目标检测——Yolo系列
时间:2022-09-11 02:00:00
深度学习经典检测方法概述
检测任务中阶段的意义
- One Stage: YOLO系列
输出检测框的左上角和右下角坐标 (x1,y1),(x2,y2)
一个CNN网络回归预测
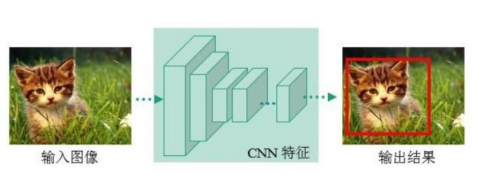
- Two Stage: Faster-rcnn Mask-Rcnn系列
与one-stage 提取候选框(预选)的步骤比较多。
一个比方:
假设公司要招聘一些优秀的人才,one-stage 是直接的海选,two-stage有两层选拔(相当于多了一个淘汰局)。 one-satge 更快的速度适合实时检测任务,two-stage检测效果更好。
测量检测指标
- IOU
IOU 是真实框与预测框之间的交并比
- 准确性和召回率
TP: 被正确(true)判为正样本(positive)的数目 (原来是正样本)
FP: 被错误(false)判为正样本(positive)数量(原来是负样本)
FN: 被错误(true)判为负样本(negative)的数目 (原来是正样本)
TN: 被正确(true)的判为负样本(negative)的数目 (原来是负样本)
Precision: 描述正确的概率
Recall: 描述了找全的概率
一个比方:
假设在做一个多选题,共有6个选项A~F,正确答案是ABCDE, 你选ABF。 答案中只有AB是的,准确率是2/3。CDE没有选择,找全的比例是2/5.
- AP 和mAP
一般来说,精度和回收率不能同时考虑,一个高,另一个相对较低。
改变阈值(IOU如果阈值大于一定阈值,则被判定为正样本),可以获得不同的阈值precision和recall, 然后做出presion - recall 图(一般称为PR图)
去上限求出与x轴围成的阴影面积是AP的值。上图为矩形A1,A2,A3,A4面积之和。
计算每个类别AP,求均值得到mAP
YOLO- V整体思想和网络架构
- 经典的one-stage方法
- You Only Look Once,名字已经说明了一切!
- 将检测问题转化为回归问题,一个接一个CNN就搞定了!
- 可实时检测视频,应用领域广!
核心思想:
输入数据 一张图片 ——> 然后把图片分成7*7的网格——> 然后每个格子对应两个候选框(根据经验获得长宽)——>获得真实值和候选框IOU——> 选择IOU大候选框——> 微调选定候选框的长度和宽度——> 预测框的中心点坐标(x,y),长宽w, h, 还有信心(物体的概率)
- 网络架构
输入图像resize到48483
经过多次卷积得到771024的特征图
然后全连接展开,第一个全连接4096个特征,第二个全连接1470个特征
再通过reshape 得到7730.(每张图片的网格数为7*7.每个格子对应30个特征值,其中30个特征值的前10个是两个候选框的值x,y,w,h,c,后20代表20个分类,即属于每个类别的概率)
x,y,w,h是指归一化后的值,是相对位置和大小
损失函数:
- 非极大值抑制
检测框重叠时选择IOU最大的。
YOLOv1问题
问题1:每个Cell如果重叠不能解决,只预测一个类别
问题2:小物体检测效果一般,长宽比可选但单一
YOLO-V2.详细解释改进细节
改进细节
-
引入 Batch Normalizatioin
V2版本舍弃Dropout(V完全连接时,杀死一些远神经,防止过拟合,V2版本没有全连接层),卷积后全部加入Batch Normalization
网络的每一层输入都是一体化的,收敛相对容易
经过Batch Normalization处理后的网络将增加2%mAP
从目前的角度来看,Batch Normalization已成为网络必备处理 -
分辨率更大
V1训练时使用224224,448448
可能导致模型水土不服,V额外训练10次,448*448 的微调
使用高分辨率分类器后,YOLOv2的mAP提升了约4%
网络结构
- DarkNet实际输入为416*416
- 没有FC(13)*13)
- 1*1卷积累节省了大量参数
5次下采样,长宽缩小2^5=32.
