。今天,我们都知道,机器仍然很难行走、说话、观察、写作和复制自己,而意识是另一件事。
Mark I 传感器的目标只是识别图像,当时只能识别两类。人们花了一些时间才知道添加更多的层次(传感器是单层神经网络)可以使网络具有学习复杂功能的能力。这进一步产生了多层传感器 (MLP)。
1982~1986 : 循环神经网络 (RNN)
在多层感知机显示出解决图像识别问题的潜力后,人们开始思考如何建模文本等序列数据。
循环神经网络是一种旨在处理序列的神经网络。多层感知机 (MLP) 前馈网络不同,RNN 负责记住每个时间步骤的信息状态的内部反馈回路。
第一种 RNN 单元在 1982 年到 1986 年间发现,但并没有引起人们的注意,因为简单 RNN 由于记忆力短,梯度不稳定,单元在长序列中使用时会受到很大影响。
1998:LeNet-5:第一卷积神经网络架构
LeNet-5 是最早的卷积网络架构之一 1998 年用于文档识别。LeNet-5 由 3 个部分组成:2 个卷积层、2 个体采样或池化层和 3 全连接层。卷积层中没有激活函数。
正如论文所说,LeNet-5 商业化部署每天读取数百万张支票。 LeNet-5 结构。图像取自其原始论文。
LeNet-5 这在当时确实是一件有影响力的事情,但它(常规的卷积网络)直到 20 年后才受到关注!LeNet-5 基于早期工作,如福岛邦彦提出的第一卷神经网络,反向传播(Hinton 等人,1986 年)反向传播应用于手写邮政编码识别(LeCun 等人,1989 年)。
1998:长短期记忆(LSTM)
由于梯度不稳定,简单 RNN 单位不能处理长序列问题。LSTM 可用于处理长序列 RNN 版本。LSTM 基本上是 RNN 单元的极端情况。
LSTM 单元的一个特殊设计差异是它有一个门机制,它是控制多个时间步长信息流的基础。
简而言之,LSTM 用门控制从当前时间步到下一步的信息流,有以下信息流 4 种方式:
输入门识别输入序列。
遗忘门删除输入序列中包含的所有不相关信息,并将相关信息存储在长期记忆中。
LTSM 更新单元的状态值。
输出门控制必须发送到下一步的信息。
LSTM 处理长序列的能力使其成为适合文本分类、情感分析、语音识别、图像标题生成和机器翻译等各种序列任务的神经网络架构。
LSTM 是一种强大的架构,但它的计算成本很高。2014 年推出的 GRU(Gated Recurrent Unit)这个问题可以解决。 LSTM 其参数较少,效果也很好。
2012 年:ImageNet 挑战赛、AlexNet 和 ConvNet 的兴起
如果跳过 ImageNet 大规模视觉识别挑战 (ILSVRC) 和 AlexNet,讨论神经网络和深度学习的历史几乎是不可能的。
ImageNet 挑战的唯一目标是评估大型数据集中的图像分类和对象分类架构。它带来了许多新的、强大的、有趣的视觉架构,我们将简要地回顾它们。
挑战赛始于 2010 年,但在 2012 年年变化,AlexNet 以 15.3% 的 Top 5 低错误率赢得了挑战,这几乎是赢家错误率的一半。AlexNet 由 5 卷积层,最大池化层,3 全连接层和一个 softmax 层组成。AlexNet 深度卷积神经网络可以很好地处理视觉识别任务。但当时这一观点还没有深入其他应用!
