2019CVPR.Learning to Minify Photometric Stereo
时间:2022-12-19 05:30:00
摘要
表面法线可以通过给定一组在不同照明条件下获得的图像来估计。最近的光度立体方法需要大量的图像作为输入,以处理涉及图像形成过程的各种因素。通过学习不同照明条件下最有用的图像,可以显著减少对图像数量的需求。因此,我们使用深度学习框架自动学习输入所需的关键照明条件。此外,我们还提出了一种合成投影阴影的屏蔽层,可以有效地提高估计精度。在具有挑战性的现实条件下,我们评估我们的方法,在这种情况下,我们在光照条件下的数量大大减少,从而优于文献中的其他技术。
光度立体:
在最后一篇博客中,我们谈到了郎勃模型。以下是基于郎勃模型的传统光度立体算法
三维光度重建的质量取决于场景设置约束的满足,其基本假设包括以下几个:
(1)目标重建区域无阴影和高光;
(2)成像过程是线性的;
(3)远光源与入射光平行;
(4)投影过程符合正交投影要求;
(5)物体为朗伯表面;
传统的光度立体方法主要包括以下步骤:
(1)图像采集;
(2)相机内光照方向标定;
(3)检测阴影和高光;
(4)物体法向估计;
(5)积分重建;
如何计算表面方向,首先是郎勃模型的反射公式
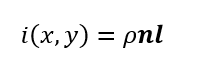
光度立体算法是在相机固定的情况下,通过改变光的方向,从多个不同的光图对目标物体进行三维重建的算法。具体的计算过程使用了上述反射公式,
光度立体的计算前提是要知道每张图的光方向和亮度矩阵,对应的公式是L和I,然后对上述公式进行变形,得到了,所以要求表面法向n变成了要求ρn因为ρ反照率是标量,所以得到了ρn说得到一个ρ因此,双单位法向量ρn单位化可以获得单位法向量
由于法向量的表示可以通过梯度表示,
所以,知道了n,求解p,q它已经成为解方程的问题p,q之后,其中p、q物体表面高度分别为zx、y方向偏导,梯度值表示:
最后对p,q积分得到物体的高度z,三维重建完成了光度立体法。
1.简介
光度立体技术是根据不同照明条件下拍摄的照片,从固定角度估算物体表面法线的技术。由于现实世界中材料的表面不同,需要一种处理一般反射率的方法。最新的方法是通过鲁棒估计来提高估计精度,但以增加图像数量为代价,如[21](2010年施柏信的一篇论文)。然而,这使得数据采集设置和校准过程变得复杂。
最近,基于深度学习的方法出现在光度立体的背景下[16、8、3]。这些方法表明它们对反射率不同的表面有效,表明即使有多样性,也能很好地建立从输入图像到表面线的映射。与这些主要关注估计准确性的方法不同,我们研究减少所需图像数量以最小化光度立体输入的问题。我们通过学习不同光源方向的相对重要性来解决这个问题,为轻量级数据采集开辟了选择最佳输入光源方向的可能性。
然而,由于表面辐射程度由照明强度、光源方向、表面法线和表面法线组成,因此很难在不损失性能的情况下减少输入光源的数量BRDF函数确定。例如,Argyriou在朗伯曲面的假设下,使用稀疏的照明表示所需的照明数量减少到5。然而,镜面反射和相互反射的存在使任务更加复杂。(意思是非郎勃表面上更难,这篇论文是理想情况下光源减少的)
在这篇文章中,我们提出了一种深接表的深度学习方法,可以选择与表面法线预测过程最相关的光源方向。为此,我们使用连接表来介绍训练输入图。使用此图L1范数和稀疏损失来训练的。训练模型后,只有当输入图像数量大幅减少时,才能在不降低精度的情况下有效估计表面法线。为了我们方法的可扩展性,我们使用观察图[8]选择光源方向,并以像素方式估计表面法线。
此外,为了解决全球照明的影响,我们明确解决了投影阴影的问题。具体来说,我们在网络中引入了一个屏蔽层,通过将投影阴影视为观察图上的局部零模式来处理投影阴影。总之,我们的贡献是:
1.我们在网络输入中提出了一个连接表,以及适当的损失函数和排序选择过程,以选择与表面法线预测过程最相关的光源方向。
