多传感器融合之雷达图像数据集自动生成 - 20220613
时间:2022-08-28 03:00:00
文章目录
- Automatic Radar-Camera Dataset Generation for Sensor-Fusion Applications
-
- 1. Radar Camera Co-Calibration
- 2. ROS pipeline
- 3.Sensor-Fusion Data-Set Generation
- 4. Radar-Only Data-Set Generation
- 5. Sensor Fusion Feature Representation
- 6. 实验结果
Automatic Radar-Camera Dataset Generation for Sensor-Fusion Applications
Sengupta A, Yoshizawa A, Cao S. Automatic Radar-Camera Dataset Generation for Sensor-Fusion Applications[J]. IEEE Robotics and Automation Letters (二区, IF:3.741), 2022.
Code : github.com/radar-lab/autolabelling_radar
本文提出了基于多传感器数据集成的新方法YOLOv3的高精度目标检测从相机自动标记点云数据中生成标记雷达图像和雷达数据集。
- 首先校准视觉和雷达传感器,并获得一个雷达到相机的变换矩阵。
- 采用基于密度的聚类方法将收集到的雷达回波信号与不同的目标分离,并将聚类纹理投影到相机图像上。
- 然后使用匈牙利算法将雷达聚类质地与YOLOv3生成的目标框质心相关,并用预测类标记。
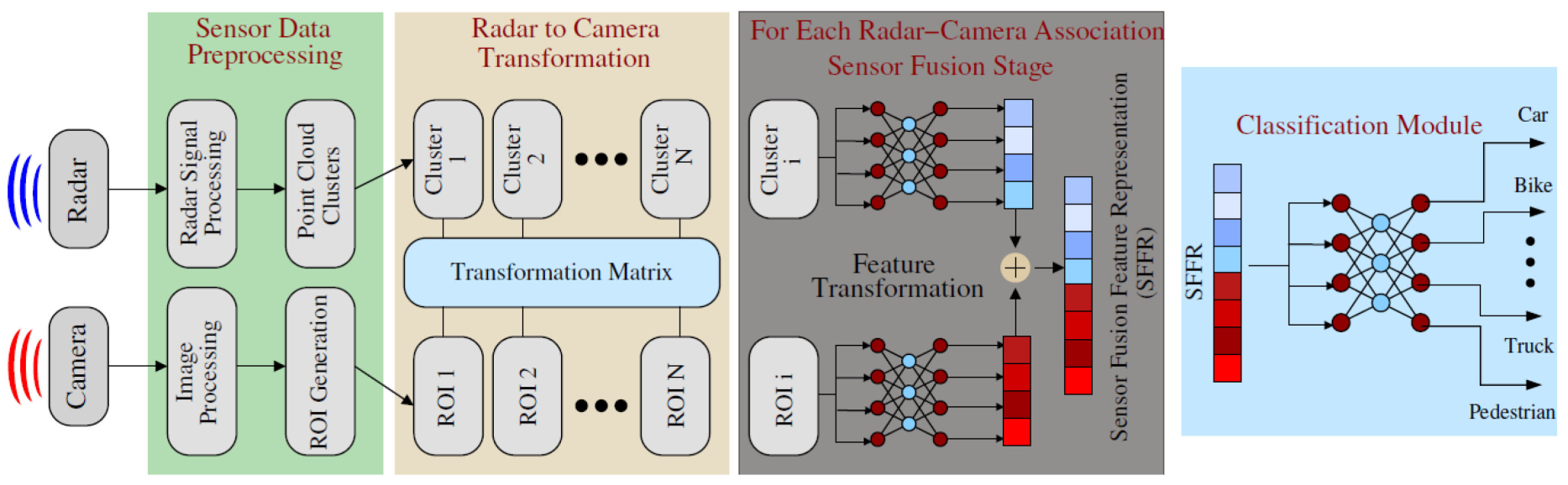
基于传感器集成的典型目标识别方案包括四个阶段,即 (i)数据采集和预处理,(ii)协同校准和关联传感器,(iii)表示传感器融合特性(SFFR),然后是(iv)分类网络,如图1所示。
- 首先,采集摄像机和毫米波雷达的检测结果进行预处理,利用协同校准变换矩阵将雷达检测簇投影到摄像机图像平面上。
- 从图像数据中检测到的对象通过边界框本地化,边界框中的区域称为感兴趣的区域(ROI)。ROI与这些地区的雷达集群有关。
- 然后,每一个ROI-Cluster从单个传感器的数据中集成/拼接单个特征提取网络并表示转换后的特征SFFR。
- 然后,该SFFR全连接多层传感器(MLP)直到分类输出层。此外,“回退”网络也必须能够使用传感器的数据单独识别/分类对象,特别是在有不相关的ROI/集群。这是为了解释由于视场有限、电子故障、屏蔽或光线不足而导致的单个传感器故障,尽管它的可信度低于基于SFFR的分类。
1. Radar Camera Co-Calibration
采用张氏标定程序获取相机的内部参数。边缘尺寸为22.14 mm的9 × 6棋盘格图案作为校准板,采用张氏方法实现两个软件,即MA TLAB相机校准工具箱和ROS估计相机校准器USB-8MP将相机模块的内部参数(包括径向和切向失真参数)放置在一个3中-D静态三脚架安装在打印框架上,离地面1米高。
