Kubernetes网络浅析
时间:2022-08-12 11:00:02
每个Pod拥有唯一IP
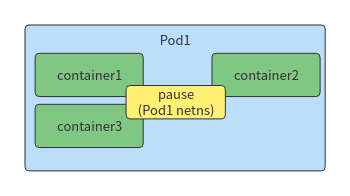
这个Pod IP被该Pod所有其他容器共享和所有其他容器Pod可以路过到这里Pod。Kubernetes有些节点在运行"pause"它们被称为沙盒容器(sandbox containers)",唯一的任务是保留和持有网络命名空间(netns),命名空间被Pod所有容器共享。这样,即使一个容器死了,新的容器也会被创建来取代它,Pod IP也不会改变。这种IP-per-pod模型的巨大优点是,Pod和底层主机不会有IP或端口冲突。我们不必担心应用程序使用的端口。
1、Kubernetes网络实现
隧道方案
隧道方案在IaaS层网络也有很多应用,会pod分布在大二层的网络规模下。网络拓扑很简单,但随着节点规模的增加,复杂性会增加。
- Weave:UDP广播,本机建立新的BR,通过PCAP互通
- Open vSwitch(OVS):基于VxLan和GRE但是性能损失比较严重
- Flannel:UDP广播,VxLan
- Racher:IPsec
路由方案
路由方案一般从3层或2层实现隔离和跨主机容器交换,出现问题容易调查。
- Calico:基于BGP协议的路由方案支持非常详细ACL对混合云的控制亲和力较高。
- Macvlan:从逻辑和Kernel根据二层隔离,需要二层路由器支持,大多数云服务提供商不支持,因此混合云难以实现。
2、Kubernetes Pod网络创建过程
- 每个Pod除了创建时指定的容器外,还有一个kubelet启动时指定的基本容器
- kubelet创建基本容器,生成network namespace
- kubelet调用网络CNI driver,根据配置调用具体情况CNI 插件
- CNI 插件为基本容器配置网络
- Pod 其他容器共享使用基本容器
3、Flannel
3.1 Flannel特点
- 使集群不同Node主机创建的Docker集群中唯一的虚拟容器IP地址。
- 建立覆盖网络(overlay network),通过这个覆盖网络,将数据包完好无损地传输到目标容器。覆盖网络是一个基于另一个网络并由其基础设施支持的虚拟网络。覆盖网络将网络服务与底层基础设施分开,将一个分组包装在另一个分组中。将包装数据包转发到端点后,解开包装。
- 创建新的虚拟网卡flannel0接收docker通过维护路由表,对接收到的数据进行封包和转发(vxlan)。
- etcd保证了所有node上flanned配置是一致的。同时,每个node上的flanned监听etcd实时感知集群中的数据变化node的变化
3.2 Flannel互不冲突IP
-
flannel通过flanneld,利用etcd存储整个集群的网络配置
-
flannel在每个节点中运行flanneld作为agent,flanneld主机将从集群的网络地址空间中截取一小段subnet,当前节点所有容器IP地址都从该subnet分配网段
# 具体的subnet文件/网段记录run/flannel/subnet.env中 cat /run/flannel/subnet.env FLANNEL_NETWORK=10.244.0.0/16 FLANNEL_SUBNET=10.244.1.1/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true
3.3 Flannel基本架构
不同节点之间的通信
解释各组件:
-
vethxxx:Veth Pair该设备的特点是总是使用两张虚拟网卡(Veth Peer)形式成对出现。其中一个网卡发出的数据包可以直接出现在另一个对应的网卡上。其主要功能是将容器连接到虚拟交换机,实现容器的网络连接。
-
cni0:每创建一个网桥设备pod都会创造一对veth pair。其中一段是pod中的eth0,另一段是cni0网桥端口(网卡)。pod中从网卡eth0发出的流量将发送到cni0网桥设备端口。
cni0是k8s使用抽象网桥cni0替代了docker0网桥,需要注意的是,cni0网桥只接管所有CNI插件负责,即k8s创建的容器(pod),如果此时用docker run单独启动容器,然后Docker该项目仍将连接到该容器docker0网桥上。
# cni0网卡信息,在有pod可通过节点ip a(centos)查看 $ ip a 5: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000 link/ether 3a:74:dd:49:27:3b brd ff:ff:ff:ff:ff:ff inet 10.244.1.1/24 brd 10.244.1.255 scope global cni0 valid_lft forever preferred_lft forever inet6 fe80::3874:ddff:fe49:273b/64 scope link valid_lft forever preferred_lft forever # 通过查看网桥信息,可以看到连接pod虚拟网卡都连接在一起cni0网桥上 $ brctl show bridge name bridge id STP enabled interfaces cni0 8000.3a74dd49273b no veh186d8024 veth4979a90a vethf6640065 docker0 8000.024238c830e9 nocni0的IP地址,是该节点分配到的网段的第一个地址
-