2.我们提出了一个可以模拟物体投影阴影的屏蔽层。该屏蔽层可应用于数据增强和实际数据集,并可提高阴影区域的性能。
3.我们使用的端到端深度神经网络可以在减少光源数量的情况下预测表面法线。这与我们有关DiLiGenT基准测试[17]的结果是一致的,我们可以使用至少8个输入图像来预测表面法线。
图1.只使用8种输入性能,DiLiGenT 的“pot1”上的PSFCN [3]和CNN-PS [8]。本文的性能略胜。PS-FCN一些,比CNN-PS好很多
2.相关工作
光度立体文献非常丰富,但可分为以下几类:
最小二乘法:
伍德汉姆[20]提出,最小二乘法旨在解决朗伯假设的问题,即像素强度与光源方向和表面法线之间角度的余弦成正比。此外,他们通常认为表面是凸面的,没有投影阴影,具有均匀的朗伯反射率。朗伯的假设很重要,因为它允许将图像形成一个模型,并将其转换为一个可以以封闭形式解决的线性方程组。
稳定方法:
将非朗伯区域视为异常值,这些方法可以应对镜面反射,并在要研究的对象上施加阴影。 Wu等待[21]在图像形成模型中添加一个附加项,以自然地表示误差,解决偏离朗伯假设的像素,并使用秩序最小化来解决光度三维问题。在上述假设下,许多其他技术也被用来解决问题,例如RANSAC [14]期望最大化[22],稀疏回归[9]和变分优化方法[15]。
基于示例的方法:
这些方法以材料和表面几何示例为参考,估计示例相同或相似BRDF未知对象函数的表面法线。 Hertzmann和Seitz [5]对象上的材料聚类方法首次提出。Hui和Sankaranarayanan [7]用虚拟渲染球代替物理球进行法线估计。
深度学习:
这些方法是最近在光度学学立体声性能的最佳方法。 Santo等。[16]提出了基于深度网络的第一种像素估计方法。在他们的模型中,他们假设光的方向是已知的,在训练和预测阶段是一致的。虽然非常有效,但这种关于训练和测试集一致性的假设极大地限制了该方法的泛化能力,并使其对训练集过于敏感。 Ikehata [8]提出了一种非结构化光度立体输入的深度网络。该图旨在解释每个表面像素处的每个光源方向。虽然有效,但作者仍然假设照明图纸非常密集,当输入照明方向较少时,该方法很容易出错。 Taniai和Maehara [18]以另一种方式提出了一个无监督的网络,可以在输入时获取整个图像,并以端到端的方式预测密集的法线。但是这种方法的缺点是计算起来很贵。最近,徐等人。 为了学习基于图像的重光的最佳样本,提出了一个深层网络。
3.准备工作
本节首先提供光度立体的基本基础和符号。
1.反射辐照
假定光源从方向∈S2(3D单位向量空间)照亮表面点,辐照度(irradiance,反射率是albedo)为e。此外,该表面的反射辐照表示为r。表面法线表示为n∈S2。然后将BRDF函数表示为ρ(l,v,n),即入射和反射辐射l,v以及表面法线n的函数。
阴影可能出现在反射表面,因为法线和光源方向的变化。若法线与光的方向夹角为钝角,即l·n≤0,那么attached shadow(附加阴影)会出现。如果物体本身挡住了表面,如图2所示,也会出现cast shadow投射阴影。结果,观察到的反射光r(v)可以写为,max(l·n,0)解释了attached阴影,如果乘积小于0,即入射光和法线成钝角,自然会有下图attached阴影,如果大于0,则有光强。
r(v)是reflected radiance 反射辐射率是指表面反射到v方向的反射光的辐射率
其中Q∈{0,1}是投影阴影处的二进制变量,假设阴影区域没有相互反射。因此,只要光线被物体堵塞,指示器变量Q就会设置为零
注:辐射率实际上可以看作是我们眼睛看到的物体的一点颜色(或相机拍摄)。当基于物理着色时,计算表面的颜色是计算其辐射率。
我们看到一个表面,实际上是周围环境的光照射到表面,然后表面向我们的眼睛反射部分光。双向反射分布函数BRDF(Bidirectional Reflectance Distribution Function)描述表面入射光与反射光的关系。