数据收集设置:(a)运行Ubuntu 18和ROS Melodic的NVidia Jetson Xavier使用UART通过USB集线器从相机-雷达系统捕获数据;(b)两个雷达安装在3-D打印线性轨道上,使用M螺栓固定,间隔23cm;将两个雷达的数据投影到图像上进行数据关联。YOLO输出包围盒中的雷达投影决定了共校准精度。
2. ROS pipeline
通过雷达和相机的数据ROS获得管道的包主要有三个,即(i) mmWave_radar;(2) usb_webcam;和(3)darknet_ros。
mmWave_radar将配置加载到雷达上,缓冲雷达处理的数据,并显示其发布界面。
usb_webcam包从相机(30fps)读取原始图像,使用估计的相机内部参数来纠正和不扭曲图像,发布为压缩消息,并随时间戳头。
darknet_ros包使用OpenCV桥来订阅修正后的图像,并将其归类为YOLO该网络通过新闻输出图像中物体的边界盒和类别,以及图像采集和预测时间戳。
3.Sensor-Fusion Data-Set Generation
第一个数据集由给定帧中同一物体的标记雷达图像组成,覆盖所有N帧。
首先,利用参数聚集雷达点形成帧雷达PCL数据。然后,使用第III-A节估计的Radar-to-Camera变换矩阵T M,将星团的三维纹理投影到场景对应的相机图像上。然后确定相应的YOLO边界框和类YOLO匈牙利算法帧中的雷达-图像关联质地和投影雷达簇质心的像素指数。
每个相关的YOLO聚类对(i),边框中的图像区域被切割和重塑为64 × 64 × 3 png文件(CropImg),和(ii)雷达聚类中的所有点X、Y、Z、以多普勒和信噪比为准Numpy阵列保存到磁盘,以YOLO类别为标签。上述中间步骤通过图3中的示例进行描述。算法1中给出了生成数据集的步骤。
4. Radar-Only Data-Set Generation
第二个数据集由雷达数据的标记连续帧组成,以帮助只使用雷达数据识别目标类别的应用程序。
如图4所示。就像以前的情况一样,雷达点首先组合起来产生帧级3-D雷达PCL数据。每一帧DBSCAN,分离不同的目标PCL簇。在每一帧(i > 1)利用匈牙利算法对帧间聚类-聚类关联进行比较和分配,几乎是一种伪跟踪的方式-D聚类质心。每一个图3。首先使用DBSCAN每帧雷达PCL分离成簇。然后利用匈牙利赋值法并行获得投影的聚类纹理YOLO包围盒的质心是相关的。图4显示,照明不良导致相机辅助YOLO8帧连续10帧未检测到行人,雷达可连续检测到目标。当第一次检测到纹理时,唯一的航迹ID被分配给它,任何后续的相关集群都附加到下一帧中的相同航迹中ID。同时,另一个匈牙利算法模块检查一个投影的簇纹理是否可以在给定帧中使用YOLO预测相关性。如果YOLO分配是可能的,轨迹ID相关的将用于该框架YOLO标记类信息。请注意,一条航迹ID有雷达探测,比如N个连续帧,只有M < N帧可以有相关的基础YOLO的标签。这里的想法是,如果一个物体被雷达连续跟踪几帧,并且在跟踪过程中随时都被图像辅助YOLO识别后,跟踪中的整个雷达数据可以标记为特定的YOLO类。然而,为了使标记更可靠,我们在所有帧中使用和给定曲目ID所有相关联YOLO预测统计模式(),并将最频繁的预测类别分配给曲目作为最终标签。然后从1中提取3个连续帧- 3,2 -4、3-5滑动,生成数据集。到(N-2)-N帧,从每个磁道ID标记为模式(YOLO将其保存到磁盘中Numpy阵列。请注意,<对象/轨迹3帧id整个过程中只有一个和/或YOLO预测的轨迹id它们都被排除在这个数据集之外。算法2中给出了生成数据集的步骤。