416/32=13 ,除法得到的值最好是奇数,便于找到中心点对应的网格
- 聚类提取先验框
通过聚类得到5个先验框
faster-rcnn的先验框的比例分别是1:1,1:2,2:1,每个比例对应3个不同的size, 所以一共有3*3=9个先验框
- Anchor Box
通过引入anchor boxes,使得预测的box数量更多(1313n)
跟faster-rcnn系列不同的是先验框并不是直接按照长宽固定比给定
- Directed Location Prediction
- 感受野
是特征图上的点能看到原始图像多大区域
感受野越大,越能感受全局的物体。
堆叠两个33的卷积层,感受野是55。
堆叠三个33的卷积层,感受野是77。
为什么采用小卷积核的堆叠而不是直接采用一个大的卷积核来扩大感受野呢?
- 特征融合
最后一层时感受野太大了,小目标可能丢失了,需融合之前的特征。
将最后一层和倒数第二层拆分后拼接在一起。
- 多尺度
YOLOv3核心网络模型
V3最大的改进就是网络结构,使其更适合小目标检测
特征做的更细致,融入多持续特征图信息来预测不同规格物体
先验框更丰富了,3种scale,每种3个规格,一共9种
softmax改进,预测多标签任务
改进之处:
- 多scale
设计大中小三个专门预测不同大小的目标
分别是5252, 2626,13*13(其值越大,候选库框越小),每个BOX代表不同的长宽比。
如下,左图是制作图像金字塔,分别对于不同大小的图片进行预测。但速度较慢。
右图是通过上采样,不同大小的特征图进行融合。
- 残差连接
思想: 只用好的,不好的舍弃,不比原来差。
核心网络架构: darknet53
- 没有池化,因为池化会压缩特征
- 全连接层不实用,在v2中已经去掉
- 下采样通过stride =2实现,图像大小缩小为原来的一半。
- 网格大小有三种
V1 中网格是77
V2中网格是1313
V3中网格是13*13 26*26 52*52
-
先验框的设计
也是通过聚类得到9个先验框。
大的先验框交给1313, 中等交给2626,小的交给52*52。
-
softmax层替代
多标签改进,得到属于每个类别的概率值,大于一定阈值的属于该类别。
YOLOV-3 源码详解
下载地址:
PyTorch-YOLOv3源码下载地址
预训练权重
coco 数据集:
http://images.cocodataset.org/zips/val2014.zip
http://images.cocodataset.org/zips/train2014.zip
参考资料:
yolov3源码解析
https://blog.csdn.net/qq_24739717/article/details/92399359
config 文件夹
- coco.data
classes= 80 # 类别
train=data/coco/trainvalno5k.txt # 训练集图片的存放路径
valid=data/coco/5k.txt # 测试集图片的存放路径
names=data/coco.names # 类别名
backup=backup/ # 记录checkpoint存放位置
eval=coco # 选择map计算方式
- create_custom_model.sh
脚本文件:用户自定义自己的模型,运行此文件用来生成自定义模型的配置文件yolov3-custom.cfg。可对比yolov3.cfg - custom.data
自己数据集的信息,用来训练自己的检测任务:类别数量,训练集路径、验证集路径、类别名称路径 - yolov3.cfg
yolov3网络模型的配置信息:卷积层(卷积核数、卷积核尺寸、步长…)、yolo层及其他层的配置信息。 - yolov3-custom.cfg
自定义的网络模型的配置信息,由create_custom_model.sh脚本文件生成。 - yolov3-tiny.cfg
yolov3的tiny版本网络模型的配置信息。
data 文件夹
coco文件夹
是coco训练集、验证集的数据集,是运行get_coco_dataset.sh脚本文件后的结果。
custom 文件夹
是自定义数据集的信息。
1)images文件夹:所有训练集、验证集的图片。
2)labels文件夹:使用图片标记软件对images文件夹里的图片进行标注得到对应的标签文件。每个标签文件为一个txt文件,txt文件的每一行数据为一个groundthuth信息:类别序号,边界框坐标信息。如图示例,0代表类别索引号,后面为边界框坐标信息
3)classes.names是自定义数据集的类别名称文件。
4)train.txt文件是训练集图片路径的集合,每行数据是训练集某图像的路径。
5)valid.txt文件是验证集图片路径的集合,每行数据是训练集某图片的路径。
samples文件夹
是模型测试图片所在的文件夹,用来看模型的检测结果。
coco.names
coco数据的类别信息,类似classes.names。
get_coco_dataset.sh
脚本文件,用来获取coco数据,生成coco文件夹及其内容。
Utils文件夹
augmentations.py
进行数据增强的文件,本项目只是进行水平翻转的数据增强,图像进行翻转的时候,对应标注信息也进行了修改,最终返回的是翻转后的图片和翻转后的图片对应的标签。
- 导包
import torch
import torch.nn.functional as F