对于一个方向的入射光,表面会将光反射到表面上半球的各个方向不同方向的比例不同,我们使用BRDF指定方向反射光与入射光的比例关系
图2。DiLiGenT数据集数据[17]harvst”上的阴影区域。注意cast阴影是由遮挡造成的(上面),而attached阴影区域相对于光源是朝后的。在图的右边,我们展示了两个从cast阴影中获得的观察图。观察图上的红色虚线表示遮挡光线的形状。
遵循常规的校准光度立体问题,我们假设在每种照明条件下都给出了光的方向l和强度e。另外,我们假设光源在图像上方一定距离。为了简化随后的方程式,我们认为相机处于正交位置,因此v为[0,0,1]。最后,在不损失一般性的情况下,我们使用相对强度m =r/e将公式(1)改写为
注1:
https://www.cnblogs.com/herenzhiming/articles/5789043.html
这个博客解释了为什么BRDF函数被定义为辐射率和辐照度的比值,也就是这里说的m
注2:
改写之后这个公式就可以被视为图像形成模型了,贴一个从参考文献8搬过来的图像形成模型
现实世界对象的各种外观可以通过BRDF函数ρ进行编码,ρ将观察到的强度Ij与表面法线n∈R3(笛卡尔空间坐标系),第j个入射照明方向lj∈R3,它的强度为Lj∈R(实数)和出射视线v∈R3相关联,通过上式,其中max(nlj,0)解释了attached阴影,Ej是模型的附加误差。 等式(1)通常被称为图像形成模型。ρ是漫反射系数大多数光度立体算法采用ρ的特定形状,并通过反求解方程1从来自m个不同光照条件下(j∈1,···,m)的观察值集合。来恢复场景的表面法线。
通常,所有未用BRDF表示的效果(图像噪声,投射阴影,相互反射等)都放在Ej中。
注意,当BRDF为Lambertian且去除了附加误差时,它简化为传统的Lambertian图像形成模型[12]。
2.观测图计算
我们遵循Ikehata [8]并采用观测图。回想一下,观察图是3-D半球中所有照明方向的2-D投影。更正式地,假设在光的方向是由向量l = [lx,ly,lz]⊤在x,y,z坐标系中给出的。与Ikehata [8]相反,我们不直接使用笛卡尔坐标,而是通过将笛卡尔向量l投影到极坐标系(球极坐标,即空间极坐标系)中来计算观测图,该极坐标系的分量由
在这里,我们使用了与Ikehata [8]相比不同尺寸的观测图(参考8中使用的尺寸是3232,作者比较了w = 8、16、32、64,并发现w = 32在图像数量少于一千时显示出最佳性能,而本文使用的观察图是1414),并且注意到对于这种尺寸的观察图,极坐标的性能优于笛卡尔坐标系。
然后可以将窗口大小为w的观察图
的项
设置为m(m就是下面光源方向选择的相对强度)。在上面的索引中,b是θ和φ范围的上限和下限包含的范围,并且int(·)是舍入运算符,是传递与其自变量最接近的整数的四舍五入运算符,而∆θ和∆ϕ是每个图索引之间的角度差,由确定。
以这种方式,观察图将无序输入转换为有意义的特征图,该特征图捕获了在不同光源方向下物体的反射参数们之间的关系。如图2所示,地图上的每个值自然会编码表面反射率r,光源方向l和强度e的信息。此外,该图还可以被视为法线n,BRDF ρ值和投射阴影指示变量Q的一组函数。
3.光源方向选择
现在,我们将注意力转向与光度立体过程最相关的那些照明方向的学习,从而最大程度地减少计算表面法线所需的视图数。从数学上讲,如果我们有k个不同的照明,且方向 ,则对于光的每个方向,一个表面上的点的相对强度由 给出。然后,对于每个曲面点,我们都有一个给定
的方程组,其中 是编码不同光照下投射阴影信息的向量,◦表示Hadamard乘积,即按元素的乘法算子,(其实也就俩值,一个0,一个1)同样,vmax是元素级的max运算符,用来确定有没有attached shadow影响。因此,我们的目标是解开方程组,使得k尽可能小。
