2021-03-12 16个车辆信息检测数据集收集汇总
时间:2023-05-29 08:07:00
收集和总结16辆车辆的信息检测数据
1. UA-DETRAC
http://detrac-db.rit.albany.edu/
UA-DETRAC多目标检测和多目标跟踪基准在现实世界中具有挑战性。数据集由 Cannon EOS 550D在中国北京和天津24个不同地点拍摄的10小时视频。视频以每秒25帧的速度录制,分辨率为960540像素。在UA-DETRAC数据集中,有超过14万帧和8250辆车被人工标注,总共标记了121万物体的边界盒。我们还对最新的目标检测和多目标跟踪方法进行基准测试,以及本网站详细介绍的评估指标。
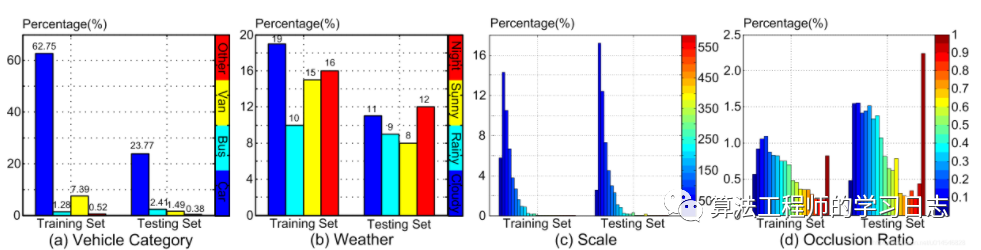
车辆分为四类,即共汽车、货车等四类。
天气分为多云、夜间、晴天和雨天四类。
标记的车辆的尺寸被定义为其像素面积的平方根。车辆分为小型(0-50像素)、中型(50-150像素)和大型(大于150像素)三种规模。屏蔽程度由我们使用车辆外壳的比例来定义。
遮挡程度分为三类: 无遮挡、部分遮挡、重遮挡。具体来说,部分遮挡(如果车辆遮挡率在1%-50%之间)和重遮挡(如果遮挡率大于50%)是定义的。
截尾率是指车辆部件在帧外的程度,用于选择训练样本。
效果图:
2. BDD100K 自动驾驶数据集
https://bdd-data.berkeley.edu/
视频数据:一万多个高清视频序列超过100小时,在一天中有许多不同的时间、天气条件和驾驶场景驾驶经验。视频序列还包括GPS位置、IMU数据和时间戳。
道路目标检测:2D公交车、交通灯、交通标志、人、自行车、卡车、摩托车、汽车、火车、汽车、火车、骑手等1万张图片。
实例分割:有10000多具有像素级和丰富实例级注释的不同图像。
引擎区域:从10万张图片中学习复杂的可驾驶决策。
车道标志:10万张图片上的多种车道标志用于引导驾驶。
如图:
3. 综合汽车(CompCars)数据集
http://mmlab.ie.cuhk.edu.hk/datasets/comp_cars/index.html
该数据集在 CVPR 在2015年的论文中,Linjie Yang, Ping Luo, Chen Change Loy, Xiaoou Tang. A Large-Scale Car Dataset for Fine-Grained Categorization and Verification, In Computer Vision and Pattern Recognition (CVPR), 2015. PDF。
综合汽车(CompCars)数据集包括来自两个场景的数据,包括来自两个场景的数据web-nature和监视-nature的图像。
web-nature数据包括163辆车和1716辆车。总共有136726个图像捕捉整辆车,27618个图像捕捉汽车零部件。完整的汽车图像被标记为边界框和视图。每个模型都有五个属性,包括最大速度、排水量、门数、座椅数和模型。
监控-自然数据包含前视图捕视图捕获的汽车图像。
该数据集准备了以下计算机视觉任务:细粒度分类、属性预测和汽车模型验证。
本文介绍的这些任务的培训/测试子集包含在数据集中。研究人员也欢迎使用它来完成图像排序、多任务学习和3等其他任务D重建。
4. Stanford Cars Dataset
http://ai.stanford.edu/~jkrause/cars/car_dataset.html
Cars数据集包括196类汽车的16、185个图像。将数据分为8144个训练图像和8041个测试图像,大致分为50-50个类别。等级通常根据制造、型号和年份进行划分,如2012年特斯拉Model S或2012年宝马M3 coupe。
5. OpenData V11.0-车辆别数据集 VRID
http://www.openits.cn/opendata4/748.jhtml
说明:数据集:
车辆重新识别的数据来自一个城市的卡口车辆图像,由326个高清摄像头拍摄,覆盖14天,分辨率400×424到990×1134不等。数据集中包含10种最常见的车型,共1万张图像,如表1所列。为了模拟同一车辆对车辆重新识别的影响,每辆车有100辆不同的车辆ID,也就是说,100辆不同的车辆。同一车型的100辆车ID,它们的外观几乎相同,大部分差异只在于窗户的个性化标志,如年检标志。另外,每辆车ID它包含10张图像。这10张图像是在不同的路口拍摄的。光线、规模和姿势不同。相应的车辆也可能有不同的外观。
车辆重识别数据集的车辆字段属性如表2所示,其中车辆品牌表示车辆品牌信息,车牌号用于数据库中同一车辆的关联,车窗位置代表图像中车窗所在区域的坐标,车身颜色表示图像中的车辆颜色信息。这些信息使得数据库不仅可以用于车辆重识别研究,还可以用于车辆品牌的精细识别和车辆颜色识别。