import numpy as np
- horisontal_flip()
输入:image,targets 是原始图像和标签;
返回:images,targets是翻转后的图像和标签。
功能:horisontal_flip() 函数是对图像进行数据增强,使得数据集得到扩充。在此处只采用了对图片进行水平方向上的镜像翻转。
def horisontal_flip(images, targets): #对图像和标签进行镜像翻转
images = torch.flip(images, [-1]) #镜像翻转
targets[:, 2] = 1 - targets[:, 2]
# targets是对应的标签[置信度,中心点高度,中心点宽度,框高度,框宽度]
# 镜像翻转时,受影响的只有targets[:, 2],
return images, targets
torch.flip(input,dims) ->tensor
功能:对数组进行反转
参数: imput 反转的tensor ; dim 反转的维度
返回: 反转后的tensor
由于image 是用数组存储起来的(c,h,w),三个维度分别代表颜色通道,垂直方向,水平方向。python 中[-1] 代表最后一个数,即水平方向。
targets是对应的标签[置信度,中心点高度,中心点宽度,框高度,框宽度], 其中高度宽度都是用相对位置表示的,范围是[0,1]。
datasets.py
对数据集进行操作的py文件,包含图像的填充、图像大小的调整、测试数据集的加载类、评估数据集的加载类。整个文件包含3个函数和2个类,如下
- 导包
import glob
import random
import os
import sys
import numpy as np
from PIL import Image
import torch
import torch.nn.functional as F
from utils.augmentations import horisontal_flip
from torch.utils.data import Dataset
import torchvision.transforms as transforms
- pad_to_square
输入:img 原始图片,pad_value 填充padding的值
输出:padding 后的图片
功能: 将原始的图片添加padding,使之扩充为一个正方形。正方形的边长取max(width,length)。然后采用F.pad函数用常数填充padding
'''图片填充函数: 把图片用pad_value填充成一个正方形,返回填充后的图片以及填充的位置信息'''
def pad_to_square(img, pad_value): # 图片填充为正方形,pad_value:补全部分所填充的数值
c, h, w = img.shape
dim_diff = np.abs(h - w)
# (upper / left) padding and (lower / right) padding
pad1, pad2 = dim_diff // 2, dim_diff - dim_diff // 2
# 填充方式,如果高小于宽则上下填充,如果高大于宽,左右填充
pad = (0, 0, pad1, pad2) if h <= w else (pad1, pad2, 0, 0)
# 图片填充,参数img是原图,pad是填充方式(0,0,pad1,pad2)或(pad1,pad2,0,0),value是填充的值
img = F.pad(img, pad, "constant", value=pad_value)
return img, pad
- resize
输入:image,原始图片; size,期望resize到的图片大小
输出:resize后的图片
功能:实现上/下采样的功能
'''图片调整大小:将正方形图片使用插值方法,改变到固定size大小'''
def resize(image, size):
image = F.interpolate(image.unsqueeze(0), size=size, mode="nearest").squeeze(0) #将原始图片解压后用“nearest”方法进行填充,然后再压缩
return image
pytorch torch.nn.functional.interpolate实现插值和上采样
torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None)参数:
input (Tensor) – 输入张量
size (int or Tuple[int] or Tuple[int, int] or Tuple[int, int, int]) – 输出大小
scale_factor (float or Tuple[float]) – 指定输出为输入的多少倍数。如果输入为tuple,其也要制定为tuple类型
mode (str) – 可使用的上采样算法,有’nearest’, ‘linear’, ‘bilinear’, ‘bicubic’ , ‘trilinear’和’area’. 默认使用’nearest’
- random_resize
输入:image 原始图片, min_size,max_size 随机数所在的范围