4.本文提出的方法
我们提出了一种神经网络,该神经网络可以将稀疏照明作为输入,并预测表面法线,但精度会略有下降。如图3所示,观察图可以将不同的照明方向编码为特征图(意思是一个表面点就有一个观察图,这个观察图上的每个值都是不同的光照方向,并且值等于上面说的m),从而可以在输入空间上进行选择。然后,遮挡层使系统对投射阴影鲁棒。对于网络本身,我们使用了DenseNet [6]体系结构的一种变体。
为了选择相关的光源方向,我们在深度网络的输入端使用了一个可学习的连接表。随着网络的训练,我们的方法可以通过输入比其他文献中其他方法少得多的光源方向来准确预测表面法线。
图3.我们的网络概述。给定物体在不同光照下的图像,我们可以在每个像素处计算其对应的观察图。然后,我们应用遮挡层,该遮挡层用作二进制过滤器蒙版,以便将观察图的区域归零。然后,我们使用学习的连接表来权衡输入中的特征图。训练后,对于我们的网络预测表面法线,仅需要几个与连接表的非零权重相对应的照明即可。
1.连接表
据我们所知,还没有基于学习的方法旨在找到用于光度立体的相关输入特征图。但是,与深度网络有关,Alvarez等人[1]使用稀疏约束来规范化深度神经网络的训练过程。Koray等 [11]减少了参数的数量,因此减少了深度网络的复杂性,它使用二进制连接表来“断开”特征图,并形成一个随机集合。Wei 等人[19]采用一维连接表在成像光谱学中进行谱带缩减。这些与我们的方法不同,我们的方法旨在恢复在观测图上具有非二进制权重(也就是说表里的项的权重不是非1即0,也就是和参考文献11不同,再者是个二维的,就又和参考文献19不同)的二维稀疏输入连接表。
注:参考文献19做的工作是对光谱图像数据进行频带缩减,旨在减少频带长度去恢复光谱辐照度,因此本文借鉴了一下连接表的概念,用来从减少了灯光数的图像集中估计像素法向
1.1稀疏表计算
用C表示输入连接表。将该表应用于遮挡层之后的观察图。现在,我们将重点放在连接表上,并将在稍后的文章中进一步阐述遮挡层。该表有效地充当输入选择器,从而在训练时学习连接权重。请注意,连接表的大小与观察图相同, ,其所有参数都大于或等于零, 。然后,稀疏观察图由观察图被遮挡层“过滤”之后生成。这将生成一个稀疏的观察图,作为网络的输入。
原文提到了一个算法:
Levenberg Marquardt算法(LMA)[14]是一个迭代的信任区域过程[17],它为数值函数在参数空间上最小化的问题提供了数值解决方案。是一个最优化方法,感觉下面的策略最小化k就是用的这个。
然后,网络的loss函数由两个项给出。第一项解释表面法线预测,我们使用均方误差。第二项是对连接表的正则化。它们产生自
给出的loss,其中n和n’分别是预测的和groundtrueth表面法线,g(·)表示正则化函数,而λ是控制正则化对总loss的贡献的超参数。因此,较大的λ将强制执行更稀疏的连接表,相反,较小的λ将产生较密的连接表。
注意,以这种方式,连接表可用于选择输入的最相关的光源方向。观察图中的这些方向由相对于光照方向的角度定义,即∆θ = ∆ϕ = 2b/w-1。这是一个重要的观察结果,因为连接表也可以解释为与光源方向的相应范围相关,这使该方法对于光照方向的小变化更加稳健。
1.2连接表的训练
在这里,为了使连接表稀疏,我们使用
给出的正则化函数,正则化的过程就是筛选特征的过程,其中α是map的最大值,即
请注意,上述方程是要最小化的,因为连接表权重趋于零。此外,在反向传播的每个步骤中,可以使用
给定的导数以直接方式更新连接表,由于定义上的连接表为非负,因此导数 取值在[1,2]范围内。
有了连接表,我们可以应用选择策略来选择网络中k个最重要的输入。为此,我们使用循环训练方案,并且在每次训练操作中,我们应用具有指数衰减的等级选择,即 ,其中t = {0,1,2,…}是迭代次数,c,β和τ是标量参数。引用的文章里,τ是常量1,值得一提的是,我们对非空的表项的数量选择指数衰减,让人联想到文献中其他方法中的annealing methods和rank selection approaches的指数冷却策略。