5. Sensor Fusion Feature Representation
本研究使用的数据集是第三个- c生成了节概述的方法。数据集包括V车、行人、自行车和摩托车的10838、2860、13和31雷达图像。由于Bicyclists和Motorbikes我们只使用类别不平衡和数据不足V vehicle和Pedestrian数据进行分类任务。另外,为了保证两类之间的类大小平衡,我们从V车类中随机抽样了2680个数据点。首先,雷达空间PCL在每个三维空间差异中,数据、多普勒和信噪比生成12维雷达特征向量的谎言)在每个三维空间上的差异,b)空间协方差之间的三维双,c) V径向距离变异,d)和e)这意味着雷达截面的方差和总和(RCS)算使用信噪比作为RCS = 1 0 l o g R4 +信噪比,在dBsm表示。每个数据点的相关图像大小固定为64 × 64 × 3。神经网络接受两种输入:一张64 × 64 × 3的图像;以及1×12雷达特征向量。经过几个阶段的初始特征转换后,使用i) CNN+Pooling对图像;和ii)雷达特征向量上的全连接密集层,将输出进行级联,形成传感器融合特征表示(SFFR)。然后,该SFFR进行进一步的特征转换,直至分类层,如图5所示。
6. 实验结果
数据集被打乱并拆分为80%-5%-15%的训练、验证和测试数据。利用Adam优化器对模型进行训练,目标是最小化稀疏分类交叉熵。基于SFFR的方法对车辆类别的测试准确率为95%,对行人类别的测试准确率为99%。我们还探索了SFFR相对于单个传感器数据的优势。我们使用相同的训练和测试数据来评估三个模型,即(i)如上所述基于SFFR的分类网络,(ii)直接使用Global Max-Pool输出进行进一步特征变换(即不连接雷达特征向量变换)的仅图像分类网络,(iii)仅雷达分类网络,直接使用初步变换输出进行进一步的特征变换(即不拼接图像数据变换)。
我们使用基于LSTM的分类网络(图7(a)),在连续3帧上连续提取1 × 12的特征向量,并利用时间特性进行特征变换。同样,由于类别不平衡,我们在本研究中使用了相同数量的V车辆和行人类别的数据点。仅利用雷达数据(3帧连续),LSTM模型对车辆和行人进行分类的测试精度为≈92%。此外,我们还探索了基于1-D CNN的架构(图7(b)),这是时间数据网络中另一种流行的选择,与基于LSTM的方法相比,精度进一步提高了约1.5%。这里需要注意的另一个现象是,使用多个雷达帧似乎比上一节中只使用一帧雷达分类器提供了更高的分类精度。
ROC曲线及AUC评分如图8所示。
们使用了两个样本神经网络来证明数据集的有效性,以及使用传感器融合方法比单一传感器模式的优势(表2)。数据收集期间的一个主要挑战是流量模式的不同性质,这反映在所收集数据的类别不平衡。