输出:调整后的图片
功能:随机调整图片的大小
"""随机裁剪函数:将图片随机裁剪到某个尺寸(使用插值法)"""
def random_resize(images, min_size=288, max_size=448):
new_size = random.sample(list(range(min_size, max_size + 1, 32)), 1)[0]
images = F.interpolate(images, size=new_size, mode="nearest")
return images
- ImageFolder
功能: 用来定义数据集的标准格式。
从文件夹中读取图片,将图片padding成正方形,所有的输入图片大小调整为416*416,返回图片的数量
'''数据集加载类1:加载并处理图片,返回的是图片路径,和经过处理后的图片'''
#用于预测:在detect.py中加载数据集时使用
class ImageFolder(Dataset): # 这是定义数据集的标准格式
def __init__(self, folder_path, img_size=416):#初始化的参数为:测试图片所在的文件夹的路径、图片的尺寸(用于输入到网络的图片的大小)
#获取文件夹下图片的路径,files是图片路径组成的列表
self.files = sorted(glob.glob("%s/*.*" % folder_path))#例在detect.py中folder_path=data/samples
self.img_size = img_size #初始化图片的尺寸
def __getitem__(self, index): #根据索引获取列表里的图片的路径
img_path = self.files[index % len(self.files)]
# 将图片转换为tensor的格式
img = transforms.ToTensor()(Image.open(img_path))
# 用0将图片填充为正方形
img, _ = pad_to_square(img, 0)
# 将图片大小调整为指定大小
img = resize(img, self.img_size)
return img_path, img # 返回 index 对应的图片的 路径和 图片
def __len__(self):
return len(self.files) # 所有图片的数量
- ListDataset
Dataset类:
pytorch读取图片,主要通过Dataset类。Dataset类作为所有datasets的基类,所有的datasets都要继承它
init: 用来初始化一些有关操作数据集的参数
getitem:定义数据获取的方式(包括读取数据,对数据进行变换等),该方法支持从 0 到 len(self)-1的索引。obj[index]等价于obj.getitem
len:获取数据集的大小。len(obj)等价于obj.len()
"""数据集加载类2:加载并处理图片和图片标签,返回的是图片路径,经过处理后的图片,经过处理后的标签"""
#用于评估:在test.py中加载数据集时候使用
class ListDataset(Dataset):
# 数据的载入
def __init__(self, list_path, img_size=416, augment=True, multiscale=True, normalized_labels=True):
#初始化参数:list_path为验证集图片的路径组成的txt文件,的路径、img_size为图片大小(输入到网络中的图片的大小)、augment是否数据增强、multiscale是否使用多尺度,normalized_labels标签是否归一化
#获取验证集图片路径img_files,是一个列表
with open(list_path, "r") as file: #打开valid.txt文件,内容为data/custom/images/train.jpg,指明了验证集对应的图片路径
self.img_files = file.readlines()
# 获取验证集标签路径label_files:是一个列表,根据验证集图片的路径获取标签路径,两者之间是文件夹及后缀名不同,
self.label_files = [
path.replace("images", "labels").replace(".png", ".txt").replace(".jpg", ".txt")
for path in self.img_files
]
#其他设置
self.img_size = img_size
self.max_objects = 100 # 最多目标个数
self.augment = augment # bool. 是否使用增强
self.multiscale = multiscale # bool. 是否多尺度输入,每次喂到网络中的batch中图片大小不固定。
self.normalized_labels = normalized_labels # bool. 默认label.txt文件中的bbox是归一化到0-1之间的
self.min_size = self.img_size - 3 * 32
self.max_size = self.img_size + 3 * 32 # self.min_size和self.max_size的作用主要是经过数据处理后生成三种不同size的图像,目的是让网络对小物体和大物体都有较好的检测结果。