在接下来的几年里,ConvNets 架构越来越大,工作也越来越好。例如,有 19 层的 VGG 以 7.3% 错误率赢得了挑战。GoogLeNet(Inception-v1) 进一步,将错误率降低到 6.7%。2015 年,ResNet(Deep Residual Networks)扩大这一点,将错误率降低到 3.6%,并表明我们可以通过残差连接训练更深的网络(超过 100 层),在此之前,不可能训练这么深的网络。在此之前,人们发现更深层次的网络工作好,这导致了其他新的架构,如 ResNeXt、Inception-ResNet、DenseNet、Xception 等。
读者可以在这里找到这些结构和其他现代结构的总结和实现:https://github.com/Nyandwi/ModernConvNets
2014 年 : 网络的深度生成
从训练数据中生成或合成新的数据样本,如图像和音乐。
生成网络的种类很多,但最流行的类型是由 Ian Goodfellow 在 2014 对抗网络年创建的生成 (GAN)。GAN 由生成假样本的生成器和区分真实样本和生成器生成样本的判别器组成。生成器和识别器可以说是相互竞争。他们都是独立训练的,在训练过程中玩零和游戏。生成器不断生成欺骗判别器的假样本,而判别器试图找到那些假样本(参考真实样本)。在每次训练迭代中,生成器更好地生成接近真实的假样本,必须提高标准来区分不真实的样本和真实的样本。
GAN 它一直是深入学习社区中最受欢迎的东西之一,生成伪造的图像和 Deepfake 以视频而闻名。如果读者对 GAN 对最新进展感兴趣,可以阅读 StyleGAN2、DualStyleGAN、ArcaneGAN 和 AnimeGANv2 的简介。如需 GAN 请查看资源的完整列表 Awesome GAN 库:https://github.com/nashory/gans-awesome-applications。下图说明了 GAN 模型架构。
GAN 它是一种生成模型。还有其他流行的生成模型类型 Variation Autoencoder (变分自编码器,VAE)、AutoEncoder (自编码器)和扩散模型等。
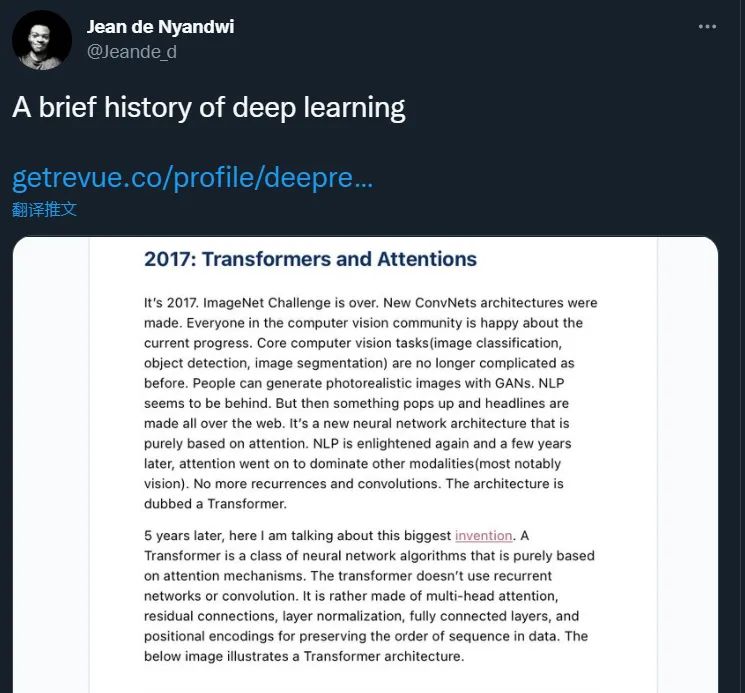
2017 年:Transformers 和注意力机制
时间来到 2017 年。ImageNet 挑战结束了。还制作了新的卷积网络架构。计算机视觉社区的每个人都对当前的进步感到高兴。核心计算机视觉任务(图像分类、目标检测、图像分割)不再像以前那么复杂。人们可以使用它 GAN 生成逼真的图像。NLP 似乎落后了。然而,随后发生了一些事情,并成为整个网络的头条新闻:一种基于注意力机制的新神经网络架构诞生了。并且 NLP 在接下来的几年里,注意力机制继续引领其他方向(最明显的是视觉)。这种结构被称为 Transformer 。
在此之后的 5 现在,我们来谈谈这一最大的创新成果。Transformer 它是一种基于注意力机制的神经网络算法。Transformer 不要使用循环网络或卷积。它由多留数据中的序列顺序,由多头注意力、残差连接、层归一化、全连接层和位置编码组成。下图说明了 Transformer 架构。
Transformer 彻底改变了 NLP,它也在改变计算机视觉领域。 NLP 它用于机器翻译、文本摘要、语音识别、文本补充、文档搜索等。
读者可以在论文中《Attention is All You Need》 中了解有关 Transformer 的更多信息。
2018 年至今
自 2017 年以来,深度学习算法、应用和技术突飞猛进。为了清楚起见,后来的介绍是按类别划分的。在每个类别中,我们都会重新审视主要趋势和一些最重要的突破。