数据集中有10种车,车型ID图像数据1000张
数据库属性示意表
6. N-CARS数据集
https://www.prophesee.ai/dataset-n-cars/
N-CARS数据集是一个基于汽车分类事件的大型真实世界数据集。
它由1236个汽车样本和11693个非汽车样本(背景)组成。这些数据安装在汽车挡风玻璃后面ATIS摄像机记录下来。这些数据是从不同的驾驶过程中提取的。数据集分为7940个car背景训练样本7482个,4396个 car 还有4211个背景测试样本。每个示例持续100毫秒。
7. MIT DriveSeg Dataset
https://agelab.mit.edu/driveseg
到目前为止,研究社区提供的自动驾驶数据主要由静态和单一的图像组成,可以使用边界框识别和跟踪道路和周围的常见物体,如自行车、行人或交通灯。相比之下,DriveSeg通过连续视频驾驶场景的镜头,包含更准确、像素级的常见道路物体的表示。这种类型的全场景分割特别有助于识别更多的无定形物体,如道路建设和植被,它们并不总是有如此清晰和统一的形状。数据集由两部分组成:
DriveSeg(手动)
前帧像素级语义标记数据集是从一辆在连续阳光下通过拥挤的城市街道行驶的移动车辆中捕获的。
技术摘要
视频数据:2分47秒(5000帧)1080P (1920x1080) 30帧/秒
类别定义(12):车辆、行人、道路、人行道、自行车、摩托车、建筑物、地形(水平植被)、植被(垂直植被)、杆子、交通灯和交通标志
8. KITTI
· 数据集链接:http://www.cvlibs.net/datasets/kitti/
· 论文链接:
http://www.webmail.cvlibs.net/publications/Geiger2012CVPR.pdf
地面真相的准确原因Velodyne激光扫描仪和GPS提供定位系统。我们的数据集是在中型城市卡尔斯鲁厄(Karlsruhe)、在农村地区和高速公路上行驶。多达15辆车和30名行人可以在每张图片中看到。除了以原始格式提供所有数据外,我们还为每个任务提取基准。我们还为我们的每一个基准提供了一个评估指标和一个评估网站。初步实验表明,在现有基准中排名靠前的方法,如Middlebury离开实验室进入现实世界后,方法表现低于平均水平。我们的目标是减少这种偏见,并通过为社会提供新的困难来补充现有的基准。
9. CityScapes
· 数据集链接:https://www.cityscapes-dataset.com/
· 论文链接:https://arxiv.org/pdf/1604.01685.pdf
它提供了一个新的大规模数据集,包括记录在50个不同城市街道场景中的不同三维视频序列,包括5000帧的高质量像素级注释和20000帧的大型弱注释。因此,数据集比以前的类似尝试更大有关注释类的详细资料及注释示例可在此网页查阅。Cityscapes数据集旨在评估用于语义城市场景理解的主要任务的视觉算法的性能:像素级、实例级和全光学语义标记;支持旨在开发大量(弱)注释数据的研究,例如用于训练深度神经网络。
10. Comma.ai 's Driving Dataset
· 数据集链接:https://github.com/commaai/research
· 论文链接:https://arxiv.org/pdf/1608.01230.pdf
目的是低成本的自动驾驶方案,目前是通过手机改装来做自动驾驶,开源的数据包含7小时15分钟分为11段的公路行驶的行车记录仪视频数据,每帧像素为160x320。主要应用方向:图像识别;
11. Udacity 's Driving Dataset
· 数据集链接:https://github.com/udacity/self-driving-car/tree/master/datasets
· 论文链接:未找到
Udacity的自动驾驶数据集,使用Point Grey研究型摄像机拍摄的1920x1200分辨率的图片,采集到的数据分为两个数据集:第一个包括在白天情况下在加利福尼亚州山景城和邻近城市采集的数据,数据集包含9,423帧中超过65,000个标注对象,标注方式结合了机器和人工。标签为:汽车、卡车、行人;第二个数据集与前者大体上相似,除了增加交通信号灯的标注内容,数据集数量上也增加到15,000帧,标注方式完全采用人工。数据集内容除了有车辆拍摄的图像,还包含车辆本身的属性和参数信息,例如经纬度、制动器、油门、转向度、转速。主要应用方向:目标检测,自动驾驶;
12. D²-City
· 数据集链接:https://outreach.didichuxing.com/d2city/
背景