2.遮挡层
回想一下,投影阴影(cast shadows)是光度立体中最具挑战性的问题之一。当输入光源方向的数量少时,尤其如此。 Santo等[16]通过利用他们网络中的阴影层解决这个问题,该阴影层将一些输入随机设置为零。
尽管有效,但是他们的方法没有考虑到投射阴影通常相对于照明方向是一起存在的,而不是随机发生的。为了说明这一点,我们在图2中显示了从“harvest”对象中阴影区域获得的观察图。投射阴影是由布料上的皱纹引起的,并显示出具有相对清晰边界的一致图案。从图2局部看,平滑或平坦的遮挡会导致直线边界,而对象几何形状的突然变化通常会产生更陡峭的边界。
因此,这里我们采用遮挡层,该遮挡层可以通过在观察图上随机绘制一条线来获得蒙版,然后将其用于将图的相应条目设置为零,从而有效地模拟投射阴影。和其他论文里那个随机置0的方法不一样。具体来说,图层会随机选择地图的两侧,并在每一侧随机选择一个点。然后,连接这两个点的线将地图分为两个区域。然后将这两个区域中的较小者设置为零。这在图4中进行了说明。通过使用此遮挡层训练网络,我们提出的方法可以有效地了解投射阴影的图案,并更可靠地预测表面法线。
图4.与随机置零相比[16],由遮挡层处理的观察图。注意,遮挡层有效地模拟了由投射阴影引起的观察图中的图案。
5.方案实施
观察图的参数
对于观察图,我们将窗口大小w设置为14。将 的上下边界设置为π/ 4。有了这些参数,我们便可以随机选择5%的观察图放置我们的遮挡层,以模拟投射阴影的效果。此外,我们还随机将观察图的5%点设置为零。我们将在Sec6.2中进一步讨论对这部分观察图的选择。
预训练
对于连接表,如前所述,我们在递归训练网络时执行等级选择。为此,我们将表初始化为全1,然后进行预训练。对于预训练,我们使用
给出的替代损失函数,其中f(·)由ℓ1-范数正则化函数给出。
在训练前使用ℓ1-范数和稍后使用正则化器g(·)的原因是,与g(·)的行为相反,ℓ1-范数随着连接表条目趋于零而减小。因此,我们采用了ℓ1-范数来为训练提供良好的初始化,并在式(5)中使用正则化器对表中接近于1或接近于0的值进行偏向选择。而且,尽管使用ℓ1范数时λ可以控制连接表的稀疏性,但随着λ的增加,控制稀疏性会很快变得无效。为了说明这种行为,我们在图5中显示了在训练前使用不同λ值获得的连接表。从图中我们可以看到,当λ增加到10-1以上时,连接表几乎没有变化。
图5。
连接表的可视化(裁剪)以及验证集上的平均角度误差与λ的关系。
知乎摘的别人的说法:感觉这里说的等级选择就是消除特征
https://zhuanlan.zhihu.com/p/37310887
连接表排序选择
如上所述,我们首先对网络进行预训练。在这里,我们为预训练操作设置了λ= 10-3,然后通过一系列后续的反复训练步骤将排序选择应用于连接表。如前所述,通过这种方式,我们选择了前k个最大权重,其中k在训练过程中从数据集中的所有照度(96)逐渐减少到6,依次减少为55、30、16、10、8、6。
在图6中,我们显示了施加排序选择之后每个训练步骤的连接表。在左侧面板中,我们显示在选择学习表的55个最重要元素,并将其余设置为零后,在第一步训练步骤中获得的连接表。第二个面板从左到右显示该表,其中第二个训练操作之后已选择了30个最重要的条目,依此类推。对于所有训练操作,我们都设置了λ= 10-3。请注意,这与我们的预训练操作一致。
图6.等级选择后的连接表(已裁剪)。 从左到右,每个面板显示表格,当非零值的数量减少到6时。第一行显示使用ℓ1-范数正则化器生成的映射。 第二行显示使用等式(5)中的正则化功能获得的映射。
数据集