Vision Transformers
Transformer 在 NLP 中表现出优异的性能后不久,一些勇于创新的人就迫不及待地将注意力机制放到了图像上。在论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》中,谷歌的几位研究人员表明,对直接在图像块序列上运行的正常 Transformer 进行轻微修改可以在图像分类数据集上产生实质性的结果。他们将他们的架构称为 Vision Transformer (ViT),它在大多数计算机视觉基准测试中都有体现(在作者撰写本文时,ViT 是 Cifar-10 上最先进的分类模型)。
ViT 设计师并不是第一个尝试在识别任务中使用注意力机制的人。我们可以在论文 Attention Augmented Convolutional Networks 中找到第一个使用的记录,这篇论文试图结合自注意力机制和卷积(摆脱卷积主要是由于 CNN 引入的空间归纳偏置)。另一个例子见于论文《Visual Transformers: Token-based Image Representation and Processing for Computer Vision,这篇论文在基于滤波器的 token 或视觉 token 上运行 Transformer。这两篇论文和许多其他未在此处列出的论文突破了一些基线架构(主要是 ResNet)的界限,但当时并没有超越当前的基准。ViT 确实是最伟大的论文之一。这篇论文最重要的见解之一是 ViT 设计师实际上使用图像 patch 作为输入表示。他们对 Transformer 架构没有太大的改变。
除了使用图像 patch 之外,使 Vision Transformer 成为强大架构的结构是 Transformer 的超强并行性及其缩放行为。但就像生活中的一切一样,没有什么是完美的。一开始,ViT 在视觉下游任务(目标检测和分割)上表现不佳。
在引入 [Swin Transformers ]之后,Vision Transformer 开始被用作目标检测和图像分割等视觉下游任务的骨干网络。Swin Transformer 超强性能的核心亮点是由于在连续的自注意力层之间使用了移位窗口。下图描述了 Swin Transformer 和 Vision Transformer (ViT) 在构建分层特征图方面的区别。
Vision Transformer 一直是近来最令人兴奋的研究领域之一。我们可以在这里讨论许多 Vision Transformers 论文,但读者可以在论文《Transformers in Vision: A Survey》中了解更多信息。其他最新视觉 Transformer 还有 CrossViT、ConViT 和 SepViT 等。
视觉和语言模型
视觉和语言模型通常被称为多模态。它们是涉及视觉和语言的模型,例如文本到图像生成(给定文本,生成与文本描述匹配的图像)、图像字幕(给定图像,生成其描述)和视觉问答(给定一个图像和关于图像中内容的问题,生成答案)。Transformer 在视觉和语言领域的成功很大程度上促成了多模型作为一个单一的统一网络。
实际上,所有视觉和语言任务都利用了预训练技术。在计算机视觉中,预训练需要对在大型数据集(通常是 ImageNet)上训练的网络进行微调,而在 NLP 中,往往是对预训练的 BERT 进行微调。要了解有关 V-L 任务中预训练的更多信息,请阅读论文《A Survey of Vision-Language Pre-Trained Models》。有关视觉和语言任务、数据集的一般概述,请查看论文《Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods》。