D²-City 是一个大规模行车视频数据集,提供了超过一万段行车记录仪记录的前视视频数据。所有视频均以高清(720P)或超高清(1080P)分辨率录制。我们为其中的约一千段视频提供了包括目标框位置、目标类别和追踪ID信息的逐帧标注,涵盖了共12类行车和道路相关的目标类别。我们为一部分其余的视频提供了关键帧的框标注。
和现有类似数据集相比,D²-City 的数据采集自中国多个城市,涵盖了不同的天气、道路、交通状况,尤其是极复杂和多样性的交通场景。我们希望通过该数据集能够鼓励和帮助自动驾驶相关领域研究取得新进展。
数据集介绍
D²-City 数据集采集自运行在中国五个城市的滴滴运营车辆。所提供的原始数据均存储为帧率25fps、时长30秒的短视频。后续我们将会提供对该数据集的训练、验证和测试集的划分与统计。
我们为其中约一千段视频提供了12类目标的边界框和追踪ID标注信息,对其他的视频,我们提供关键帧的框标注。类别信息详见下表。
评估任务
基于本数据集,我们将提供一项评估任务(和BDD合作)作为NeurIPS 2019 ML4AD挑战赛的赛事。任务和评估的详情请参见竞赛网站相关页面。
赛事:D²-City & BDD100K 目标检测迁移学习挑战赛 在目标检测迁移学习挑战赛中,参赛者需要利用采集自美国的BDD100K数据,训练目标检测模型用于采集自中国的D²-City数据。数据集中可能包含稀有或有挑战性的状况下采集的数据,如光线不足、雨雾天气、道路拥堵等,参赛者需要提供在各状况下准确的目标检测结果。
13. ApolloScape
· 数据集链接:http://apolloscape.auto/inpainting.html
关于ApolloScape数据集
轨迹数据集,三维感知激光雷达目标检测和跟踪数据集,包括约100K图像帧,80k激光雷达点云和1000km城市交通轨迹。数据集由不同的条件和交通密度,其中包括许多具有挑战性的场景,车辆,自行车,和行人之间移动。
数据集包括以下几个方面的研究:
Scene Parsing
3D Car Instance
Lane Segmentation
Self Localization
Trajectory
Stereo
Inpainting
14. nuScenes
· 数据集链接:https://www.nuscenes.org/
nuScenes数据集是一个具有3d对象标注的大规模自主驾驶数据集。它特点:
-
1000 scenes of 20s each
-
1400000相机图像
-
390000激光雷达扫描
-
两个不同的城市:波士顿和新加坡
-
左派和右手交通详细的地图信息
-
1.4M 3D 边界盒手工注释等,23个对象类
-
属性可见性、活动和姿势
新: 1.1B 激光雷达点手工注释为32类
新: 探索nuScenes在SiaSearch免费使用非商业用途
15. 牛津Robotcar数据集
https://robotcar-dataset.robots.ox.ac.uk/
牛津机器人车数据集包含了超过100次在英国牛津的同一路线的重复,采集时间超过一年。数据集捕捉了天气、交通和行人的许多不同组合,以及建筑和道路工程等长期变化。
16. Vehicle Image Database
http://www.gti.ssr.upm.es/data/Vehicle_database.html?spm=5176.100239.0.0.XGJd1k
图像处理组目前正在研究基于视觉的车辆分类任务。为了评估我们的方法,我们创建了一个新的图像数据库,这些图像是从我们的视频序列中提取的(通过安装在车辆上的向前看的摄像机获取)。该数据库包括3425张从不同角度拍摄的车辆尾部图像,以及3900张从不包含车辆的道路序列中提取的图像。选择图像是为了最大化vehicle类的代表性,这涉及到自然的高可变性。在我们看来,影响车辆后部外观的一个重要特征是车辆相对于摄像机的位置。因此,数据库根据姿态将图像划分为四个不同的区域:镜头前的中/近距离,左侧的中/近距离,右侧的近/中距离,以及远距离。此外,为了使分类器在假设生成阶段对偏移量具有更强的鲁棒性,我们提取的图像不能很好地贴合车辆的轮廓。相反,一些图像松散地包含了车辆(一些背景也包含在图像中),而其他图像只包含部分车辆。对同一运载工具的多个实例分别给出了不同的边界假设。这些图像的分辨率为64x64,是从马德里、布鲁塞尔和都灵的高速公路上记录的360x256像素序列中裁剪出来的。
附:交通标志数据集
1)KUL Belgium Traffic Sign Dataset,比利时的一个交通标志数据集。
2)German Traffic Sign,德国交通标注数据集。
3)STSD,超过20 000张带有20%标签的图像,包含3488个交通标志。
4)LISA,超过6610帧上的7855条标注。
5)Tsinghua-Tencent 100K ,腾讯和清华合作的数据集,100000张图片,包含30000个交通标志实例。