self.batch_count = 0 # 当前网络训练的是第几个batch
#根据下标 index 找到对应的图片,并对图片、标签进行填充,适应于正方形,对标签进行归一化。返回图片路径,图片,标签
def __getitem__(self, index): # 读取数据和标签
# ---------
# Image
# ---------
# 根据索引获取图片的路径
img_path = self.img_files[index % len(self.img_files)].rstrip()
img_path = 'F:\\cv\\PyTorch-YOLOv3\\PyTorch-YOLOv3\\data\\coco' + img_path
# print (img_path)
# 把图片变为tensor
img = transforms.ToTensor()(Image.open(img_path).convert('RGB'))
# 把图片变为三个通道,获取图像的宽和高
if len(img.shape) != 3:
img = img.unsqueeze(0)
img = img.expand((3, img.shape[1:]))
_, h, w = img.shape
h_factor, w_factor = (h, w) if self.normalized_labels else (1, 1) # 如果标注bbox不是归一化的,则标注里面的保存的就是真实位置
#把图片填充为正方形,返回填充后的图片,以及填充的信息 pad = (0, 0, pad1, pad2) if h <= w else (pad1, pad2, 0, 0)
img, pad = pad_to_square(img, 0)
#填充后的高和宽
_, padded_h, padded_w = img.shape
# ---------
# Label
# ---------
#根据索引,获取标签路径
label_path = self.label_files[index % len(self.img_files)].rstrip()
label_path='F:\\cv\\PyTorch-YOLOv3\\PyTorch-YOLOv3\\data\\coco\\labels'+ label_path
#print (label_path)
targets = None
if os.path.exists(label_path): #读取某张图片的标签信息
# 读取一张图片内的边界框:txt文件包含的边界框的坐标信息是归一化后的坐标
boxes = torch.from_numpy(np.loadtxt(label_path).reshape(-1, 5)) # [0class_id, 1x_c, 2y_c, 3w, 4h] 归一化的, 归一化是为了加速模型的收敛
# np.loadtxt()函数主要将标签里的值转化为araray
# 将归一化后的坐标变为适应于原图片的坐标
# 使用(x_c, y_c, w, h)获取真实坐标(左上,右下)
x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2)
y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2)
x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2)
y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2)
# 将坐标变为适应于填充为正方形后图片的坐标
# 标注要和原图做相同的调整 pad(0左,1右,2上,3下)
x1 += pad[0]
y1 += pad[2]
x2 += pad[1]
y2 += pad[3]
# 将边界框的信息转变为(x,y,w,h)形式,并归一化
# (padded_w, padded_h)是当前padding之后图片的宽度
boxes[:, 1] = ((x1 + x2) / 2) / padded_w
boxes[:, 2] = ((y1 + y2) / 2) / padded_h
# (w_factor, h_factor)是原始图的宽高
boxes[:, 3] *= w_factor / padded_w
boxes[:, 4] *= h_factor / padded_h
# #长度为6:(0,类别索引,x,y,w,h)
targets = torch.zeros((len(boxes), 6))
targets[:, 1:] = boxes
# Apply augmentations
if self.augment:
if np.random.random() < 0.5:
img, targets = horisontal_flip(img, targets) #数据增强
return img_path, img, targets #返回index对应的图片路径,填充和调整大小之后的图片,图片标签归一化后的格式 (img_id, class_id, x_c, y_c, w, h)