Flannel.1:overlay网络设备,用来进行vxlan报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对断
# flannel.1网卡信息,在有pod的节点上可以通过ip a(centos)查看 $ ip a 4: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default link/ether 1e:de:a9:58:8c:fb brd ff:ff:ff:ff:ff:ff inet 10.244.1.0/32 scope global flannel.1 valid_lft forever preferred_lft forever inet6 fe80::1cde:a9ff:fe58:8cfb/64 scope link valid_lft forever preferred_lft forever -
Flanneld:flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac,ip等网络数据信息。
3.4 不同node上的pod的通信流程
假设一个数据包要从pod1到达pod4(在不同的节点上)。
-
它由
pod1中netns的eth0网口离开,通过vethxxx进入root netns。 -
然后被传到
cni0,cni0通过发送ARP请求来找到目标地址。 -
本节点上没有Pod拥有
pod4的IP地址,因此数据包由cni0传到 主网络接口eth0. -
数据包的源地址为
pod1,目标地址为pod4,它以这种方式离开node1进入电缆。 -
路由表有每个节点的CIDR块的路由设定,它把数据包路由到CIDR块包含
pod4的IP的节点。 -
因此数据包到达了
node2的主网络接口eth0。现在即使pod4不是eth0的IP,数据包也仍然能转发到cni0,因为节点配置了IP forwarding enabled。节点的路由表寻找任意能匹配pod4IP的路由。它发现了cni0是这个节点的CIDR块的目标地址。你可以用route -n命令列出该节点的路由表,它会显示cni0的路由,类型如下:$ route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.2.2 0.0.0.0 UG 100 0 0 ens33 10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1 10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 192.168.2.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33 -
网桥接收了数据包,发送ARP请求,发现目标IP属于
vethyyy。 -
数据包跨过管道对到达
pod4。
3.5 存在的问题
- 不支持pod之间的网络隔离。Flannel的设计思路就是将所有的pod都放在一个大的二层网络中,所以pod之间没有隔离策略
- 设备复杂,效率不高。Flannel模型下有三种设备,数量经过多种设备的封装、解析,会造成传输效率的下降
4、Calico
Calico 是一种容器之间互通的网络方案。在虚拟化平台中,比如 OpenStack、Docker 等都需要实现 workloads 之间互连,但同时也需要对容器做隔离控制,就像在 Internet 中的服务仅开放80端口、公有云的多租户一样,提供隔离和管控机制。而在多数的虚拟化平台实现中,通常都使用二层隔离技术来实现容器的网络,这些二层的技术有一些弊端,比如需要依赖 VLAN、bridge 和隧道等技术,其中 bridge 带来了复杂性,vlan 隔离和 tunnel 隧道则消耗更多的资源并对物理环境有要求,随着网络规模的增大,整体会变得越加复杂。calico通过把 Host 当作 Internet 中的路由器,同时通过BGP协议同步路由,并使用 iptables 来做安全访问策略,最终设计出了 Calico 方案。
实际上,calico项目提供的网络解决方案,与flannel的host-gw模式几乎一样。calico是基于路由表实现容器数据包转发,不同于flannel使用flanneld进行来维护路由表的做法,calico项目使用BGP协议来自动维护整个集群的路由信息。BGP(边界网关协议),是一种自治系统的动态路由发现协议,与其他BGP系统交换网络可达信息。calico最核心的设计思想是把负责的主机当做路由器,直接通过路由转发数据包。
BGP简介