为了训练我们的网络,我们使用Blobby形状数据集[10]的10个形状和MERL BRDF数据集[13]的100个反射率生成了一个合成数据集。为此,我们随机选择8个BRDF,以使用144个随机分布的光方向重复渲染每个对象。为了保持一致性,我们使用了与DiLiGenT [17]数据集中相同的光方向范围。
我们选择9种形状进行训练,剩下一个选择进行验证。因此,我们的合成数据集包括大约9×10四次方×8 = 720,000个用于训练的观察图和大约80,000个用于验证的观察图。对于测试,我们使用DiLiGenT [17]数据集,这是一个包含10个不同对象的图像的真实的公共基准。在96个不同的已知光方向上观察每个对象,在以观察方向为中心的半球中,水平方向的范围是-45°至45°,垂直方向是−30°至30°。表面法线groundtruth已使用激光扫描仪获取,可用于定量评估。
6.实验
对于我们所有的实验,我们都使用默认设置的Adam [12]优化器对网络进行了训练。该网络使用Keras以Tensorflow框架,在使用Ubuntu 14和NVIDIA GTX 1080Ti 11G的工作站上运行。
为了量化误差,我们在所有实验中均使用了平均角度误差(MAE)进行表面法线评估。在这里,我们将通过我们的方法获得的结果与使用可用于稀疏输入的许多替代方法[16、3、8、9]获得的结果进行比较。我们还说明了损失函数和遮挡层的有效性,并显示了按像素进行法向估计的结果。
1.正则函数的有效性
为了说明我们的正则化函数g(·)在损失函数中的有效性,我们现在比较当使用其他正则化函数时网络的性能。在表1中,“ Ours-g(·)”表示使用等式(5)中描述的函数g(·)训练的网络。当使用ℓ1范数正则化函数替代g(·)时,“Ours-L1”对应于我们的网络所产生的结果。最后,“ Ours-Random”对应于不包含正则化器且,损失函数和连接表是随机初始化,而没有经过预训练的。所有其他方法均使用随机选择的输入进行测试,显示的所有结果均在10个模型(因为diligent上有十个模型)上取平均值。从表中可以看出,带有稀疏正则化函数g(·)的模型表现最好,并且明显优于ℓ1-范数和随机初始化。
表1.在不同数量的输入光方向的DiLiGenT数据集上测试的性能(有关更多详细信息,请参见第6.1节)。
2.遮挡层评估
现在我们将注意力转移到遮挡层的效果上。为此,我们已经使用自己的遮挡层和Santo [16]等人提出的遮挡层对网络进行了训练。并设置k = 10,即在输入时使用了10个光方向。在这里,我们已经在合成数据集和DiLiGenT上训练了网络。
表2.我们在10个照明方向的DiLiGenT数据集上的遮挡层和随机归零的比较[16]。
在表2中,我们显示了遮挡层的影响以及Santo [16]等人提出的影响。请注意,在我们的合成数据集中没有cast阴影。这与DiLiGenT数据集中的真实对象形成对比,后者显示出多种阴影和相互反射。此处显示的比较的目的不仅是展示与[16]中相比,我们的遮挡层的优点,而且还表明它可以有益于训练真实世界和合成数据集。
另外,请注意,表中的百分比对于两种方法都具有不同的含义。对于我们的遮挡层,百分比表示在训练过程中有多少观察图被遮挡层“掩盖”了。尽管随机置零的百分比遵循[16]中的设置,但表示每个输入图上有多少像素随机设置为零。(对所有输入图都是5%像素被遮盖)
从表中可以看到,当遮挡了5%的输入观察图时,遮挡层的性能会更好。对于随机置零策略,最佳性能似乎也约为5%。尽管如此,无论使用什么百分比,通过遮挡层始终可以实现最低的误差。
最后,我们在图7中的DiLiGenT数据集中显示了许多样本对象的误差图。所示的误差图对应于遮挡层产生的MAE与随机归零产生的MAE之间的差异。因此,负区域,即图7中的蓝色区域是遮挡层胜过替代区域的区域。从图中可以清楚地看到,在大多数凹凸不平和起皱的区域中,阴影更强,遮挡层的表现要好得多。这与我们的遮挡层可以帮助网络应对投射阴影的观点是一致的。