前段时间,OpenAI 发布了 [DALL·E 2](改进后的 DALL·E),这是一种可以根据文本生成逼真图像的视觉语言模型。现有的文本转图像模型有很多,但 DALL·E 2 的分辨率、图像标题匹配和真实感都相当出色。
DALL·E 2 尚未对公众开放,但你可以加入候补名单。以下是 DALL·E 2 创建的一些图像示例。
大规模语言模型 (LLM)
语言模型有多种用途。它们可用于预测句子中的下一个单词或字符、总结一段文档、将给定文本从一种语言翻译成另一种语言、识别语音或将一段文本转换为语音。
开玩笑地说,发明 Transformers 的人必须为语言模型在朝着大规模参数化方向前进受到指责(但实际上没有人应该受到责备,Transformers 是 2010 年代十年中最伟大的发明之一,大模型令人震惊的地方在于:如果给定足够的数据和计算,它总能更好地工作)。在过去的 5 年中,语言模型的大小一直在不断增长。
在引入论文《Attention is all you need》一年后,大规模语言模型开始出现。2018 年,OpenAI 发布了 GPT(Generative Pre-trained Transformer),这是当时最大的语言模型之一。一年后,OpenAI 发布了 GPT-2,一个拥有 15 亿个参数的模型。又一年后,他们发布了 GPT-3,它有 1750 亿个参数。GPT-3 用了 570GB 的 文本来训练。这个模型有 175B 的参数,模型有 700GB 大。根据 lambdalabs 的说法,如果使用在市场上价格最低的 GPU 云,训练它需要 366 年,花费 460 万美元!
GPT-n 系列型号仅仅是个开始。还有其他更大的模型接近甚至比 GPT-3 更大。如:NVIDIA Megatron-LM 有 8.3B 参数。最新的 DeepMind Gopher 有 280B 参数。2022 年 4 月 12 日,DeepMind 发布了另一个名为 Chinchilla 的 70B 语言模型,尽管比 Gopher、GPT-3 和 Megatron-Turing NLG(530B 参数)小,但它的性能优于许多语言模型。Chinchilla 的论文表明,现有的语言模型是训练不足的,具体来说,它表明通过将模型的大小加倍,数据也应该加倍。但是,几乎在同一周内又出现了具有 5400 亿个参数的 Google Pathways 语言模型(PaLM)!
代码生成模型
代码生成是一项涉及补全给定代码或根据自然语言或文本生成代码的任务,或者简单地说,它是可以编写计算机程序的人工智能系统。可以猜到,现代代码生成器是基于 Transformer 的。
我们可以确定地说,人们已经开始考虑让计算机编写自己的程序了(就像我们梦想教计算机做的所有其他事情一样),但代码生成器在 OpenAI 发布 Codex 后受到关注。Codex 是在 GitHub 公共仓库和其他公共源代码上微调的 GPT-3。OpenAI 表示:“OpenAI Codex 是一种通用编程模型,这意味着它基本上可以应用于任何编程任务(尽管结果可能会有所不同)。我们已经成功地将它用于编译、解释代码和重构代码。但我们知道,我们只触及了可以做的事情的皮毛。” 目前,由 Codex 支持的 [GitHub Copilot] 扮演着结对程序员的角色。
在我使用 Copilot 后,我对它的功能感到非常惊讶。作为不编写 Java 程序的人,我用它来准备我的移动应用程序(使用 Java)考试。人工智能帮助我准备学术考试真是太酷了!