上面黄色部分就是学到的路由表,目标172.17.1.20在路由表显示的是router2,在真实路由表里面是这个路由器的IP,这里就是下一跳,然后从B口出去到达router2的路由器,router2又有路由表,目标172.17.1.20是从A口出去,然后到达二层交换机通过ARP协议获取mac地址去通信,最终到达172.17.1.20机器
BGP实现了路由共享的协议,BGP在calico这里取代了flannel通过进程维护的功能,BGP针对于大规模网络的协议可靠性扩展性远比flannel强的多
BGP用于在大规模的网络当中实现的路由共享的协议,BGP协议在calico这里取代了flanneld进程维护的那种功能。
4.1 Calico特点
适用场景:k8s环境中的pod之间需要隔离
设计思想:Calico 不使用隧道或 NAT 来实现转发,而是巧妙的把所有二三层流量转换成三层流量,并通过 host 上路由配置完成跨 Host 转发。
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
4.2 Calico基本架构
下图是BGP模式下的节点间pod的通信方式:
各个组件解释:
-
Felix:运行在每一台 Host 的 agent 进程,主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等。Felix会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是创建了一个容器等。用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。
-
etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
-
BGP Client(BIRD):Calico 为每一台 Host 部署一个 BGP Client,使用 BIRD 实现,BIRD 是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。在 Calico 的角色是监听 Host 上由 Felix 注入的路由信息,然后通过 BGP 协议广播告诉剩余 Host 节点,从而实现网络互通。
BIRD是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来。
-
BGP Route Reflector:在大型网络规模中,如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。
4.3 Node之间的两种Calico网络模式
-
IPIP
从字面来理解,就是把一个IP数据包又套在一个IP包里,即把 IP 层封装到 IP 层的一个 tunnel。它的作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。
-
BGP
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。BGP,通俗的讲就是讲接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP,BGP 机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统。
4.4 IPIP模式
4.5 BGP模式
4.6 两种网络对比
IPIP网络:
- 流量:tunl0设备封装数据,形成隧道,承载流量。
- 适用网络类型:适用于互相访问的pod不在同一个网段中,跨网段访问的场景。外层封装的ip能够解决跨网段的路由问题。
- 效率:流量需要tunl0设备封装,效率略低
BGP网络:
- 流量:使用路由信息导向流量
- 适用网络类型:适用于互相访问的pod在同一个网段,适用于大型网络。
- 效率:原生hostGW,效率高
4.7 存在问题
-
租户隔离问题
Calico 的三层方案是直接在 host 上进行路由寻址,那么对于多租户如果使用同一个 CIDR 网络就面临着地址冲突的问题。
-
路由规模问题
通过路由规则可以看出,路由规模和 pod 分布有关,如果 pod离散分布在 host 集群中,势必会产生较多的路由项。
-
iptables 规则规模问题
1台 Host 上可能虚拟化十几或几十个容器实例,过多的 iptables 规则造成复杂性和不可调试性,同时也存在性能损耗。
-
跨子网时的网关路由问题
当对端网络不为二层可达时,需要通过三层路由机时,需要网关支持自定义路由配置,即 pod 的目的地址为本网段的网关地址,再由网关进行跨三层转发。
5.Network Policy
提供了基于策略的网络控制,用于隔离应用并减少攻击面。它使用标签选择器模拟传统的分段网络,并通过策略控制他们之间的流量以及来自外部的流量
在使用Network Policy之前,需要注意:
- apiserver需要开启extensions/v1beta1/networkpolicies
- 网络插件要支持Network Policy,如Calico、Romana、Weave Net和trireme等