图7.我们的遮挡层相对于随机归零的性能比较[16]。面板中的蓝色对应于遮挡层胜过随机置零的区域。相反,红色区域则是不如随机置零的。我们可以看到,在“猫”图像中,大部分肩膀区域的遮挡层都更好。在非常有纹理的“ Buhhda”图像中,我们的方法在所有布料皱纹的模型上都优于随机归零。所有这些区域都对应着投射阴影。
3.稀疏输入下的基准比较
我们首先将我们的方法与使用DiLiGenT数据集的其他最新方法进行比较。对于稀疏照明中的替代方案所产生的结果,与我们的方法相反,我们随机选择了要考虑的最多k个输入光源方向,请注意,这与作者提出的稀疏输入设置一致。
表1中显示了10个模型上数据集的MAE。请注意,在表1中,除PSFCN [3]外,所有方法均以像素方式估算表面法线。由于逐像素方法自然会舍弃像素与形状之间的联系,因此稀疏的输入设置(如此处使用的设置)预计会大大降低性能。如我们所见,CNN-PS [8]的性能在6个输入时从7.20降低到30.28。相比之下,我们的方法没有表现出这样的性能损失,胜过其他逐像素方法。我们可以看到,从16个输入开始,我们的方法开始显示其选择光源方向的能力,从而避免过度降低性能。在10和8个输入方向上,相对于其他方法,我们的方法在性能上有很大的提高。而且,我们的方法显示出从96到16个输入方向的MAE性能降低至1.25度,从16到10个输入方向的性能仅降低0.3度。
另外,请注意PS-FCN [3]是一种密集的法线估计方法,它考虑了整个图像。因此,PS-FCN [3]在稀疏输入方面自然具有优势,因为它可以利用像素间的结构信息。但是,在光源方向为10个或更少的高度稀疏照明设置中,我们的方法可以比PSFCN [3]更好。在表3中,我们还显示了我们的方法的性能以及DiLiGenT数据集中每个对象上10个和8个输入的其他方法的性能。在图8中,我们显示了DiLiGenT的“高脚杯”对象的表面法线和误差图。
表3.具有10和8个输入照明方向的DiLiGenT数据集上的结果。 所有替代方案均使用随机选择的输入进行测试。 显示的所有平均角度误差均对应于10个模型的平均性能。
表4列出了我们和其他方法在相似光配置下的平均角度误差。第一行(Random)显示了从半球的均匀分布中随机采样10盏灯时的结果;第二行(Ours)是与由非零表目连接图学习,相对应的灯光方向下的结果,这是我们的方法。第三行(最佳)对应于Drbohlav和Chantler [4]提出的最佳光照方向的配置。请注意,这些光线方向与DiLiGenT中提供的光线方向不完全匹配,我们使用DiLiGenT数据集中最接近的光线方向进行测试。在最佳光配置下,我们的方法优于除了PS-FCN [3]之外的所有方法。
表4.使用随机采样(Random),我们的方法(Ours)和[4]中的方法获得的相同10个光照方向在DiLiGenT基准上的平均角度误差。
逐像素法线估计
最后,我们提出了逐像素和密集法线估计之间的比较。在图9中,我们显示了我们的方法和PS-FCN [3]在具有挑战性的合成物体上产生的结果。在图9中,我们使用了Blobby [10]中的一个对象,该对象已从训练集中排除,并从MERL [13]中随机选择了一个BRDF函数来渲染该对象的每个像素。然后,我们仅使用8个输入来测试这两种方法。请注意,PS-FCN [3]受BRDF与物体几何形状之间的关系的影响,而我们的方法尽管有一些噪音,但仍能很好地恢复物体自身的表面法线,性能优于PSFCN [3]。
7.结论
在本文中,我们提出了一种深度学习方法,该方法应用了连接表,该连接表可以选择与表面法线预测过程最相关的光源方向。并且本文显示了模型经过训练后,如何仅在输入图像数量大大减少的情况下才能有效地估计表面法线,而不会降低精度。此外,我们通过在网络中引入遮挡层来明确解决投射阴影的问题。通过将我们的结果与许多替代方法得出的结果进行比较,我们说明了我们提出的方法在光度立体上的实用性。