在 OpenAI 发布 Codex 几个月后,DeepMind 发布了 [AlphaCode],这是一种基于 Transformer 的语言模型,可以解决编程竞赛问题。AlphaCode 发布的博文称:“AlphaCode 通过解决需要结合批判性思维、逻辑、算法、编码和自然语言理解的新问题,在编程竞赛的参与者中估计排名前 54%。” 解决编程问题(或一般的竞争性编程)非常困难(每个做过技术面试的人都同意这一点),正如 Dzmitry 所说,击败 “人类水平仍然遥遥无期”。
前不久,来自 Meta AI 的科学家发布了 InCoder,这是一种可以生成和编辑程序的生成模型。
更多关于代码生成的论文和模型可以在这里找到:https://paperswithcode.com/task/code-generation/codeless
再次回到感知机
在卷积神经网络和 Transformer 兴起之前的很长一段时间里,深度学习都围绕着感知机展开。ConvNets 在取代 MLP 的各种识别任务中表现出优异的性能。视觉 Transformer 目前也展示出似乎是一个很有前途的架构。但是感知机完全死了吗?答案可能不是。
在 2021 年 7 月,两篇基于感知机的论文被发表。一个是 [MLP-Mixer: An all-MLP Architecture for Vision],另一个是 [Pay Attention to MLPs(gMLP)].
MLP-Mixer 声称卷积和注意力都不是必需的。这篇论文仅使用多层感知机 (MLP),就在图像分类数据集上取得了很高的准确性。MLP-Mixer 的一个重要亮点是它包含两个主要的 MLP 层:一个独立应用于图像块(通道混合),另一个层跨块应用(空间混合)。
gMLP 还表明,通过避免使用自注意和卷积(当前 NLP 和 CV 的实际使用的方式),可以在不同的图像识别和 NLP 任务中实现很高的准确性。
读者显然不会使用 MLP 去获得最先进的性能,但它们与最先进的深度网络的可比性却是令人着迷的。
再次使用卷积网络:2020 年代的卷积网络
自 Vision Transformer(2020 年)推出以来,计算机视觉的研究围绕着 Transformer 展开(在 NLP 中,transformer 已经是一种规范)。Vision Transformer (ViT) 在图像分类方面取得了最先进的结果,但在视觉下游任务(对象检测和分割)中效果不佳。随着 Swin Transformers 的推出, Vision Transformer 很快也接管了视觉下游任务。
很多人(包括我自己)都喜欢卷积神经网络。卷积神经网络确实能起效,而且放弃已经被证明有效的东西是很难的。这种对深度网络模型结构的热爱让一些杰出的科学家回到过去,研究如何使卷积神经网络(准确地说是 ResNet)现代化,使其具有和 Vision Transformer 同样的吸引人的特征。特别是,他们探讨了「Transformers 中的设计决策如何影响卷积神经网络的性能?」这个问题。他们想把那些塑造了 Transformer 的秘诀应用到 ResNet 上。
Meta AI 的 Saining Xie 和他的同事们采用了他们在论文中明确陈述的路线图,最终形成了一个名为 [ConvNeXt]的 ConvNet 架构。ConvNeXt 在不同的基准测试中取得了可与 Swin Transformer 相媲美的结果。读者可以通过 ModernConvNets 库(现代 CNN 架构的总结和实现)了解更多关于他们采用的路线图。
结论
深度学习是一个非常有活力、非常宽广的领域。很难概括其中所发生的一切,作者只触及了表面,论文多到一个人读不完。很难跟踪所有内容。例如,我们没有讨论强化学习和深度学习算法,如 AlphaGo、蛋白质折叠 AlphaFold(这是最大的科学突破之一)、深度学习框架的演变(如 TensorFlow 和 PyTorch),以及深度学习硬件。或许,还有其他重要的事情构成了我们没有讨论过的深度学习历史、算法和应用程序的很大一部分。
作为一个小小的免责声明,读者可能已经注意到,作者偏向于计算机视觉的深度学习。可能还有其他专门为 NLP 设计的重要深度学习技术作者没有涉及。
此外,很难确切地知道某项特定技术是什么时候发表的,或者是谁最先发表的,因为大多数奇特的东西往往受到以前作品的启发。如有纰漏,读者可以去原文评论区与作者讨论。
原文链接:https://www.getrevue.co/profile/deeprevision/issues/a-revised-history-of-deep-learning-issue-1-1145664
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
计算机视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。
▲长按加微信群或投稿
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款
圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~