# collate_fn:实现自定义的batch输出。如何取样本的,定义自己的函数来准确地实现想要的功能,并给target赋予索引
def collate_fn(self, batch):
paths, imgs, targets = list(zip(*batch)) # #获取批量的图片路径、图片、标签
#target的每个元素为每张图片的所有边界框的信息
targets = [boxes for boxes in targets if boxes is not None]
#读取target的每个元素,每个元素为一张图片的所有边界框信息,并微每张图片的边界框标相同的序号
for i, boxes in enumerate(targets):
boxes[:, 0] = i #为每个边界框增加索引,序号
targets = torch.cat(targets, 0) # 直接将一个batch中所有的bbox合并在一起,计算loss时是按batch计算
# Selects new image size every tenth batch
if self.multiscale and self.batch_count % 10 == 0:
self.img_size = random.choice(range(self.min_size, self.max_size + 1, 32))
# Resize images to input shape
# 每10个样本随机调整图像大小
imgs = torch.stack([resize(img, self.img_size) for img in imgs]) # 调整图像大小放入栈中
self.batch_count += 1
return paths, imgs, targets # 返回归一化后的[img_id, class_id, x_c, y_c, h, w]
def __len__(self):
return len(self.img_files)
logger.py
用来将监控数据写入文件系统(日志),保存训练的某些信息。如损失等。这个logger类在train.py中使用,在训练过程中保存一些信息到日志文件。
import tensorflow as tf
class Logger(object):
def __init__(self, log_dir): #log_dir 是日志的路径
"""Create a summary writer logging to log_dir."""
self.writer = tf.summary.create_file_writer(log_dir) #创建一个summary writer
# 由于版本问题,tf.summary.FileWriter可能会报错,改为tf.compat.v1.summary.FileWriter
def scalar_summary(self, tag, value, step): # 记录a scalar variable
with self.writer.as_default():
tf.summary.scalar(tag, value, step=step)
self.writer.flush()
def list_of_scalars_summary(self, tag_value_pairs, step):
with self.writer.as_default():
for tag, value in tag_value_pairs:
tf.summary.scalar(tag, value, step=step)
self.writer.flush()
# summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value) for tag, value in tag_value_pairs])
# self.writer.add_summary(summary, step)
parse_config.py
包含两个解析器:
1.模型配置解析器:返回一个列表model_defs,列表的每一个元素为一个字典,字典代表模型某一个层(模块)的信息 。
2.数据配置解析器:返回一个字典,每一个键值对描述了,数据的名称路径,或其他信息。
'''模型配置解析器:解析yolo-v3层配置文件函数,并返回模块定义module_defs,path就是yolov3.cfg路径''' def parse_model_config(path): ''' 看此函数,一定要先看config文件夹下的yolov3.cfg文件,如下是yolov3。cfg的一部分内容展示: [convolutional] batch_normalize=1 filters=32 size=3 stride=1 pad=1 activation=leaky # Downsample [convolutional] batch_normalize=1 filters=64 size=3 stride=2 pad=1 activation=leaky 。。。 :param path: 模型配置文件路径,yolov3.cfg的路径 :return: 模型定义,列表类型,列表中的元素是字典,字典包含了每一个模块的定义参数 ''' # 打开yolov3.cfg文件,并将文件内容存入列表,列表的每一个元素为文件的一行数据。 file = open(path, 'r') lines = file.read


